CS229 讲义(备份版)
第一章
监督学习(Supervised learning)
咱们先来聊几个使用监督学习来解决问题的实例。假如咱们有一个数据集,里面的数据是俄勒冈州波特兰市的 $47$ 套房屋的面积和价格:
| 居住面积(平方英尺) | 价格(千美元) |
|---|---|
| $2104$ | $400$ |
| $1600$ | $330$ |
| $2400$ | $369$ |
| $1416$ | $232$ |
| $3000$ | $540$ |
| $\vdots$ | $\vdots$ |
用这些数据来投个图:
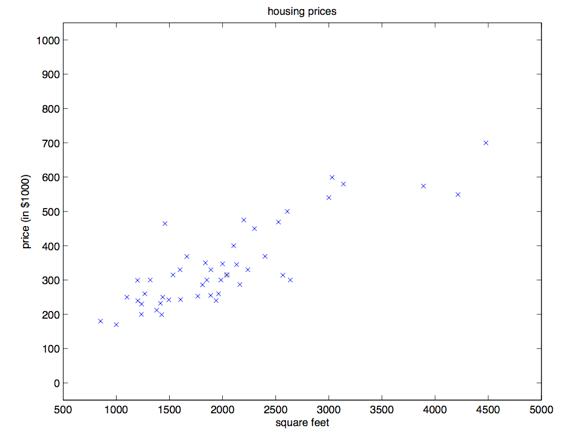
有了这样的数据,我们怎样才能学会预测波特兰其他房屋的价格,以及它们的居住面积?
这里要先规范一下符号和含义,这些符号以后还要用到,咱们假设 $x^{(i)}$ 表示 “输入的” 变量值(在这个例子中就是房屋面积),也可以叫做输入特征;然后咱们用 $y^{(i)}$ 来表示“输出值”,或者称之为目标变量,这个例子里面就是房屋价格。这样的一对 $(x^{(i)},y^{(i)})$就称为一组训练样本,然后咱们用来让机器来学习的数据集,就是——一个长度为 $m$ 的训练样本的列表${(x^{(i)},y^{(i)}); i = 1,\dots ,m}$——也叫做一个训练集。另外一定注意,这里的上标$(i)$只是作为训练集的索引记号,和数学乘方没有任何关系,千万别误解了。另外我们还会用大写的$X$来表示 输入值的空间,大写的$Y$表示输出值的空间。在本节的这个例子中,输入输出的空间都是实数域,所以 $X = Y = R$。
然后再用更加规范的方式来描述一下监督学习问题,我们的目标是,给定一个训练集,来让机器学习一个函数 $h: X → Y$,让 $h(x)$ 是一个与对应的真实 $y$ 值比较接近的评估值。由于一些历史上的原因,这个函数 $h$ 就被叫做假设(hypothesis)。用一个图来表示的话,这个过程大概就是下面这样:
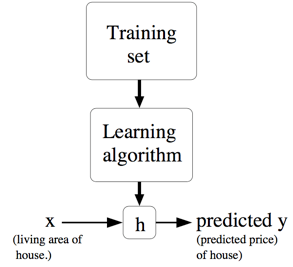
如果我们要预测的目标变量是连续的,比如在咱们这个房屋价格-面积的案例中,这种学习问题就被称为回归问题。 如果$y$只能取一小部分的离散的值(比如给定房屋面积,咱们要来确定这个房子是一个住宅还是公寓),这样的问题就叫做分类问题。
第一部分 线性回归
为了让我们的房屋案例更有意思,咱们稍微对数据集进行一下补充,增加上每一个房屋的卧室数目:
| 居住面积(平方英尺) | 卧室数目 | 价格(千美元) |
|---|---|---|
| $2104$ | $3$ | $400$ |
| $1600$ | $3$ | $330$ |
| $2400$ | $3$ | $369$ |
| $1416$ | $2$ | $232$ |
| $3000$ | $4$ | $540$ |
| $\vdots$ | $\vdots$ | $\vdots$ |
现在,输入特征 $x$ 就是在 $R^2$ 范围取值的一个二维向量了。例如 $x_1^{(i)}$ 就是训练集中第 $i$ 个房屋的面积,而 $x_2^{(i)}$ 就是训练集中第 $i$ 个房屋的卧室数目。(通常来说,设计一个学习算法的时候,选择哪些输入特征都取决于你,所以如果你不在波特兰收集房屋信息数据,你也完全可以选择包含其他的特征,例如房屋是否有壁炉,卫生间的数量啊等等。关于特征筛选的内容会在后面的章节进行更详细的介绍,不过目前来说就暂时先用给定的这两个特征了。)
要进行这个监督学习,咱们必须得确定好如何在计算机里面对这个函数/假设 $h$ 进行表示。咱们现在刚刚开始,就来个简单点的,咱们把 $y$ 假设为一个以 $x$ 为变量的线性函数:
$$
h_\theta (x) = \theta_0 + \theta_1 \times x_1 + \theta_2 \times x_2
$$
这里的$\theta_i$是参数(也可以叫做权重),是从 $x$ 到 $y$ 的线性函数映射的空间参数。在不至于引起混淆的情况下,咱们可以把$h_\theta(x)$ 里面的 $\theta$ 省略掉,就简写成 $h(x)$。另外为了简化公式,咱们还设 $x_0 = 1$(这个为 截距项 intercept term)。这样简化之后就有了:
$$
h(x) = \sum^n_{i=0} \theta_i x_i = \theta^T x
$$
等式最右边的 $\theta$ 和 $x$ 都是向量,等式中的 $n$ 是输入变量的个数(不包括$x_0$)。
现在,给定了一个训练集,咱们怎么来挑选/学习参数 $\theta$ 呢?一个看上去比较合理的方法就是让 $h(x)$ 尽量逼近 $y$,至少对咱已有的训练样本能适用。用公式的方式来表示的话,就要定义一个函数,来衡量对于每个不同的 $\theta$ 值,$h(x^{(i)})$ 与对应的 $y^{(i)}$ 的距离。这样用如下的方式定义了一个 成本函数 (cost function):
$$
J(\theta) = \frac 12 \sum^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2
$$
如果之前你接触过线性回归,你会发现这个函数和常规最小二乘法 拟合模型中的最小二乘法成本函数非常相似。不管之前接触过没有,咱们都接着往下进行,以后就会发现这是一个更广泛的算法家族中的一个特例。
1 最小均方算法(LMS algorithm)
我们希望选择一个能让 $J(\theta)$ 最小的 $\theta$ 值。怎么做呢,咱们先用一个搜索的算法,从某一个对 $\theta$ 的“初始猜测值”,然后对 $\theta$ 值不断进行调整,来让 $J(\theta)$ 逐渐变小,最好是直到我们能够达到一个使 $J(\theta)$ 最小的 $\theta$。具体来说,咱们可以考虑使用梯度下降法(gradient descent algorithm),这个方法就是从某一个 $\theta$ 的初始值开始,然后逐渐重复更新:$^1$
$$
\theta_j := \theta_j - \alpha \frac \partial {\partial\theta_j}J(\theta)
$$
(上面的这个更新要同时对应从 $0$ 到 $n$ 的所有$j$ 值进行。)这里的 $\alpha$ 也称为学习速率。这个算法是很自然的,逐步重复朝向 $J$ 降低最快的方向移动。
1 本文中 $:= $ 表示的是计算机程序中的一种赋值操作,是把等号右边的计算结果赋值给左边的变量,$a := b$ 就表示用 $b$ 的值覆盖原有的$a$值。要注意区分,如果写的是 $a == b$ 则表示的是判断二者相等的关系。(译者注:在 Python 中,单个等号 $=$ 就是赋值,两个等号 $==$ 表示相等关系的判断。)
要实现这个算法,咱们需要解决等号右边的导数项。首先来解决只有一组训练样本 $(x, y)$ 的情况,这样就可以忽略掉等号右边对 $J$ 的求和项目了。公式就简化下面这样:
$$
\begin{aligned}
\frac \partial {\partial\theta_j}J(\theta) & = \frac \partial {\partial\theta_j} \frac 12(h_\theta(x)-y)^2\
& = 2 \cdot\frac 12(h_\theta(x)-y)\cdot \frac \partial {\partial\theta_j} (h_\theta(x)-y) \
& = (h_\theta(x)-y)\cdot \frac \partial {\partial\theta_j}(\sum^n_{i=0} \theta_ix_i-y) \
& = (h_\theta(x)-y) x_j
\end{aligned}
$$
对单个训练样本,更新规则如下所示:
$$
\theta_j := \theta_j + \alpha (y^{(i)}-h_\theta (x^{(i)}))x_j^{(i)}
$$
这个规则也叫 LMS 更新规则 (LMS 是 “least mean squares” 的缩写,意思是最小均方),也被称为 Widrow-Hoff 学习规则。这个规则有几个看上去就很自然直观的特性。例如,更新的大小与$(y^{(i)} − h_\theta(x^{(i)}))$成正比;另外,当我们遇到训练样本的预测值与 $y^{(i)}$ 的真实值非常接近的情况下,就会发现基本没必要再对参数进行修改了;与此相反的情况是,如果我们的预测值 $h_\theta(x^{(i)})$ 与 $y^{(i)}$ 的真实值有很大的误差(比如距离特别远),那就需要对参数进行更大地调整。
当只有一个训练样本的时候,我们推导出了 LMS 规则。当一个训练集有超过一个训练样本的时候,有两种对这个规则的修改方法。第一种就是下面这个算法:
$
\begin{aligned}
&\qquad 重复直到收敛 { \
&\qquad\qquad\theta_j := \theta_j + \alpha \sum^m_{i=1}(y^{(i)}-h_\theta (x^{(i)}))x_j^{(i)}\quad(对每个j) \
&\qquad}
\end{aligned}
$
读者很容易能证明,在上面这个更新规则中求和项的值就是$\frac {\partial J(\theta)}{\partial \theta_j}$ (这是因为对 $J$ 的原始定义)。所以这个更新规则实际上就是对原始的成本函数 $J $进行简单的梯度下降。这一方法在每一个步长内检查所有整个训练集中的所有样本,也叫做批量梯度下降法(batch gradient descent)。这里要注意,因为梯度下降法容易被局部最小值影响,而我们要解决的这个线性回归的优化问题只能有一个全局的而不是局部的最优解;因此,梯度下降法应该总是收敛到全局最小值(假设学习速率 $\alpha$ 不设置的过大)。$J$ 很明确是一个凸二次函数。下面是一个样例,其中对一个二次函数使用了梯度下降法来找到最小值。
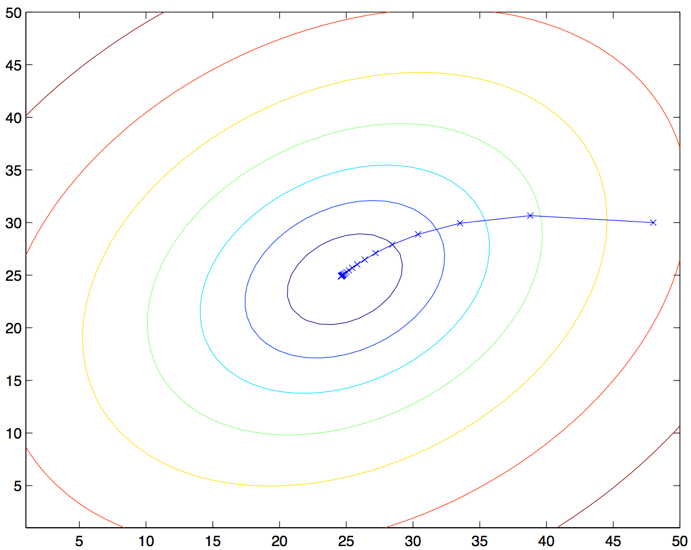
上图的椭圆就是一个二次函数的轮廓图。图中还有梯度下降法生成的规矩,初始点位置在$(48,30)$。图中的画的 $x$ (用直线连接起来了)标记了梯度下降法所经过的 $\theta$ 的可用值。
对咱们之前的房屋数据集进行批量梯度下降来拟合 $\theta$ ,把房屋价格当作房屋面积的函数来进行预测,我们得到的结果是 $\theta_0 = 71.27, \theta_1 = 0.1345$。如果把 $h_{\theta}(x)$ 作为一个定义域在 $x$ 上的函数来投影,同时也投上训练集中的已有数据点,会得到下面这幅图:
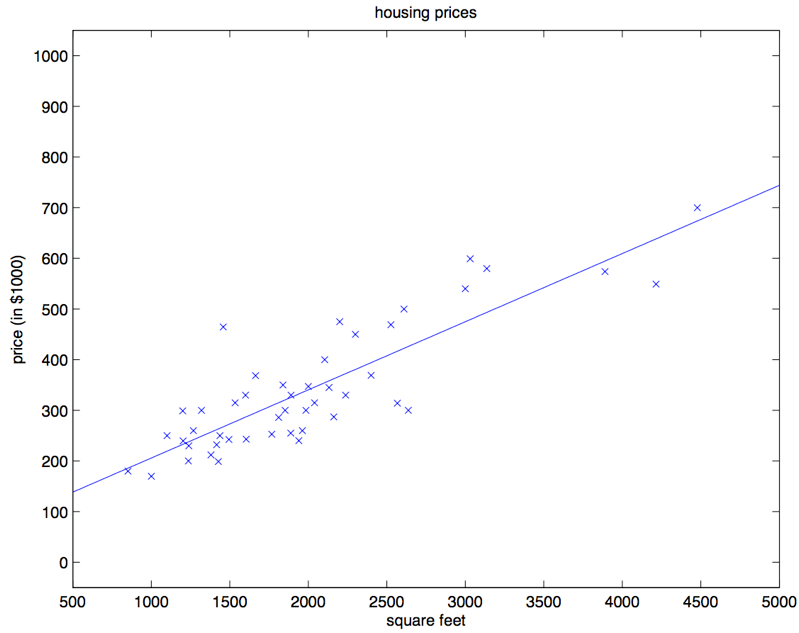
如果在数据集中添加上卧室数目作为输入特征,那么得到的结果就是 $\theta_0 = 89.60, \theta_1 = 0.1392, \theta_2 = −8.738$
这个结果就是用批量梯度下降法来获得的。此外还有另外一种方法能够替代批量梯度下降法,这种方法效果也不错。如下所示:
$
\begin{aligned}
&\qquad循环:{ \
&\qquad\qquad i从1到m,{ \
&\qquad\qquad\qquad\theta_j := \theta_j +\alpha(y^{(i)}-h_{\theta}(x^{(i)}))x_j^{(i)} \qquad(对每个 j) \
&\qquad\qquad} \
&\qquad}
\end{aligned}
$
在这个算法里,我们对整个训练集进行了循环遍历,每次遇到一个训练样本,根据每个单一训练样本的误差梯度来对参数进行更新。这个算法叫做随机梯度下降法(stochastic gradient descent),或者叫增量梯度下降法(incremental gradient descent)。批量梯度下降法要在运行第一步之前先对整个训练集进行扫描遍历,当训练集的规模 $m$ 变得很大的时候,引起的性能开销就很不划算了;随机梯度下降法就没有这个问题,而是可以立即开始,对查询到的每个样本都进行运算。通常情况下,随机梯度下降法查找到足够接近最低值的 $\theta$ 的速度要比批量梯度下降法更快一些。(也要注意,也有可能会一直无法收敛(converge)到最小值,这时候 $\theta$ 会一直在 $J(\theta)$ 最小值附近震荡;不过通常情况下在最小值附近的这些值大多数其实也足够逼近了,足以满足咱们的精度要求,所以也可以用。$^2$)由于这些原因,特别是在训练集很大的情况下,随机梯度下降往往比批量梯度下降更受青睐。
2 当然更常见的情况通常是我们事先对数据集已经有了描述,并且有了一个确定的学习速率$\alpha$,然后来运行随机梯度下降,同时逐渐让学习速率 $\alpha$ 随着算法的运行而逐渐趋于 $0$,这样也能保证我们最后得到的参数会收敛到最小值,而不是在最小值范围进行震荡。(译者注:由于以上种种原因,通常更推荐使用的都是随机梯度下降法,而不是批量梯度下降法,尤其是在训练用的数据集规模大的时候。)
2 法方程(The normal equations)
上文中的梯度下降法是一种找出 $J$ 最小值的办法。然后咱们聊一聊另一种实现方法,这种方法寻找起来简单明了,而且不需要使用迭代算法。这种方法就是,我们直接利用找对应导数为 $0$ 位置的 $\theta_j$,这样就能找到 $J$ 的最小值了。我们想实现这个目的,还不想写一大堆代数公式或者好几页的矩阵积分,所以就要介绍一些做矩阵积分的记号。
2.1 矩阵导数(Matrix derivatives)
假如有一个函数 $f: R^{m\times n} → R$ 从 $m\times n$ 大小的矩阵映射到实数域,那么就可以定义当矩阵为 $A$ 的时候有导函数 $f$ 如下所示:
$$
\nabla_A f(A)=\begin{bmatrix} \frac {\partial f}{\partial A_{11}} & \dots & \frac {\partial f}{\partial A_{1n}} \ \vdots & \ddots & \vdots \ \frac {\partial f}{\partial A_{m1}} & \dots & \frac {\partial f}{\partial A_{mn}} \ \end{bmatrix}
$$
因此,这个梯度 $\nabla_A f(A)$本身也是一个 $m\times n$ 的矩阵,其中的第 $(i,j)$ 个元素是 $\frac {\partial f}{\partial A_{ij}} $ 。
假如 $ A =\begin{bmatrix} A_{11} & A_{12} \ A_{21} & A_{22} \ \end{bmatrix} $ 是一个 $2\times 2$ 矩阵,然后给定的函数 $f:R^{2\times 2} → R$ 为:
$$
f(A) = \frac 32A_{11}+5A^2_{12}+A_{21}A_{22}
$$
这里面的 $A_{ij}$ 表示的意思是矩阵 $A$ 的第 $(i,j)$ 个元素。然后就有了梯度:
$$
\nabla A f(A) =\begin{bmatrix} \frac 32 & 10A{12} \ A_{22} & A_{21} \ \end{bmatrix}
$$
然后咱们还要引入 $trace$ 求迹运算,简写为 $“tr”$。对于一个给定的 $n\times n$ 方形矩阵 $A$,它的迹定义为对角项和:
$$
trA = \sum^n_{i=1} A_{ii}
$$
假如 $a$ 是一个实数,实际上 $a$ 就可以看做是一个 $1\times 1$ 的矩阵,那么就有 $a$ 的迹 $tr a = a$。(如果你之前没有见到过这个“运算记号”,就可以把 $A$ 的迹看成是 $tr(A)$,或者理解成为一个对矩阵 $A$ 进行操作的 $trace$ 函数。不过通常情况都是写成不带括号的形式更多一些。)
如果有两个矩阵 $A$ 和$B$,能够满足 $AB$ 为方阵,$trace$ 求迹运算就有一个特殊的性质: $trAB = trBA$ (自己想办法证明)。在此基础上进行推论,就能得到类似下面这样的等式关系:
$$
trABC=trCAB=trBCA \
trABCD=trDABC=trCDAB=trBCDA
$$
下面这些和求迹运算相关的等量关系也很容易证明。其中 $A$ 和 $B$ 都是方形矩阵,$a$ 是一个实数:
$$
trA=trA^T \
tr(A+B)=trA+trB \
tr a A=a trA
$$
接下来咱们就来在不进行证明的情况下提出一些矩阵导数(其中的一些直到本节末尾才用得上)。另外要注意等式$(4)$中的$A$ 必须是非奇异方阵(non-singular square matrices),而 $|A|$ 表示的是矩阵 $A$ 的行列式。那么我们就有下面这些等量关系:
$$
\begin{aligned}
\nabla_A tr AB & = B^T & \text{(1)}\
\nabla_{A^T} f(A) & = (\nabla_{A} f(A))^T &\text{(2)}\
\nabla_A tr ABA^TC& = CAB+C^TAB^T &\text{(3)}\
\nabla_A|A| & = |A|(A^{-1})^T &\text{(4)}\
\end{aligned}
$$
为了让咱们的矩阵运算记号更加具体,咱们就详细解释一下这些等式中的第一个。假如我们有一个确定的矩阵 $B \in R^{n\times m}$(注意顺序,是$n\times m$,这里的意思也就是 $B$ 的元素都是实数,$B$ 的形状是 $n\times m$ 的一个矩阵),那么接下来就可以定义一个函数$ f: R^{m\times n} → R$ ,对应这里的就是 $f(A) = trAB$。这里要注意,这个矩阵是有意义的,因为如果 $A \in R^{m\times n} $,那么 $AB$ 就是一个方阵,是方阵就可以应用 $trace$ 求迹运算;因此,实际上 $f$ 映射的是从 $R^{m\times n} $ 到实数域 $R$。这样接下来就可以使用矩阵导数来找到 $\nabla_Af(A)$ ,这个导函数本身也是一个 $m \times n $的矩阵。上面的等式$(1)$ 表明了这个导数矩阵的第 $(i,j)$个元素等同于 $B^T$ ($B$的转置)的第 $(i,j)$ 个元素,或者更直接表示成 $B_{ji}$。
上面等式$(1-3)$ 都很简单,证明就都留给读者做练习了。等式$(4)$需要用逆矩阵的伴随矩阵来推导出。$^3$
3 假如咱们定义一个矩阵 $A’$,它的第 $(i,j)$ 个元素是$ (−1)^{i+j}$ 与矩阵 $A $移除 第 $i$ 行 和 第 $j$ 列 之后的行列式的乘积,则可以证明有$A^{−1} = (A’)^T /|A|$。(你可以检查一下,比如在 $A$ 是一个 $2\times 2$ 矩阵的情况下看看 $A^{-1}$ 是什么样的,然后以此类推。如果你想看看对于这一类结果的证明,可以参考一本中级或者高级的线性代数教材,比如Charles Curtis, 1991, Linear Algebra, Springer。)这也就意味着 $A’ = |A|(A^{−1})^T $。此外,一个矩阵 $A$ 的行列式也可以写成 $|A| = \sum_j A_{ij}A’{ij}$ 。因为 $(A’){ij}$ 不依赖 $A_{ij}$ (通过定义也能看出来),这也就意味着$(\frac \partial {\partial A_{ij}})|A| = A’_{ij} $,综合起来也就得到上面的这个结果了。
2.2 最小二乘法回顾(Least squares revisited)
通过刚才的内容,咱们大概掌握了矩阵导数这一工具,接下来咱们就继续用逼近模型(closed-form)来找到能让 $J(\theta)$ 最小的 $\theta$ 值。首先咱们把 $J$ 用矩阵-向量的记号来重新表述。
给定一个训练集,把设计矩阵(design matrix) $x$ 设置为一个 $m\times n$ 矩阵(实际上,如果考虑到截距项,也就是 $\theta_0$ 那一项,就应该是 $m\times (n+1)$ 矩阵),这个矩阵里面包含了训练样本的输入值作为每一行:
$$
X =\begin{bmatrix}
-(x^{(1)}) ^T-\
-(x^{(2)}) ^T-\
\vdots \
-(x^{(m)}) ^T-\
\end{bmatrix}
$$
然后,咱们设 $\vec{y}$ 是一个 $m$ 维向量(m-dimensional vector),其中包含了训练集中的所有目标值:
$$
y =\begin{bmatrix}
y^{(1)}\
y^{(2)}\
\vdots \
y^{(m)}\
\end{bmatrix}
$$
因为 $h_\theta (x^{(i)}) = (x^{(i)})^T\theta $译者注:这个怎么推出来的我目前还没尝试,目测不难,所以可以证明存在下面这种等量关系:
$$
\begin{aligned}
X\theta - \vec{y} &=
\begin{bmatrix}
(x^{(1)})^T\theta \
\vdots \
(x^{(m)})^T\theta\
\end{bmatrix} -
\begin{bmatrix}
y^{(1)}\
\vdots \
y^{(m)}\
\end{bmatrix}\
& =
\begin{bmatrix}
h_\theta (x^{1}) -y^{(1)}\
\vdots \
h_\theta (x^{m})-y^{(m)}\
\end{bmatrix}\
\end{aligned}
$$
对于向量 $\vec{z}$ ,则有 $z^T z = \sum_i z_i^2$ ,因此利用这个性质,可以推出:
$$
\begin{aligned}
\frac 12(X\theta - \vec{y})^T (X\theta - \vec{y}) &=\frac 12 \sum^m_{i=1}(h_\theta (x^{(i)})-y^{(i)})^2\
&= J(\theta)
\end{aligned}
$$
最后,要让 $J$ 的值最小,就要找到函数对于$\theta$导数。结合等式$(2)$和等式$(3)$,就能得到下面这个等式$(5)$:
$$
\nabla_{A^T} trABA^TC =B^TA^TC^T+BA^TC \qquad \text{(5)}
$$
因此就有:
$$
\begin{aligned}
\nabla_\theta J(\theta) &= \nabla_\theta \frac 12 (X\theta - \vec{y})^T (X\theta - \vec{y}) \
&= \frac 12 \nabla_\theta (\theta ^TX^TX\theta -\theta^T X^T \vec{y} - \vec{y} ^TX\theta +\vec{y}^T \vec{y})\
&= \frac 12 \nabla_\theta tr(\theta ^TX^TX\theta -\theta^T X^T \vec{y} - \vec{y} ^TX\theta +\vec{y}^T \vec{y})\
&= \frac 12 \nabla_\theta (tr \theta ^TX^TX\theta - 2tr\vec{y} ^T X\theta)\
&= \frac 12 (X^TX\theta+X^TX\theta-2X^T\vec{y}) \
&= X^TX\theta-X^T\vec{y}\
\end{aligned}
$$
在第三步,我们用到了一个定理,也就是一个实数的迹就是这个实数本身;第四步用到了 $trA = trA^T$ 这个定理;第五步用到了等式$(5)$,其中 $A^T =\theta, B=B^T =X^TX, C=I$,还用到了等式 $(1)$。要让 $J$ 取得最小值,就设导数为 $0$ ,然后就得到了下面的法线方程(normal equations):
$$
X^TX\theta =X^T\vec{y}
$$
所以让 $J(\theta)$ 取值最小的 $\theta$ 就是
$$
\theta = (X^TX)^{-1}X^T\vec{y}
$$
3 概率解释(Probabilistic interpretation)
在面对回归问题的时候,可能有这样一些疑问,就是为什么选择线性回归,尤其是为什么选择最小二乘法作为成本函数 $J$ ?在本节里,我们会给出一系列的概率基本假设,基于这些假设,就可以推出最小二乘法回归是一种非常自然的算法。
首先咱们假设目标变量和输入值存在下面这种等量关系:
$$
y^{(i)}=\theta^T x^{(i)}+ \epsilon ^{(i)}
$$
上式中 $ \epsilon ^{(i)}$ 是误差项,用于存放由于建模所忽略的变量导致的效果 (比如可能某些特征对于房价的影响很明显,但我们做回归的时候忽略掉了)或者随机的噪音信息(random noise)。进一步假设 $ \epsilon ^{(i)}$ 是独立同分布的 (IID ,independently and identically distributed) ,服从高斯分布(Gaussian distribution ,也叫正态分布 Normal distribution),其平均值为 $0$,方差(variance)为 $\sigma ^2$。这样就可以把这个假设写成 $ \epsilon ^{(i)} ∼ N (0, \sigma ^2)$ 。然后 $ \epsilon ^{(i)} $ 的密度函数就是:
$$
p(\epsilon ^{(i)} )= \frac 1{\sqrt{2\pi}\sigma} exp (- \frac {(\epsilon ^{(i)} )^2}{2\sigma^2})
$$
这意味着存在下面的等量关系:
$$
p(y ^{(i)} |x^{(i)}; \theta)= \frac 1{\sqrt{2\pi}\sigma} exp (- \frac {(y^{(i)} -\theta^T x ^{(i)} )^2}{2\sigma^2})
$$
这里的记号 $“p(y ^{(i)} |x^{(i)}; \theta)”$ 表示的是这是一个对于给定 $x^{(i)}$ 时 $y^{(i)}$ 的分布,用$\theta$ 代表该分布的参数。 注意这里不能用 $\theta(“p(y ^{(i)} |x^{(i)},\theta)”)$来当做条件,因为 $\theta$ 并不是一个随机变量。这个 $y^{(i)}$ 的分布还可以写成$y^{(i)} | x^{(i)}; \theta ∼ N (\theta ^T x^{(i)}, \sigma^2)$。
给定一个设计矩阵(design matrix)$X$,其包含了所有的$x^{(i)}$,然后再给定 $\theta$,那么 $y^{(i)}$ 的分布是什么?数据的概率以$p (\vec{y}|X;\theta )$ 的形式给出。在$\theta$取某个固定值的情况下,这个等式通常可以看做是一个 $\vec{y}$ 的函数(也可以看成是 $X$ 的函数)。当我们要把它当做 $\theta$ 的函数的时候,就称它为 似然函数(likelihood function)
$$
L(\theta) =L(\theta;X,\vec{y})=p(\vec{y}|X;\theta)
$$
结合之前对 $\epsilon^{(i)}$ 的独立性假设 (这里对$y^{(i)}$ 以及给定的 $x^{(i)}$ 也都做同样假设),就可以把上面这个等式改写成下面的形式:
$$
\begin{aligned}
L(\theta) &=\prod ^m _{i=1}p(y^{(i)}|x^{(i)};\theta)\
&=\prod ^m _{i=1} \frac 1{\sqrt{2\pi}\sigma} exp(- \frac {(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2})\
\end{aligned}
$$
现在,给定了$y^{(i)}$ 和 $x^{(i)}$之间关系的概率模型了,用什么方法来选择咱们对参数 $\theta$ 的最佳猜测呢?最大似然法(maximum likelihood)告诉我们要选择能让数据的似然函数尽可能大的 $\theta$。也就是说,咱们要找的 $\theta$ 能够让函数 $L(\theta)$ 取到最大值。
除了找到 $L(\theta)$ 最大值,我们还以对任何严格递增的 $L(\theta)$ 的函数求最大值。如果我们不直接使用 $L(\theta)$,而是使用对数函数,来找对数似然函数 $l(\theta)$ 的最大值,那这样对于求导来说就简单了一些:
$$
\begin{aligned}
l(\theta) &=\log L(\theta)\
&=\log \prod ^m _{i=1} \frac 1{\sqrt{2\pi}\sigma} exp(- \frac {(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2})\
&= \sum ^m {i=1}log \frac 1{\sqrt{2\pi}\sigma} exp(- \frac {(y^{(i)}-\theta^T x^{(i)})^2}{2\sigma^2})\
&= m \log \frac 1{\sqrt{2\pi}\sigma}- \frac 1{\sigma^2}\cdot \frac 12 \sum^m{i=1} (y^{(i)}-\theta^Tx^{(i)})^2\
\end{aligned}
$$
因此,对 $l(\theta)$ 取得最大值也就意味着下面这个子式取到最小值:
$$
\frac 12 \sum^m _{i=1} (y^{(i)}-\theta^Tx^{(i)})^2
$$
到这里我们能发现这个子式实际上就是 $J(\theta)$,也就是最原始的最小二乘成本函数(least-squares cost function)。
总结一下也就是:在对数据进行概率假设的基础上,最小二乘回归得到的 $\theta$ 和最大似然法估计的 $\theta$ 是一致的。所以这是一系列的假设,其前提是认为最小二乘回归(least-squares regression)能够被判定为一种非常自然的方法,这种方法正好就进行了最大似然估计(maximum likelihood estimation)。(要注意,对于验证最小二乘法是否为一个良好并且合理的过程来说,这些概率假设并不是必须的,此外可能(也确实)有其他的自然假设能够用来评判最小二乘方法。)
另外还要注意,在刚才的讨论中,我们最终对 $\theta$ 的选择并不依赖 $\sigma^2$,而且也确实在不知道 $\sigma^2$ 的情况下就已经找到了结果。稍后我们还要对这个情况加以利用,到时候我们会讨论指数族以及广义线性模型。
4 局部加权线性回归(Locally weighted linear regression)
假如问题还是根据从实数域内取值的 $x\in R$ 来预测 $y$ 。左下角的图显示了使用 $y = \theta_0 + \theta_1x$ 来对一个数据集进行拟合。我们明显能看出来这个数据的趋势并不是一条严格的直线,所以用直线进行的拟合就不是好的方法。
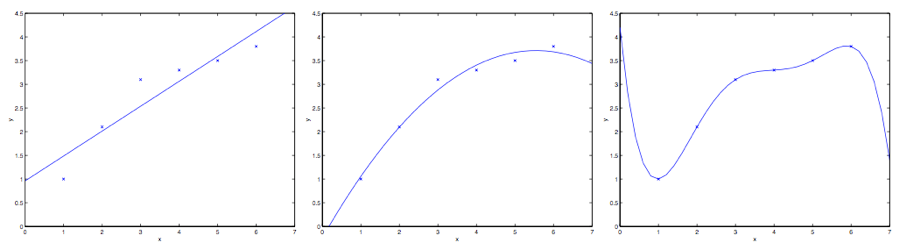
那么这次不用直线,而增加一个二次项,用$y = \theta_0 + \theta_1x +\theta_2x^2$ 来拟合。(看中间的图) 很明显,我们对特征补充得越多,效果就越好。不过,增加太多特征也会造成危险的:最右边的图就是使用了五次多项式 $y = \sum^5_{j=0} \theta_jx^j$ 来进行拟合。看图就能发现,虽然这个拟合曲线完美地通过了所有当前数据集中的数据,但我们明显不能认为这个曲线是一个合适的预测工具,比如针对不同的居住面积 $x$ 来预测房屋价格 $y$。先不说这些特殊名词的正规定义,咱们就简单说,最左边的图像就是一个欠拟合(under fitting) 的例子,比如明显能看出拟合的模型漏掉了数据集中的结构信息;而最右边的图像就是一个过拟合(over fitting) 的例子。(在本课程的后续部分中,当我们讨论到关于学习理论的时候,会给出这些概念的标准定义,也会给出拟合程度对于一个猜测的好坏检验的意义。)
正如前文谈到的,也正如上面这个例子展示的,一个学习算法要保证能良好运行,特征的选择是非常重要的。(等到我们讲模型选择的时候,还会看到一些算法能够自动来选择一个良好的特征集。)在本节,咱们就简要地讲一下局部加权线性回归(locally weighted linear regression ,缩写为LWR),这个方法是假设有足够多的训练数据,对不太重要的特征进行一些筛选。这部分内容会比较简略,因为在作业中要求学生自己去探索一下LWR 算法的各种性质了。
在原始版本的线性回归算法中,要对一个查询点 $x$ 进行预测,比如要衡量$h(x)$,要经过下面的步骤:
- 使用参数 $\theta$ 进行拟合,让数据集中的值与拟合算出的值的差值平方$\sum_i(y^{(i)} − \theta^T x^{(i)} )^2$最小(最小二乘法的思想);
- 输出 $\theta^T x$ 。
相应地,在 LWR 局部加权线性回归方法中,步骤如下:
- 使用参数 $\theta$ 进行拟合,让加权距离$\sum_i w^{(i)}(y^{(i)} − \theta^T x^{(i)} )^2$ 最小;
- 输出 $\theta^T x$。
上面式子中的 $w^{(i)}$ 是非负的权值。直观点说就是,如果对应某个$i$ 的权值 $w^{(i)}$ 特别大,那么在选择拟合参数 $\theta$ 的时候,就要尽量让这一点的 $(y^{(i)} − \theta^T x^{(i)} )^2$ 最小。而如果权值$w^{(i)}$ 特别小,那么这一点对应的$(y^{(i)} − \theta^T x^{(i)} )^2$ 就基本在拟合过程中忽略掉了。
对于权值的选取可以使用下面这个比较标准的公式:$^4$
$$
w^{(i)} = exp(- \frac {(x^{(i)}-x)^2}{2\tau^2})
$$
4 如果 $x$ 是有值的向量,那就要对上面的式子进行泛化,得到的是$w^{(i)} = exp(− \frac {(x^{(i)}-x)^T(x^{(i)}-x)}{2\tau^2})$,或者:$w^{(i)} = exp(− \frac {(x^{(i)}-x)^T\Sigma ^{-1}(x^{(i)}-x)}{2})$,这就看是选择用$\tau$ 还是 $\Sigma$。
要注意的是,权值是依赖每个特定的点 $x$ 的,而这些点正是我们要去进行预测评估的点。此外,如果 $|x^{(i)} − x|$ 非常小,那么权值 $w^{(i)} $就接近 $1$;反之如果 $|x^{(i)} − x|$ 非常大,那么权值 $w^{(i)} $就变小。所以可以看出, $\theta$ 的选择过程中,查询点 $x$ 附近的训练样本有更高得多的权值。($\theta$is chosen giving a much higher “weight” to the (errors on) training examples close to the query point x.)(还要注意,当权值的方程的形式跟高斯分布的密度函数比较接近的时候,权值和高斯分布并没有什么直接联系,尤其是当权值不是随机值,且呈现正态分布或者其他形式分布的时候。)随着点$x^{(i)} $ 到查询点 $x$ 的距离降低,训练样本的权值的也在降低,参数$\tau$ 控制了这个降低的速度;$\tau$也叫做带宽参数,这个也是在你的作业中需要来体验和尝试的一个参数。
局部加权线性回归是咱们接触的第一个非参数 算法。而更早之前咱们看到的无权重的线性回归算法就是一种参数 学习算法,因为有固定的有限个数的参数(也就是 $\theta_i$ ),这些参数用来拟合数据。我们对 $\theta_i$ 进行了拟合之后,就把它们存了起来,也就不需要再保留训练数据样本来进行更进一步的预测了。与之相反,如果用局部加权线性回归算法,我们就必须一直保留着整个训练集。这里的非参数算法中的 非参数“non-parametric” 是粗略地指:为了呈现出假设 $h$ 随着数据集规模的增长而线性增长,我们需要以一定顺序保存一些数据的规模。(The term “non-parametric” (roughly) refers to the fact that the amount of stuff we need to keep in order to represent the hypothesis h grows linearly with the size of the training set. )
第二部分 分类和逻辑回归(Classification and logistic regression)
接下来咱们讲一下分类的问题。分类问题其实和回归问题很像,只不过我们现在要来预测的 $y$ 的值只局限于少数的若干个离散值。眼下咱们首先关注的是二值化分类 问题,也就是说咱们要判断的 $y$ 只有两个取值,$0$ 或者 $1$。(咱们这里谈到的大部分内容也都可以扩展到多种类的情况。)例如,假如要建立一个垃圾邮件筛选器,那么就可以用 $x^{(i)}$ 表示一个邮件中的若干特征,然后如果这个邮件是垃圾邮件,$y$ 就设为$1$,否则 $y$ 为 $0$。$0$ 也可以被称为消极类别(negative class),而 $1$ 就成为积极类别(positive class),有的情况下也分别表示成“-” 和 “+”。对于给定的一个 $x^{(i)}$,对应的$y^{(i)}$也称为训练样本的标签(label)。
5 逻辑回归(Logistic regression)
我们当然也可以还按照之前的线性回归的算法来根据给定的 $x$ 来预测 $y$,只要忽略掉 $y$ 是一个散列值就可以了。然而,这样构建的例子很容易遇到性能问题,这个方法运行效率会非常低,效果很差。而且从直观上来看,$h_\theta(x)$ 的值如果大于$1$ 或者小于$0$ 就都没有意义了,因为咱们已经实现都确定了 $y \in {0, 1}$,就是说 $y$ 必然应当是 $0$ 和 $1$ 这两个值当中的一个。
所以咱们就改变一下假设函数$h_\theta (x)$ 的形式,来解决这个问题。比如咱们可以选择下面这个函数:
$$
h_\theta(x) = g(\theta^T x) = \frac 1{1+e^{-\theta^Tx}}
$$
其中有:
$$
g(z)= \frac 1 {1+e^{-z}}
$$
这个函数叫做逻辑函数 (Logistic function) ,或者也叫双弯曲S型函数(sigmoid function)。下图是 $g(z)$ 的函数图像:
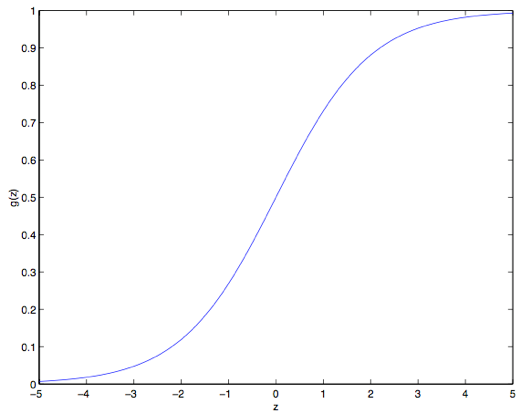
注意到没有,当$z\to +\infty$ 的时候 $g(z)$ 趋向于$1$,而当$z\to -\infty$ 时$g(z)$ 趋向于$0$。此外,这里的这个 $g(z)$ ,也就是 $h(x)$,是一直在 $0$ 和 $1$ 之间波动的。然后咱们依然像最开始那样来设置 $x_0 = 1$,这样就有了:$\theta^T x =\theta_0 +\sum^n_{j=1}\theta_jx_j$
现在咱们就把 $g$ 作为选定的函数了。当然其他的从$0$到$1$之间光滑递增的函数也可以使用,不过后面我们会了解到选择 $g$ 的一些原因(到时候我们讲广义线性模型 GLMs,那时候还会讲生成学习算法,generative learning algorithms),对这个逻辑函数的选择是很自然的。再继续深入之前,下面是要讲解的关于这个 S 型函数的导数,也就是 $g’$ 的一些性质:
$$
\begin{aligned}
g’(z) & = \frac d{dz}\frac 1{1+e^{-z}}\
& = \frac 1{(1+e^{-z})^2}(e^{-z})\
& = \frac 1{(1+e^{-z})} \cdot (1- \frac 1{(1+e^{-z})})\
& = g(z)(1-g(z))\
\end{aligned}
$$
那么,给定了逻辑回归模型了,咱们怎么去拟合一个合适的 $\theta$ 呢?我们之前已经看到了在一系列假设的前提下,最小二乘法回归可以通过最大似然估计来推出,那么接下来就给我们的这个分类模型做一系列的统计学假设,然后用最大似然法来拟合参数吧。
首先假设:
$$
\begin{aligned}
P(y=1|x;\theta)&=h_{\theta}(x)\
P(y=0|x;\theta)&=1- h_{\theta}(x)\
\end{aligned}
$$
更简洁的写法是:
$$
p(y|x;\theta)=(h_\theta (x))^y(1- h_\theta (x))^{1-y}
$$
假设 $m$ 个训练样本都是各自独立生成的,那么就可以按如下的方式来写参数的似然函数:
$$
\begin{aligned}
L(\theta) &= p(\vec{y}| X; \theta)\
&= \prod^m_{i=1} p(y^{(i)}| x^{(i)}; \theta)\
&= \prod^m_{i=1} (h_\theta (x^{(i)}))^{y^{(i)}}(1-h_\theta (x^{(i)}))^{1-y^{(i)}} \
\end{aligned}
$$
然后还是跟之前一样,取个对数就更容易计算最大值:
$$
\begin{aligned}
l(\theta) &=\log L(\theta) \
&= \sum^m_{i=1} y^{(i)} \log h(x^{(i)})+(1-y^{(i)})\log (1-h(x^{(i)}))
\end{aligned}
$$
怎么让似然函数最大?就跟之前咱们在线性回归的时候用了求导数的方法类似,咱们这次就是用梯度上升法(gradient ascent)。还是写成向量的形式,然后进行更新,也就是$ \theta := \theta +\alpha \nabla _\theta l(\theta)$ 。 (注意更新方程中用的是加号而不是减号,因为我们现在是在找一个函数的最大值,而不是找最小值了。) 还是先从只有一组训练样本$(x,y)$ 来开始,然后求导数来推出随机梯度上升规则:
$$
\begin{aligned}
\frac {\partial}{\partial \theta_j} l(\theta) &=(y\frac 1 {g(\theta ^T x)} - (1-y)\frac 1 {1- g(\theta ^T x)} )\frac {\partial}{\partial \theta_j}g(\theta ^Tx) \
&= (y\frac 1 {g(\theta ^T x)} - (1-y)\frac 1 {1- g(\theta ^T x)} ) g(\theta^Tx)(1-g(\theta^Tx)) \frac {\partial}{\partial \theta_j}\theta ^Tx \
&= (y(1-g(\theta^Tx) ) -(1-y) g(\theta^Tx)) x_j\
&= (y-h_\theta(x))x_j
\end{aligned}
$$
上面的式子里,我们用到了对函数求导的定理 $ g’(z)= g(z)(1-g(z))$ 。然后就得到了随机梯度上升规则:
$$
\theta_j := \theta_j + \alpha (y^{(i)}-h_\theta (x^{(i)}))x_j^{(i)}
$$
如果跟之前的 LMS 更新规则相对比,就能发现看上去挺相似的;不过这并不是同一个算法,因为这里的$h_\theta(x^{(i)})$现在定义成了一个 $\theta^Tx^{(i)}$ 的非线性函数。尽管如此,我们面对不同的学习问题使用了不同的算法,却得到了看上去一样的更新规则,这个还是有点让人吃惊。这是一个巧合么,还是背后有更深层次的原因呢?在我们学到了 GLM 广义线性模型的时候就会得到答案了。(另外也可以看一下 习题集1 里面 Q3 的附加题。)
6 题外话: 感知器学习算法(The perceptron learning algorithm)
现在咱们来岔开一下话题,简要地聊一个算法,这个算法的历史很有趣,并且之后在我们讲学习理论的时候还要讲到它。设想一下,对逻辑回归方法修改一下,“强迫”它输出的值要么是 $0$ 要么是 $1$。要实现这个目的,很自然就应该把函数 $g$ 的定义修改一下,改成一个阈值函数(threshold function):
$$
g(z)= \begin{cases} 1 & if\quad z \geq 0 \
0 & if\quad z < 0 \end{cases}
$$
如果我们还像之前一样令 $h_\theta(x) = g(\theta^T x)$,但用刚刚上面的阈值函数作为 $g$ 的定义,然后如果我们用了下面的更新规则:
$$
\theta_j := \theta_j +\alpha(y^{(i)}-h_\theta (x^{(i)}))x_j^{(i)}
$$
这样我们就得到了感知器学习算法。
在 1960 年代,这个“感知器(perceptron)”被认为是对大脑中单个神经元工作方法的一个粗略建模。鉴于这个算法的简单程度,这个算法也是我们后续在本课程中讲学习理论的时候的起点。但一定要注意,虽然这个感知器学习算法可能看上去表面上跟我们之前讲的其他算法挺相似,但实际上这是一个和逻辑回归以及最小二乘线性回归等算法在种类上都完全不同的算法;尤其重要的是,很难对感知器的预测赋予有意义的概率解释,也很难作为一种最大似然估计算法来推出感知器学习算法。
7 让$l(\theta)$ 取最大值的另外一个算法
再回到用 S 型函数 $g(z)$ 来进行逻辑回归的情况,咱们来讲一个让 $l(\theta)$ 取最大值的另一个算法。
开始之前,咱们先想一下求一个方程零点的牛顿法。假如我们有一个从实数到实数的函数 $f:R \to R$,然后要找到一个 $\theta$ ,来满足 $f(\theta)=0$,其中 $\theta\in R$ 是一个实数。牛顿法就是对 $\theta$ 进行如下的更新:
$$
\theta := \theta - \frac {f(\theta)}{f’(\theta)}
$$
这个方法可以通过一个很自然的解释,我们可以把它理解成用一个线性函数来对函数 $f$ 进行逼近,这条直线是 $f$ 的切线,而猜测值是 $\theta$,解的方法就是找到线性方程等于零的点,把这一个零点作为 $\theta$ 设置给下一次猜测,然后以此类推。
下面是对牛顿法的图解: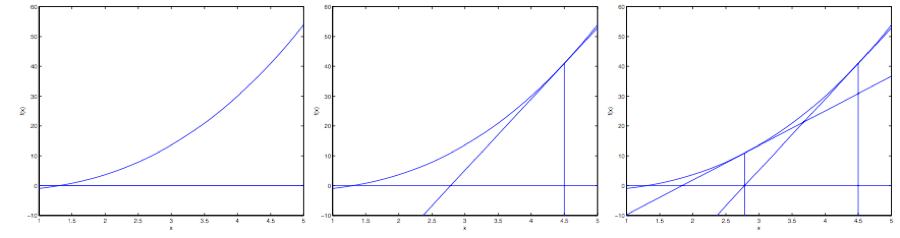
在最左边的图里面,可以看到函数 $f$ 就是沿着 $y=0$ 的一条直线。这时候是想要找一个 $\theta$ 来让 $f(\theta)=0$。这时候发现这个 $\theta$ 值大概在 $1.3$ 左右。加入咱们猜测的初始值设定为 $\theta=4.5$。牛顿法就是在 $\theta=4.5$ 这个位置画一条切线(中间的图)。这样就给出了下一个 $\theta$ 猜测值的位置,也就是这个切线的零点,大概是$2.8$。最右面的图中的是再运行一次这个迭代产生的结果,这时候 $\theta$ 大概是$1.8$。就这样几次迭代之后,很快就能接近 $\theta=1.3$。
牛顿法的给出的解决思路是让 $f(\theta) = 0$ 。如果咱们要用它来让函数 $l$ 取得最大值能不能行呢?函数 $l$ 的最大值的点应该对应着是它的导数$l’(\theta)$ 等于零的点。所以通过令$f(\theta) = l’(\theta)$,咱们就可以同样用牛顿法来找到 $l$ 的最大值,然后得到下面的更新规则:
$$
\theta := \theta - \frac {l’(\theta)}{l’’(\theta)}
$$
(扩展一下,额外再思考一下: 如果咱们要用牛顿法来求一个函数的最小值而不是最大值,该怎么修改?)译者注:试试法线的零点
最后,在咱们的逻辑回归背景中,$\theta$ 是一个有值的向量,所以我们要对牛顿法进行扩展来适应这个情况。牛顿法进行扩展到多维情况,也叫牛顿-拉普森法(Newton-Raphson method),如下所示:
$$
\theta := \theta - H^{-1}\nabla_\theta l(\theta)
$$
上面这个式子中的 $\nabla_\theta l(\theta)$和之前的样例中的类似,是关于 $\theta_i$ 的 $l(\theta)$ 的偏导数向量;而 $h$ 是一个 $n\times n$ 矩阵 ,实际上如果包含截距项的话,应该是, $(n + 1)\times (n + 1)$,也叫做 Hessian, 其详细定义是:
$$
H_{ij}= \frac {\partial^2 l(\theta)}{\partial \theta_i \partial \theta_j}
$$
牛顿法通常都能比(批量)梯度下降法收敛得更快,而且达到最小值所需要的迭代次数也低很多。然而,牛顿法中的单次迭代往往要比梯度下降法的单步耗费更多的性能开销,因为要查找和转换一个 $n\times n$的 Hessian 矩阵;不过只要这个 $n$ 不是太大,牛顿法通常就还是更快一些。当用牛顿法来在逻辑回归中求似然函数$l(\theta)$ 的最大值的时候,得到这一结果的方法也叫做Fisher评分(Fisher scoring)。
第三部分 广义线性模型 (Generalized Linear Models)$^5$
5 本节展示的内容受以下两份作品的启发:Michael I. Jordan, Learning in graphical models (unpublished book draft), 以及 McCullagh and Nelder, Generalized Linear Models (2nd ed.)。
到目前为止,我们看过了回归的案例,也看了一个分类案例。在回归的案例中,我们得到的函数是 $y|x; \theta ∼ N (\mu, \sigma^2)$;而分类的案例中,函数是 $y|x; \theta ∼ Bernoulli(\phi)$,这里面的$\mu$ 和 $\phi$ 分别是 $x$ 和 $\theta$ 的某种函数。在本节,我们会发现这两种方法都是一个更广泛使用的模型的特例,这种更广泛使用的模型就叫做广义线性模型。我们还会讲一下广义线性模型中的其他模型是如何推出的,以及如何应用到其他的分类和回归问题上。
8 指数族 (The exponential family)
在学习 GLMs 之前,我们要先定义一下指数组分布(exponential family distributions)。如果一个分布能用下面的方式来写出来,我们就说这类分布属于指数族:
$$
p(y;\eta) =b(y)exp(\eta^TT(y)-a(\eta)) \qquad \text{(6)}
$$
上面的式子中,$\eta$ 叫做此分布的自然参数 (natural parameter,也叫典范参数 canonical parameter) ; $T(y)$ 叫做充分统计量(sufficient statistic) ,我们目前用的这些分布中通常 $T (y) = y$;而 $a(\eta)$ 是一个对数分割函数(log partition function)。 $e^{−a(\eta)}$ 这个量本质上扮演了归一化常数(normalization constant)的角色,也就是确保 $p(y; \eta)$ 的总和或者积分等于$1$。
当给定 $T$, $a$ 和 $b$ 时,就定义了一个用 $\eta$ 进行参数化的分布族(family,或者叫集 set);通过改变 $\eta$,我们就能得到这个分布族中的不同分布。
现在咱们看到的伯努利(Bernoulli)分布和高斯(Gaussian)分布就都属于指数分布族。伯努利分布的均值是$\phi$,也写作 $Bernoulli(\phi)$,确定的分布是 $y \in {0, 1}$,因此有 $p(y = 1; \phi) = \phi$; $p(y = 0;\phi) = 1−\phi$。这时候只要修改$\phi$,就能得到一系列不同均值的伯努利分布了。现在我们展示的通过修改$\phi$,而得到的这种伯努利分布,就属于指数分布族;也就是说,只要给定一组 $T$,$a$ 和 $b$,就可以用上面的等式$(6)$来确定一组特定的伯努利分布了。
我们这样来写伯努利分布:
$$
\begin{aligned}
p(y;\phi) & = \phi ^y(1-\phi)^{1-y}\
& = exp(y \log \phi + (1-y)\log(1-\phi))\
& = exp( (log (\frac {\phi}{1-\phi}))y+\log (1-\phi) )\
\end{aligned}
$$
因此,自然参数(natural parameter)就给出了,即 $\eta = log (\frac \phi {1 − \phi})$。 很有趣的是,如果我们翻转这个定义,用$\eta$ 来解 $\phi$ 就会得到 $\phi = 1/ (1 + e^{−\eta} )$。这正好就是之前我们刚刚见到过的 S型函数(sigmoid function)!在我们把逻辑回归作为一种广义线性模型(GLM)的时候还会得到:
$$
\begin{aligned}
T(y) &= y \
a( \eta) & = - \log (1- \phi) \
& = \log {(1+ e^ \eta)}\
b(y)&=1
\end{aligned}
$$
上面这组式子就表明了伯努利分布可以写成等式$(6)$的形式,使用一组合适的$T$, $a$ 和 $b$。
接下来就看看高斯分布吧。还记得吧,在推导线性回归的时候,$\sigma^2$ 的值对我们最终选择的 $\theta$ 和 $h_\theta(x)$ 都没有影响。所以我们可以给 $\sigma^2$ 取一个任意值。为了简化推导过程,就令$\sigma^2 = 1$。$^6$然后就有了下面的等式:
$$
\begin{aligned}
p(y;\mu) &= \frac 1{\sqrt{2\pi}} exp (- \frac 12 (y-\mu)^2) \
& = \frac 1{\sqrt{2\pi}} exp (- \frac 12 y^2) \cdot exp (\mu y -\frac 12 \mu^2) \
\end{aligned}
$$
6 如果我们把 $\sigma^2$ 留作一个变量,高斯分布就也可以表达成指数分布的形式,其中 $\eta \in R^2$ 就是一个二维向量,同时依赖 $\mu$ 和 $\sigma$。然而,对于广义线性模型GLMs方面的用途, $\sigma^2$ 参数也可以看成是对指数分布族的更泛化的定义: $p(y; \eta, \tau ) = b(a, \tau ) exp((\eta^T T (y) − a(\eta))/c(\tau))$。这里面的$\tau$ 叫做分散度参数(dispersion parameter),对于高斯分布, $c(\tau) = \sigma^2$ ;不过上文中我们已经进行了简化,所以针对我们要考虑的各种案例,就不需要再进行更加泛化的定义了。
这样,我们就可以看出来高斯分布是属于指数分布族的,可以写成下面这样:
$$
\begin{aligned}
\eta & = \mu \
T(y) & = y \
a(\eta) & = \mu ^2 /2\
& = \eta ^2 /2\
b(y) & = (1/ \sqrt {2\pi })exp(-y^2/2)
\end{aligned}
$$
指数分布族里面还有很多其他的分布:
- 例如多项式分布(multinomial),这个稍后我们会看到;
- 泊松分布(Poisson),用于对计数类数据进行建模,后面再问题集里面也会看到;
- 伽马和指数分布(the gamma and the exponential),这个用于对连续的、非负的随机变量进行建模,例如时间间隔;
- 贝塔和狄利克雷分布(the beta and the Dirichlet),这个是用于概率的分布;
- 还有很多,这里就不一一列举了。
在下一节里面,我们就来讲一讲对于建模的一个更通用的“方案”,其中的$y$ (给定 $x$ 和 $\theta$)可以是上面这些分布中的任意一种。
9 构建广义线性模型(Constructing GLMs)
设想你要构建一个模型,来估计在给定的某个小时内来到你商店的顾客人数(或者是你的网站的页面访问次数),基于某些确定的特征 $x$ ,例如商店的促销、最近的广告、天气、今天周几啊等等。我们已经知道泊松分布(Poisson distribution)通常能适合用来对访客数目进行建模。知道了这个之后,怎么来建立一个模型来解决咱们这个具体问题呢?非常幸运的是,泊松分布是属于指数分布族的一个分布,所以我们可以对该问题使用广义线性模型(Generalized Linear Model,缩写为 GLM)。在本节,我们讲一种对刚刚这类问题构建广义线性模型的方法。
进一步泛化,设想一个分类或者回归问题,要预测一些随机变量 $y$ 的值,作为 $x$ 的一个函数。要导出适用于这个问题的广义线性模型,就要对我们的模型、给定 $x$ 下 $y$ 的条件分布来做出以下三个假设:
$y | x; \theta ∼ Exponential Family(\eta)$,即给定 $x$ 和 $\theta, y$ 的分布属于指数分布族,是一个参数为 $\eta$ 的指数分布。——假设1给定 $x$,目的是要预测对应这个给定 $x$ 的 $T(y)$ 的期望值。咱们的例子中绝大部分情况都是 $T(y) = y$,这也就意味着我们的学习假设 $h$ 输出的预测值 $h(x)$ 要满足 $h(x) = E[y|x]$。 (注意,这个假设通过对 $h_\theta(x)$ 的选择而满足,在逻辑回归和线性回归中都是如此。例如在逻辑回归中, $h_\theta (x) = [p (y = 1|x; \theta)] =[ 0 \cdot p (y = 0|x; \theta)+1\cdot p(y = 1|x;\theta)] = E[y|x;\theta]$。**译者注:这里的$E[y|x$]应该就是对给定$x$时的$y$值的期望的意思。**)——假设2自然参数 $\eta$ 和输入值 $x$ 是线性相关的,$\eta = \theta^T x$,或者如果 $\eta$ 是有值的向量,则有$\eta_i = \theta_i^T x$。——假设3
上面的几个假设中,第三个可能看上去证明得最差,所以也更适合把这第三个假设看作是一个我们在设计广义线性模型时候的一种 “设计选择 design choice”,而不是一个假设。那么这三个假设/设计,就可以用来推导出一个非常合适的学习算法类别,也就是广义线性模型 GLMs,这个模型有很多特别友好又理想的性质,比如很容易学习。此外,这类模型对一些关于 $y$ 的分布的不同类型建模来说通常效率都很高;例如,我们下面就将要简单介绍一些逻辑回归以及普通最小二乘法这两者如何作为广义线性模型来推出。
9.1 普通最小二乘法(Ordinary Least Squares)
我们这一节要讲的是普通最小二乘法实际上是广义线性模型中的一种特例,设想如下的背景设置:目标变量 $y$(在广义线性模型的术语也叫做响应变量response variable)是连续的,然后我们将给定 $x$ 的 $y$ 的分布以高斯分布 $N(\mu, \sigma^2)$ 来建模,其中 $\mu$ 可以是依赖 $x$ 的一个函数。这样,我们就让上面的$ExponentialFamily(\eta)$分布成为了一个高斯分布。在前面内容中我们提到过,在把高斯分布写成指数分布族的分布的时候,有$\mu = \eta$。所以就能得到下面的等式:
$$
\begin{aligned}
h_\theta(x)& = E[y|x;\theta] \
& = \mu \
& = \eta \
& = \theta^Tx\
\end{aligned}
$$
第一行的等式是基于假设2;第二个等式是基于定理当 $y|x; \theta ∼ N (\mu, \sigma ^2)$,则 $y$ 的期望就是 $\mu$ ;第三个等式是基于假设1,以及之前我们此前将高斯分布写成指数族分布的时候推导出来的性质 $\mu = \eta$;最后一个等式就是基于假设3。
9.2 逻辑回归(Logistic Regression)
接下来咱们再来看看逻辑回归。这里咱们还是看看二值化分类问题,也就是 $y \in {0, 1}$。给定了$y$ 是一个二选一的值,那么很自然就选择伯努利分布(Bernoulli distribution)来对给定 $x$ 的 $y$ 的分布进行建模了。在我们把伯努利分布写成一种指数族分布的时候,有 $\phi = 1/ (1 + e^{−\eta})$。另外还要注意的是,如果有 $y|x; \theta ∼ Bernoulli(\phi)$,那么 $E [y|x; \theta] = \phi$。所以就跟刚刚推导普通最小二乘法的过程类似,有以下等式:
$$
\begin{aligned}
h_\theta(x)& = E[y|x;\theta] \
& = \phi \
& = 1/(1+ e^{-\eta}) \
& = 1/(1+ e^{-\theta^Tx})\
\end{aligned}
$$
所以,上面的等式就给了给了假设函数的形式:$h_\theta(x) = 1/ (1 + e^{−\theta^T x})$。如果你之前好奇咱们是怎么想出来逻辑回归的函数为$1/ (1 + e^{−z} )$,这个就是一种解答:一旦我们假设以 $x$ 为条件的 $y$ 的分布是伯努利分布,那么根据广义线性模型和指数分布族的定义,就会得出这个式子。
再解释一点术语,这里给出分布均值的函数 $g$ 是一个关于自然参数的函数,$g(\eta) = E[T(y); \eta]$,这个函数也叫做规范响应函数(canonical response function), 它的反函数 $g^{−1}$ 叫做规范链接函数(canonical link function)。 因此,对于高斯分布来说,它的规范响应函数正好就是识别函数(identify function);而对于伯努利分布来说,它的规范响应函数则是逻辑函数(logistic function)。$^7$
7 很多教科书用 $g$ 表示链接函数,而用反函数$g^{−1}$ 来表示响应函数;但是咱们这里用的是反过来的,这是继承了早期的机器学习中的用法,我们这样使用和后续的其他课程能够更好地衔接起来。
9.3 Softmax 回归
咱们再来看一个广义线性模型的例子吧。设想有这样的一个分类问题,其中响应变量 $y$ 的取值可以是 $k$ 个值当中的任意一个,也就是 $y \in {1, 2, …, k}$。例如,我们这次要进行的分类就比把邮件分成垃圾邮件和正常邮件两类这种二值化分类要更加复杂一些,比如可能是要分成三类,例如垃圾邮件、个人邮件、工作相关邮件。这样响应变量依然还是离散的,但取值就不只有两个了。因此咱们就用多项式分布(multinomial distribution)来进行建模。
下面咱们就通过这种多项式分布来推出一个广义线性模型。要实现这一目的,首先还是要把多项式分布也用指数族分布来进行描述。
要对一个可能有 $k$ 个不同输出值的多项式进行参数化,就可以用 $k$ 个参数 $\phi_1,…,\phi_ k$ 来对应各自输出值的概率。不过这么多参数可能太多了,形式上也太麻烦,他们也未必都是互相独立的(比如对于任意一个$\phi_ i$中的值来说,只要知道其他的 $k-1$ 个值,就能知道这最后一个了,因为总和等于$1$,也就是$\sum^k_{i=1} \phi_i = 1$)。所以咱们就去掉一个参数,只用 $k-1$ 个:$\phi_1,…,\phi_ {k-1}$ 来对多项式进行参数化,其中$\phi_i = p (y = i; \phi),p (y = k; \phi) = 1 −\sum ^{k−1}{i=1}\phi i$。为了表述起来方便,我们还要设 $\phi_k = 1 − \sum_{i=1}^{k−1} \phi_i$,但一定要注意,这个并不是一个参数,而是完全由其他的 $k-1$ 个参数来确定的。
要把一个多项式表达成为指数组分布,还要按照下面的方式定义一个 $T (y) \in R^{k−1}$:
$$
T(1)=
\begin{bmatrix}
1\
0\
0\
\vdots \
0\
\end{bmatrix},
T(2)=
\begin{bmatrix}
0\
1\
0\
\vdots \
0\
\end{bmatrix},
T(3)=
\begin{bmatrix}
0\
0\
1\
\vdots \
0\
\end{bmatrix},
T(k-1)=
\begin{bmatrix}
0\
0\
0\
\vdots \
1\
\end{bmatrix},
T(k)=
\begin{bmatrix}
0\
0\
0\
\vdots \
0\
\end{bmatrix},
$$
这次和之前的样例都不一样了,就是不再有 $T(y) = y$;然后,$T(y)$ 现在是一个 $k – 1$ 维的向量,而不是一个实数了。向量 $T(y)$ 中的第 $i$ 个元素写成$(T(y))_i$ 。
现在介绍一种非常有用的记号。指示函数(indicator function)$1{\cdot }$,如果参数为真,则等于$1$;反之则等于$0$($1{True} = 1, 1{False} = 0$)。例如$1{2 = 3} = 0$, 而$1{3 = 5 − 2} = 1$。所以我们可以把$T(y)$ 和 $y$ 的关系写成 $(T(y))_i = 1{y = i}$。(往下继续阅读之前,一定要确保你理解了这里的表达式为真!)在此基础上,就有了$E[(T(y))_i] = P (y = i) = \phi_i$。
现在一切就绪,可以把多项式写成指数族分布了。写出来如下所示:
$$
\begin{aligned}
p(y;\phi) &=\phi_1^{1{y=1}}\phi_2^{1{y=2}}\dots \phi_k^{1{y=k}} \
&=\phi_1^{1{y=1}}\phi_2^{1{y=2}}\dots \phi_k^{1-\sum_{i=1}^{k-1}1{y=i}} \
&=\phi_1^{(T(y))_1}\phi_2^{(T(y))2}\dots \phi_k^{1-\sum{i=1}^{k-1}(T(y))_i } \
&=exp((T(y))_1 log(\phi_1)+(T(y))2 log(\phi_2)+\dots+(1-\sum{i=1}^{k-1}(T(y))_i)log(\phi_k)) \
&= exp((T(y))1 log(\frac{\phi_1}{\phi_k})+(T(y))2 log(\frac{\phi_2}{\phi_k})+\dots+(T(y)){k-1}log(\frac{\phi{k-1}}{\phi_k})+log(\phi_k)) \
&=b(y)exp(\eta^T T(y)-a(\eta))
\end{aligned}
$$
其中:
$$
\begin{aligned}
\eta &=
\begin{bmatrix}
\log (\phi _1/\phi _k)\
\log (\phi _2/\phi _k)\
\vdots \
\log (\phi _{k-1}/\phi _k)\
\end{bmatrix}, \
a(\eta) &= -\log (\phi _k)\
b(y) &= 1\
\end{aligned}
$$
这样咱们就把多项式方程作为一个指数族分布来写了出来。
与 $i (for\quad i = 1, …, k)$对应的链接函数为:
$$
\eta_i =\log \frac {\phi_i}{\phi_k}
$$
为了方便起见,我们再定义 $\eta_k = \log (\phi_k/\phi_k) = 0$。对链接函数取反函数然后推导出响应函数,就得到了下面的等式:
$$
\begin{aligned}
e^{\eta_i} &= \frac {\phi_i}{\phi_k}\
\phi_k e^{\eta_i} &= \phi_i \qquad\text{(7)}\
\phi_k \sum^k_{i=1} e^{\eta_i}&= \sum^k_{i=1}\phi_i= 1\
\end{aligned}
$$
这就说明了$\phi_k = \frac 1 {\sum^k_{i=1} e^{\eta_i}}$,然后可以把这个关系代入回到等式$(7)$,这样就得到了响应函数:
$$
\phi_i = \frac { e^{\eta_i} }{ \sum^k_{j=1} e^{\eta_j}}
$$
上面这个函数从$\eta$ 映射到了$\phi$,称为 Softmax 函数。
要完成我们的建模,还要用到前文提到的假设3,也就是 $\eta_i$ 是一个 $x$ 的线性函数。所以就有了 $\eta_i= \theta_i^Tx (for\quad i = 1, …, k − 1)$,其中的 $\theta_1, …, \theta_{k−1} \in R^{n+1}$ 就是我们建模的参数。为了表述方便,我们这里还是定义$\theta_k = 0$,这样就有 $\eta_k = \theta_k^T x = 0$,跟前文提到的相符。因此,我们的模型假设了给定 $x$ 的 $y$ 的条件分布为:
$$
\begin{aligned}
p(y=i|x;\theta) &= \phi_i \
&= \frac {e^{\eta_i}}{\sum^k_{j=1}e^{\eta_j}}\
&=\frac {e^{\theta_i^Tx}}{\sum^k_{j=1}e^{\theta_j^Tx}}\qquad\text{(8)}\
\end{aligned}
$$
这个适用于解决 $y \in{1, …, k}$ 的分类问题的模型,就叫做 Softmax 回归。 这种回归是对逻辑回归的一种扩展泛化。
假设(hypothesis) $h$ 则如下所示:
$$
\begin{aligned}
h_\theta (x) &= E[T(y)|x;\theta]\
&= E \left[
\begin{array}{cc|c}
1(y=1)\
1(y=2)\
\vdots \
1(y=k-1)\
\end{array}x;\theta
\right]\
&= E \left[
\begin{array}{c}
\phi_1\
\phi_2\
\vdots \
\phi_{k-1}\
\end{array}
\right]\
&= E \left[
\begin{array}{ccc}
\frac {exp(\theta_1^Tx)}{\sum^k_{j=1}exp(\theta_j^Tx)} \
\frac {exp(\theta_2^Tx)}{\sum^k_{j=1}exp(\theta_j^Tx)} \
\vdots \
\frac {exp(\theta_{k-1}^Tx)}{\sum^k_{j=1}exp(\theta_j^Tx)} \
\end{array}
\right]\
\end{aligned}
$$
也就是说,我们的假设函数会对每一个 $i = 1,…,k$ ,给出 $p (y = i|x; \theta)$ 概率的估计值。(虽然咱们在前面假设的这个 $h_\theta(x)$ 只有 $k-1$ 维,但很明显 $p (y = k|x; \theta)$ 可以通过用 $1$ 减去其他所有项目概率的和来得到,即$1− \sum^{k-1}_{i=1}\phi_i$。)
最后,咱们再来讲一下参数拟合。和我们之前对普通最小二乘线性回归和逻辑回归的原始推导类似,如果咱们有一个有 $m$ 个训练样本的训练集 ${(x^{(i)}, y^{(i)}); i = 1, …, m}$,然后要研究这个模型的参数 $\theta_i$ ,我们可以先写出其似然函数的对数:
$$
\begin{aligned}
l(\theta)& =\sum^m_{i=1} \log p(y^{(i)}|x^{(i)};\theta)\
&= \sum^m_{i=1}log\prod ^k_{l=1}(\frac {e^{\theta_l^Tx^{(i)}}}{\sum^k_{j=1} e^{\theta_j^T x^{(i)}}})^{1(y^{(i)}=l)}\
\end{aligned}
$$
要得到上面等式的第二行,要用到等式$(8)$中的设定 $p(y|x; \theta)$。现在就可以通过对 $l(\theta)$ 取最大值得到的 $\theta$ 而得到对参数的最大似然估计,使用的方法就可以用梯度上升法或者牛顿法了。
第二章
第四部分 生成学习算法(Generative Learning algorithms)
目前为止,我们讲过的学习算法的模型都是$p (y|x;\theta)$,也就是给定 $x$ 下 $y$ 的条件分布,以 $\theta$ 为参数。例如,逻辑回归中就是以 $h_\theta(x) = g(\theta^T x)$ 作为 $p (y|x;\theta)$ 的模型,这里的 $g$ 是一个 $S$型函数(sigmoid function)。接下来,咱们要讲一下一种不同类型的学习算法。
设想有这样一种分类问题,我们要学习基于一个动物的某个特征来辨别它是大象$(y=1)$还是小狗$(y=0)$。给定一个训练集,用逻辑回归或者基础版的感知器算法(perceptron algorithm) 这样的一个算法能找到一条直线,作为区分开大象和小狗的边界。接下来,要辨别一个新的动物是大象还是小狗,程序就要检查这个新动物的值落到了划分出来的哪个区域中,然后根据所落到的区域来给出预测。
还有另外一种方法。首先,观察大象,然后我们针对大象的样子来进行建模。然后,再观察小狗,针对小狗的样子另外建立一个模型。最后要判断一种新动物归属哪一类,我们可以把新动物分别用大象和小狗的模型来进比对,看看新动物更接近哪个训练集中已有的模型。
例如逻辑回归之类的直接试图建立 $p(y|x)$的算法,以及感知器算法(perceptron algorithm)等直接用投图(mappings directly)的思路来判断对应 $X$ 的值落到了 ${0, 1}$ 中哪个区域的算法,这些都叫判别式学习算法(discriminative learning algorithms)。 和之前的这些判别式算法不同,下面我们要讲的新算法是对 $p(x|y)$ 和 $p(y)$来进行建模。这类算法叫做生成学习算法(generative learning algorithms)。例如如果 $y$ 用来表示一个样例是 小狗 $(0)$ 或者 大象 $(1)$,那么$p(x|y = 0)$就是对小狗特征分布的建模,而$p(x|y = 1)$就是对大象特征分布的建模。
对 $p(y)$ (通常称为class priors译者注:这里没有找到合适的词进行翻译) 和$p(x|y)$ 进行建模之后,我们的算法就是用贝叶斯规则(Bayes rule) 来推导对应给定 $x$ 下 $y$ 的后验分布(posterior distribution):
$$
p(y|x)=\frac{p(x|y)p(y)}{p(x)}
$$
这里的分母(denominator) 为:$p(x) = p(x|y = 1)p(y = 1) + p(x|y = 0)p(y = 0)$(这个等式关系可以根据概率的标准性质来推导验证译者注:其实就是条件概率),这样接下来就可以把它表示成我们熟悉的 $p(x|y)$和 $p(y)$ 的形式了。实际上如果我们计算$p(y|x)$ 来进行预测,那就并不需要去计算这个分母,因为有下面的等式关系:
$$\begin{aligned}
\arg \max_y p(y|x) & =\arg \max_y \frac{p(x|y)p(y)}{p(x)}\
&= \arg \max_y p(x|y)p(y)
\end{aligned}$$
1 高斯判别分析(Gaussian discriminant analysis)
咱们要学的第一个生成学习算法就是高斯判别分析(Gaussian discriminant analysis ,缩写为GDA。译者注:高斯真棒!)在这个模型里面,我们假设 $p(x|y)$是一个多元正态分布。 所以首先咱们简单讲一下多元正态分布的一些特点,然后再继续讲 GDA 高斯判别分析模型。
1.1 多元正态分布(multivariate normal distribution)
$n$维多元正态分布,也叫做多变量高斯分布,参数为一个$n$维 均值向量 $\mu \in R^n $,以及一个 协方差矩阵 $\Sigma \in R^{n\times n}$,其中$\Sigma \geq 0$ 是一个对称(symmetric)的半正定(positive semi-definite)矩阵。当然也可以写成”$N (\mu, \Sigma)$” 的分布形式,密度(density)函数为:
$$
p(x;\mu,\Sigma)=\frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}} exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu))
$$
在上面的等式中,”$|\Sigma|$”的意思是矩阵$\Sigma$的行列式(determinant)。对于一个在 $N(\mu,\Sigma)$分布中的随机变量 $X$ ,其平均值(跟正态分布里面差不多,所以并不意外)就是 $\mu$ 了:
$$
E[X]=\int_x xp(x;\mu,\Sigma)dx=\mu
$$
随机变量$Z$是一个有值的向量(vector-valued random variable),$Z$ 的 协方差(covariance) 的定义是:$Cov(Z) = E[(Z-E[Z])(Z-E[Z])^T ]$。这是对实数随机变量的方差(variance)这一概念的泛化扩展。这个协方差还可以定义成$Cov(Z) = E[ZZ^T]-(E[Z])(E[Z])^T$(你可以自己证明一下这两个定义实际上是等价的。)如果 $X$ 是一个多变量正态分布,即 $X \sim N (\mu, \Sigma)$,则有:
$$
Cov(X)=\Sigma
$$
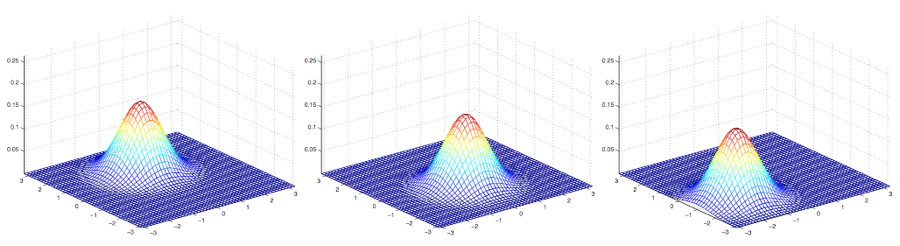
下面这些样例是一些高斯分布的密度图,如下图所示:
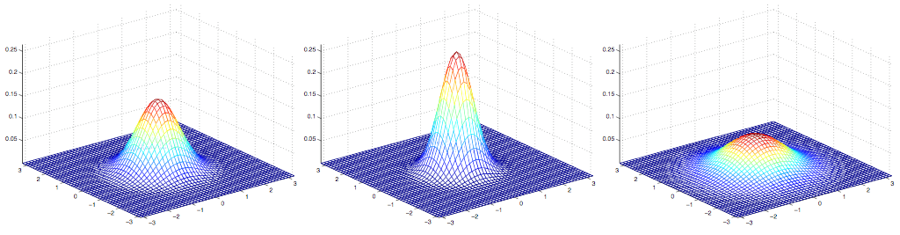
最左边的图,展示的是一个均值为$0$(实际上是一个$2\times 1$ 的零向量)的高斯分布,协方差矩阵就是$\Sigma = I$ (一个 $2\times 2$的单位矩阵,identity matrix)。这种均值为$0$ 并且协方差矩阵为单位矩阵的高斯分布也叫做标准正态分布。 中间的图中展示的是均值为$0$而协方差矩阵是$0.6I$ 的高斯分布的概率密度函数;最右边的展示的是协方差矩阵$\Sigma = 2I$的高斯分布的概率密度函数。从这几个图可以看出,随着协方差矩阵$\Sigma$变大,高斯分布的形态就变得更宽平(spread-out),而如果协方差矩阵$\Sigma$变小,分布就会更加集中(compressed)。
来看一下更多的样例:
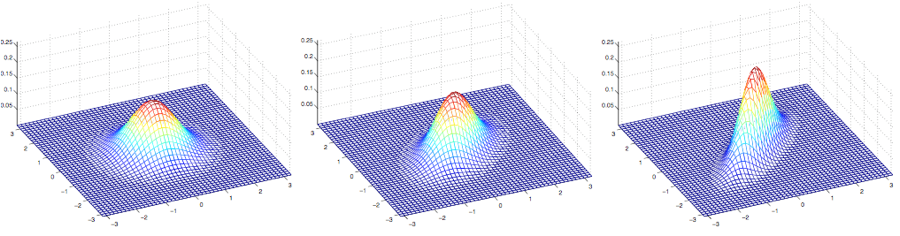
上面这几个图展示的是均值为$0$,但协方差矩阵各不相同的高斯分布,其中的协方差矩阵依次如下所示:
$$
\Sigma =\begin{bmatrix}
1 & 0 \ 0 & 1 \ \end{bmatrix};
\Sigma =\begin{bmatrix}
1 & 0.5 \ 0.5 & 1 \
\end{bmatrix};
\Sigma =\begin{bmatrix}
1 & 0.8 \ 0.8 & 1 \
\end{bmatrix}
$$
第一幅图还跟之前的标准正态分布的样子很相似,然后我们发现随着增大协方差矩阵$\Sigma$ 的反对角线(off-diagonal)的值,密度图像开始朝着 45° 方向 (也就是 $x_1 = x_2$ 所在的方向)逐渐压缩(compressed)。 看一下三个同样分布密度图的轮廓图(contours)能看得更明显:
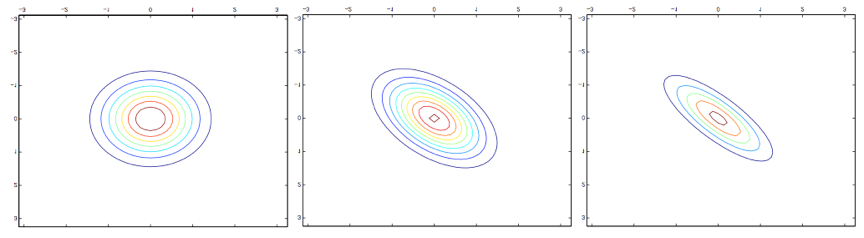
下面的是另外一组样例,调整了协方差矩阵$\Sigma$:
$$
\Sigma =\begin{bmatrix}
1 & 0.5 \ 0.5 & 1 \
\end{bmatrix};
\Sigma =\begin{bmatrix}
1 & 0.8 \ 0.8 & 1 \
\end{bmatrix}
\Sigma =\begin{bmatrix}
3 & 0.8 \ 0.8 & 1 \ \end{bmatrix};
$$
上面这三个图像对应的协方差矩阵分别如下所示:
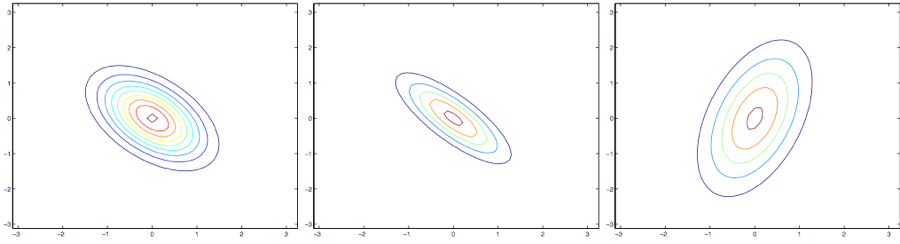
从最左边的到中间译者注:注意,左边和中间的这两个协方差矩阵中,右上和左下的元素都是负值!很明显随着协方差矩阵中右上左下这个对角线方向元素的值的降低,图像还是又被压扁了(compressed),只是方向是反方向的。最后,随着我们修改参数,通常生成的轮廓图(contours)都是椭圆(最右边的图就是一个例子)。
再举一些例子,固定协方差矩阵为单位矩阵,即$\Sigma = I$,然后调整均值$\mu$,我们就可以让密度图像随着均值而移动:
上面的图像中协方差矩阵都是单位矩阵,即 $\Sigma = I$,对应的均值$\mu$如下所示:
$$
\mu =\begin{bmatrix}
1 \ 0 \
\end{bmatrix};
\mu =\begin{bmatrix}
-0.5 \ 0 \
\end{bmatrix};
\mu =\begin{bmatrix}
-1 \ -1.5 \
\end{bmatrix};
$$
1.2 高斯判别分析模型(Gaussian Discriminant Analysis model)
假如我们有一个分类问题,其中输入特征 $x$ 是一系列的连续随机变量(continuous-valued random variables),那就可以使用高斯判别分析(Gaussian Discriminant Analysis ,缩写为 GDA)模型,其中对 $p(x|y)$用多元正态分布来进行建模。这个模型为:
$$
\begin{aligned}
y & \sim Bernoulli(\phi)\
x|y = 0 & \sim N(\mu_o,\Sigma)\
x|y = 1 & \sim N(\mu_1,\Sigma)\
\end{aligned}
$$
分布写出来的具体形式如下:
$$
\begin{aligned}
p(y) & =\phi^y (1-\phi)^{1-y}\
p(x|y=0) & = \frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}} exp ( - \frac{1}{2}(x-\mu_0)^T\Sigma^{-1}(x-\mu_0) )\
p(x|y=1) & = \frac{1}{(2\pi)^{n/2}|\Sigma|^{1/2}} exp ( - \frac{1}{2}(x-\mu_1)^T\Sigma^{-1}(x-\mu_1) )\
\end{aligned}
$$
在上面的等式中,模型的参数包括$\phi, \Sigma, \mu_0 和 \mu_1$。(要注意,虽然这里有两个不同方向的均值向量$\mu_0$ 和 $\mu_1$,针对这个模型还是一般只是用一个协方差矩阵$\Sigma$。)取对数的似然函数(log-likelihood)如下所示:
$$
\begin{aligned}
l(\phi,\mu_0,\mu_1,\Sigma) &= \log \prod^m_{i=1}p(x^{(i)},y^{(i)};\phi,\mu_0,\mu_1,\Sigma)\
&= \log \prod^m_{i=1}p(x^{(i)}|y^{(i)};\mu_0,\mu_1,\Sigma)p(y^{(i)};\phi)\
\end{aligned}
$$
通过使 $l$ 取得最大值,找到对应的参数组合,然后就能找到该参数组合对应的最大似然估计,如下所示(参考习题集1):
$$
\begin{aligned}
\phi & = \frac {1}{m} \sum^m_{i=1}1{y^{(i)}=1}\
\mu_0 & = \frac{\sum^m_{i=1}1{y^{(i)}=0}x^{(i)}}{\sum^m_{i=1}1{y^{(i)}=0}}\
\mu_1 & = \frac{\sum^m_{i=1}1{y^{(i)}=1}x^{(i)}}{\sum^m_{i=1}1{y^{(i)}=1}}\
\Sigma & = \frac{1}{m}\sum^m_{i=1}(x^{(i)}-\mu_{y^{(i)}})(x^{(i)}-\mu_{y^{(i)}})^T\
\end{aligned}
$$
用图形化的方式来表述,这个算法可以按照下面的图示所表示:
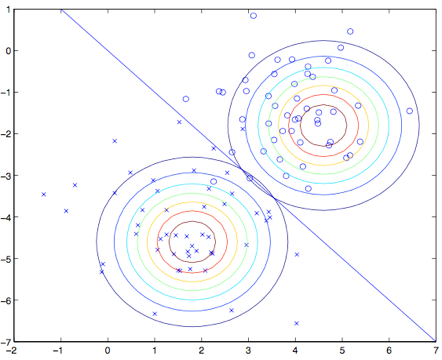
图中展示的点就是训练数据集,图中的两个高斯分布就是针对两类数据各自进行的拟合。要注意这两个高斯分布的轮廓图有同样的形状和拉伸方向,这是因为他们都有同样的协方差矩阵$\Sigma$,但他们有不同的均值$\mu_0$ 和 $\mu_1$ 。此外,图中的直线给出了$p (y = 1|x) = 0.5$ 这条边界线。在这条边界的一侧,我们预测 $y = 1$是最可能的结果,而另一侧,就预测 $y = 0$是最可能的结果。
1.3 讨论:高斯判别分析(GDA)与逻辑回归(logistic regression)
高斯判别分析模型与逻辑回归有很有趣的相关性。如果我们把变量(quantity)$p (y = 1|x; \phi, \mu_0, \mu_1, \Sigma)$ 作为一个 $x$ 的函数,就会发现可以用如下的形式来表达:
$$
p(y=1|x;\phi,\Sigma,\mu_0,\mu_1)=\frac 1 {1+exp(-\theta^Tx)}
$$
其中的 $\theta$ 是对$\phi$, $\Sigma$, $\mu_0$, $\mu_1$的某种函数。这就是逻辑回归(也是一种判别分析算法)用来对$p (y = 1|x)$ 建模的形式。
注:上面这里用到了一种转换,就是重新对$x^{(i)}$向量进行了定义,在右手侧(right-hand-side)增加了一个额外的坐标$x_0^{(i)} = 1$,然后使之成为了一个 $n+1$维的向量;具体内容参考习题集1。
这两个模型中什么时候该选哪一个呢?一般来说,高斯判别分析(GDA)和逻辑回归,对同一个训练集,可能给出的判别曲线是不一样的。哪一个更好些呢?
我们刚刚已经表明,如果$p(x|y)$是一个多变量的高斯分布(且具有一个共享的协方差矩阵$\Sigma$),那么$p(y|x)$则必然符合一个逻辑函数(logistic function)。然而,反过来,这个命题是不成立的。例如假如$p(y|x)$是一个逻辑函数,这并不能保证$p(x|y)$一定是一个多变量的高斯分布。这就表明高斯判别模型能比逻辑回归对数据进行更强的建模和假设(stronger modeling assumptions)。 这也就意味着,在这两种模型假设都可用的时候,高斯判别分析法去拟合数据是更好的,是一个更好的模型。 尤其当$p(x|y)$已经确定是一个高斯分布(有共享的协方差矩阵$\Sigma$),那么高斯判别分析是渐进有效的(asymptotically efficient)。 实际上,这也意味着,在面对非常大的训练集(训练样本规模 $m $特别大)的时候,严格来说,可能就没有什么别的算法能比高斯判别分析更好(比如考虑到对 $p(y|x)$估计的准确度等等)。所以在这种情况下就表明,高斯判别分析(GDA)是一个比逻辑回归更好的算法;再扩展一下,即便对于小规模的训练集,我们最终也会发现高斯判别分析(GDA)是更好的。
奈何事有正反,由于逻辑回归做出的假设要明显更弱一些(significantly weaker),所以因此逻辑回归给出的判断鲁棒性(robust)也更强,同时也对错误的建模假设不那么敏感。有很多不同的假设集合都能够将$p(y|x)$引向逻辑回归函数。例如,如果$x|y = 0\sim Poisson(\lambda_0)$ 是一个泊松分布,而$x|y = 1\sim Poisson(\lambda_1)$也是一个泊松分布,那么$p(y|x)$也将是适合逻辑回归的(logistic)。逻辑回归也适用于这类的泊松分布的数据。但对这样的数据,如果我们强行使用高斯判别分析(GDA),然后用高斯分布来拟合这些非高斯数据,那么结果的可预测性就会降低,而且GDA这种方法也许可行,也有可能是不能用。
总结一下也就是:高斯判别分析方法(GDA)能够建立更强的模型假设,并且在数据利用上更加有效(比如说,需要更少的训练集就能有”还不错的”效果),当然前提是模型假设争取或者至少接近正确。逻辑回归建立的假设更弱,因此对于偏离的模型假设来说更加鲁棒(robust)。然而,如果训练集数据的确是非高斯分布的(non-Gaussian),而且是有限的大规模数据(in the limit of large datasets),那么逻辑回归几乎总是比GDA要更好的。因此,在实际中,逻辑回归的使用频率要比GDA高得多。(关于判别和生成模型的对比的相关讨论也适用于我们下面要讲的朴素贝叶斯算法(Naive Bayes),但朴素贝叶斯算法还是被认为是一个非常优秀也非常流行的分类算法。)
2 朴素贝叶斯法(Naive Bayes)
在高斯判别分析(GDA)方法中,特征向量 $x$ 是连续的,值为实数的向量。下面我们要讲的是当 $x_i$ 是离散值的时候来使用的另外一种学习算法。
下面就来继续看一个之前见过的样例,来尝试建立一个邮件筛选器,使用机器学习的方法。这回咱们要来对邮件信息进行分类,来判断是否为商业广告邮件(就是垃圾邮件),还是非垃圾邮件。在学会了怎么实现之后,我们就可以让邮件阅读器能够自动对垃圾信息进行过滤,或者单独把这些垃圾邮件放进一个单独的文件夹中。对邮件进行分类是一个案例,属于文本分类这一更广泛问题集合。
假设我们有了一个训练集(也就是一堆已经标好了是否为垃圾邮件的邮件)。要构建垃圾邮件分选器,咱们先要开始确定用来描述一封邮件的特征$x_i$有哪些。
我们将用一个特征向量来表示一封邮件,这个向量的长度等于字典中单词的个数。如果邮件中包含了字典中的第 $i$ 个单词,那么就令 $x_i = 1$;反之则$x_i = 0$。例如下面这个向量:
$$
x=\begin{bmatrix}1\0\0\\vdots \1\ \vdots \0\end{bmatrix} \begin{matrix}\text{a}\ \text{aardvark}\ \text{aardwolf}\ \vdots\ \text{buy}\ \vdots\ \text{zygmurgy}\ \end{matrix}
$$
就用来表示一个邮件,其中包含了两个单词 “a” 和 “buy”,但没有单词 “aardvark”, “aardwolf” 或者 “zymurgy” 。这个单词集合编码整理成的特征向量也成为词汇表(vocabulary,), 所以特征向量 $x$ 的维度就等于词汇表的长度。
注:实际应用中并不需要遍历整个英语词典来组成所有英语单词的列表,实践中更常用的方法是遍历一下训练集,然后把出现过一次以上的单词才编码成特征向量。这样做除了能够降低模型中单词表的长度之外,还能够降低运算量和空间占用,此外还有一个好处就是能够包含一些你的邮件中出现了而词典中没有的单词,比如本课程的缩写CS229。有时候(比如在作业里面),还要排除一些特别高频率的词汇,比如像冠词the,介词of 和and 等等;这些高频率但是没有具体意义的虚词也叫做stop words,因为很多文档中都要有这些词,用它们也基本不能用来判定一个邮件是否为垃圾邮件。
选好了特征向量了,接下来就是建立一个生成模型(generative model)。所以我们必须对$p(x|y)$进行建模。但是,假如我们的单词有五万个词,则特征向量$x \in {0, 1}^{50000}$ (即 $x$是一个 $50000$ 维的向量,其值是$0$或者$1$),如果我们要对这样的 $x$进行多项式分布的建模,那么就可能有$2^{50000}$ 种可能的输出,然后就要用一个 $(2^{50000}-1)$维的参数向量。这样参数明显太多了。
要给$p(x|y)$建模,先来做一个非常强的假设。我们假设特征向量$x_i$ 对于给定的 $y$ 是独立的。 这个假设也叫做朴素贝叶斯假设(Naive Bayes ,NB assumption), 基于此假设衍生的算法也就叫做朴素贝叶斯分类器(Naive Bayes classifier)。 例如,如果 $y = 1$ 意味着一个邮件是垃圾邮件;然后其中”buy” 是第$2087$个单词,而 “price”是第$39831$个单词;那么接下来我们就假设,如果我告诉你 $y = 1$,也就是说某一个特定的邮件是垃圾邮件,那么对于$x_{2087}$ (也就是单词 buy 是否出现在邮件里)的了解并不会影响你对$x_{39831}$ (单词price出现的位置)的采信值。更正规一点,可以写成 $p(x_{2087}|y) = p(x_{2087}|y, x_{39831})$。(要注意这个并不是说$x_{2087}$ 和 $x_{39831}$这两个特征是独立的,那样就变成了$p(x_{2087}) = p(x_{2087}|x_{39831})$,我们这里是说在给定了 $y$ 的这样一个条件下,二者才是有条件的独立。)
然后我们就得到了等式:
$$
\begin{aligned}
p(x_1, …, x_{50000}|y) & = p(x_1|y)p(x_2|y,x_1)p(x_3|y,x_1,x_2) … p(x_{50000}|y,x_1,x_2,…,x_{49999})\
& = p(x_1|y)p(x_2|y)p(x_3|y) … p(x_{50000}|y)\
& = \prod^n_{i=1}p(x_i|y)\
\end{aligned}
$$
第一行的等式就是简单地来自概率的基本性质,第二个等式则使用了朴素贝叶斯假设。这里要注意,朴素贝叶斯假设也是一个很强的假设,产生的这个算法可以适用于很多种问题。
我们这个模型的参数为 $\phi_{i|y=1} = p (x_i = 1|y = 1), \phi_{i|y=0} = p (x_i = 1|y = 0)$, 而 $\phi_y = p (y = 1)$。和以往一样,给定一个训练集${(x^{(i)},y^{(i)}); i = 1, …, m}$,就可以写出下面的联合似然函数:
$$
\mathcal{L}(\phi_y,\phi_{j|y=0},\phi_{j|y=1})=\prod^m_{i=1}p(x^{(i)},y^{(i)})
$$
找到使联合似然函数取得最大值的对应参数组合 $\phi_y , \phi_{i|y=0} 和 \phi_{i|y=1}$ 就给出了最大似然估计:
$$
\begin{aligned}
\phi_{j|y=1} &=\frac{\sum^m_{i=1}1{x_j^{(i)} =1 \wedge y^{(i)} =1} }{\sum^m_{i=1}1{y^{(i)} =1}} \
\phi_{j|y=0} &= \frac{\sum^m_{i=1}1{x_j^{(i)} =1 \wedge y^{(i)} =0} }{\sum^m_{i=1}1{y^{(i)} =0}} \
\phi_{y} &= \frac{\sum^m_{i=1}1{y^{(i)} =1}}{m}\
\end{aligned}
$$
在上面的等式中,”$\wedge$(and)”这个符号的意思是逻辑”和”。这些参数有一个非常自然的解释。例如 $\phi_{j|y=1}$ 正是垃圾 $(y = 1)$ 邮件中出现单词 $j$ 的邮件所占的比例。
拟合好了全部这些参数之后,要对一个新样本的特征向量 $x$ 进行预测,只要进行如下的简单地计算:
$$
\begin{aligned}
p(y=1|x)&= \frac{p(x|y=1)p(y=1)}{p(x)}\
&= \frac{(\prod^n_{i=1}p(x_i|y=1))p(y=1)}{(\prod^n_{i=1}p(x_i|y=1))p(y=1)+ (\prod^n_{i=1}p(x_i|y=0))p(y=0)} \
\end{aligned}
$$
然后选择有最高后验概率的概率。
最后我们要注意,刚刚我们对朴素贝叶斯算法的使用中,特征向量 $x_i$ 都是二值化的,其实特征向量也可以是多个离散值,比如${1, 2, …, k_i}$这样也都是可以的。这时候只需要把对$p(x_i|y)$ 的建模从伯努利分布改成多项式分布。实际上,即便一些原始的输入值是连续值(比如我们第一个案例中的房屋面积),也可以转换成一个小规模的离散值的集合,然后再使用朴素贝叶斯方法。例如,如果我们用特征向量 $x_i$ 来表示住房面积,那么就可以按照下面所示的方法来对这一变量进行离散化:
| 居住面积 | $<400$ | $400-800$ | $800-1200$ | $1200-1600$ | $>1600$ |
|---|---|---|---|---|---|
| 离散值 $x_i$ | $1$ | $2$ | $3$ | $4$ | $5$ |
这样,对于一个面积为 $890$ 平方英尺的房屋,就可以根据上面这个集合中对应的值来把特征向量的这一项的$x_i$值设置为$3$。然后就可以用朴素贝叶斯算法,并且将$p(x_i|y)$作为多项式分布来进行建模,就都跟前面讲过的内容一样了。当原生的连续值的属性不太容易用一个多元正态分布来进行建模的时候,将其特征向量离散化然后使用朴素贝叶斯法(NB)来替代高斯判别分析法(GDA),通常能形成一个更好的分类器。
2.1 拉普拉斯平滑(Laplace smoothing)
刚刚讲过的朴素贝叶斯算法能够解决很多问题了,但还能对这种方法进行一点小调整来进一步提高效果,尤其是应对文本分类的情况。我们来简要讨论一下一个算法当前状态的一个问题,然后在讲一下如何解决这个问题。
还是考虑垃圾邮件分类的过程,设想你学完了CS229的课程,然后做了很棒的研究项目,之后你决定在$2003$年$6$月译者注:作者这讲义一定写得很早把自己的作品投稿到NIPS会议,这个NIPS是机器学习领域的一个顶级会议,递交论文的截止日期一般是六月末到七月初。你通过邮件来对这个会议进行了讨论,然后你也开始收到带有 nips 四个字母的信息。但这个是你第一个NIPS论文,而在此之前,你从来没有接到过任何带有 nips 这个单词的邮件;尤其重要的是,nips 这个单词就从来都没有出现在你的垃圾/正常邮件训练集里面。假如这个 nips 是你字典中的第$35000$个单词,那么你的朴素贝叶斯垃圾邮件筛选器就要对参数$\phi_{35000|y}$ 进行最大似然估计,如下所示:
$$
\begin{aligned}
\phi_{35000|y=1} &= \frac{\sum^m_{i=1}1{x^{(i)}{35000}=1 \wedge y^{(i)}=1 }}{\sum^m{i=1}1{y^{(i)}=0}} &=0 \
\phi_{35000|y=0} &= \frac{\sum^m_{i=1}1{x^{(i)}{35000}=1 \wedge y^{(i)}=0 }}{\sum^m{i=1}1{y^{(i)}=0}} &=0 \
\end{aligned}
$$
也就是说,因为之前程序从来没有在别的垃圾邮件或者正常邮件的训练样本中看到过 nips 这个词,所以它就认为看到这个词出现在这两种邮件中的概率都是$0$。因此当要决定一个包含 nips 这个单词的邮件是否为垃圾邮件的时候,他就检验这个类的后验概率,然后得到了:
$$
\begin{aligned}
p(y=1|x) &= \frac{ \prod^n_{i=1} p(x_i|y=1)p(y=1) } {\prod^n_{i=1} p(x_i|y=1)p(y=1) +\prod^n_{i=1} p(x_i|y=0)p(y=0) }\
&= \frac00\
\end{aligned}
$$
这是因为对于” $\prod^n_{i=1} p(x_i|y)$”中包含了$p(x_{35000}|y) = 0$的都加了起来,也就还是$0$。所以我们的算法得到的就是 $\frac00$,也就是不知道该做出怎么样的预测了。
然后进一步拓展一下这个问题,统计学上来说,只因为你在自己以前的有限的训练数据集中没见到过一件事,就估计这个事件的概率为零,这明显不是个好主意。假设问题是估计一个多项式随机变量 $z$ ,其取值范围在${1,…, k}$之内。接下来就可以用$\phi_i = p (z = i)$ 来作为多项式参数。给定一个 $m$ 个独立观测${z^{(1)}, …, z^{(m)}}$ 组成的集合,然后最大似然估计的形式如下:
$$
\phi_j=\frac{\sum^m_{i=1}1{z^{(i)}=j}}m
$$
正如咱们之前见到的,如果我们用这些最大似然估计,那么一些$\phi_j$可能最终就是零了,这就是个问题了。要避免这个情况,咱们就可以引入拉普拉斯平滑(Laplace smoothing), 这种方法把上面的估计替换成:
$$
\phi_j=\frac{\sum^m_{i=1}1{z^{(i)}=j}+1}{m+k}
$$
这里首先是对分子加$1$,然后对分母加$k$,要注意$\sum^k_{j=1} \phi_j = 1$依然成立(自己检验一下),这是一个必须有的性质,因为$\phi_j$ 是对概率的估计,然后所有的概率加到一起必然等于$1$。另外对于所有的 $j$ 值,都有$\phi_j \neq 0$,这就解决了刚刚的概率估计为零的问题了。在某些特定的条件下(相当强的假设条件下,arguably quite strong),可以发现拉普拉斯平滑还真能给出对参数$\phi_j$ 的最佳估计(optimal estimator)。
回到我们的朴素贝叶斯分选器问题上,使用了拉普拉斯平滑之后,对参数的估计就写成了下面的形式:
$$
\begin{aligned}
\phi_{j|y=1} & =\frac{\sum^m_{i=1}1{x_j^{(i)}=1\wedge y ^{(i)}=1}+1}{\sum^m_{i=1}1{y^{(i)}=1}+2}\
\phi_{j|y=0} & =\frac{\sum^m_{i=1}1{x_j^{(i)}=1\wedge y ^{(i)}=0}+1}{\sum^m_{i=1}1{y^{(i)}=0}+2}\
\end{aligned}
$$
(在实际应用中,通常是否对$\phi_y$ 使用拉普拉斯并没有太大影响,因为通常我们会对每个垃圾邮件和非垃圾邮件都有一个合适的划分比例,所以$\phi_y$ 会是对$p(y = 1)$ 的一个合理估计,无论如何都会与零点有一定距离。)
2.2 针对文本分类的事件模型(Event models for text classification)
到这里就要给咱们关于生成学习算法的讨论进行一下收尾了,所以就接着讲一点关于文本分类方面的另一个模型。我们刚已经演示过的朴素贝叶斯方法能够解决很多分类问题了,不过还有另一个相关的算法,在针对文本的分类效果还要更好。
在针对文本进行分类的特定背景下,咱们上面讲的朴素贝叶斯方法使用的是一种叫做多元伯努利事件模型(Multi-Variate Bernoulli event model)。 在这个模型里面,我们假设邮件发送的方式,是随机确定的(根据先验类class priors, $p(y)$),无论是不是垃圾邮件发送者,他是否给你发下一封邮件都是随机决定的。那么发件人就会遍历词典,决定在邮件中是否包含某个单词 $i$,各个单词之间互相独立,并且服从概率分布$p(x_i=1|y)=\phi_{i|y}$。因此,一条消息的概率为:$p(y)\prod^n_{i-1}p(x_i|y)$
然后还有另外一个模型,叫做多项式事件模型(Multinomial event model)。 要描述这个模型,我们需要使用一个不同的记号和特征集来表征各种邮件。设 $x_i$ 表示单词中的第$i$个单词。因此,$x_i$现在就是一个整数,取值范围为${1,…,|V|}$,这里的$|V|$是词汇列表(即字典)的长度。这样一个有 $n$ 个单词的邮件就可以表征为一个长度为 $n$ 的向量$(x_1,x_2,…,x_n)$;这里要注意,不同的邮件内容,$n$ 的取值可以是不同的。例如,如果一个邮件的开头是”A NIPS . . .” ,那么$x_1 = 1$ (“a” 是词典中的第一个),而$x_2 = 35000$ (这是假设 “nips”是词典中的第35000个)。
在多项式事件模型中,我们假设邮件的生成是通过一个随机过程的,而是否为垃圾邮件是首先决定的(根据$p(y)$),这个和之前的模型假设一样。然后邮件的发送者写邮件首先是要生成 从对单词$(p(x_1|y))$ 的某种多项式分布中生成 $x_1$。然后第二步是独立于 $x_1$ 来生成 $x_2$,但也是从相同的多项式分布中来选取,然后是 $x_3$,$x_4$ 等等,以此类推,直到生成了整个邮件中的所有的词。因此,一个邮件的总体概率就是$p(y)\prod^n_{i=1}p(x_i|y)$。要注意这个方程看着和我们之前那个多元伯努利事件模型里面的邮件概率很相似,但实际上这里面的意义完全不同了。尤其是这里的$x_i|y$现在是一个多项式分布了,而不是伯努利分布了。
我们新模型的参数还是$\phi_y = p(y)$,这个跟以前一样,然后还有$\phi_{k|y=1} = p(x_j =k|y=1)$ (对任何 $j$)以及 $\phi_{i|y=0} =p(x_j =k|y=0)$。要注意这里我们已经假设了对于任何$j$ 的值,$p(x_j|y)$这个概率都是相等的,也就是意味着在这个哪个词汇生成的这个分布不依赖这个词在邮件中的位置$j$。
如果给定一个训练集${(x^{(i)},y^{(i)}); i = 1, …, m}$,其中 $x^{(i)} = ( x^{(i)}{1} , x^{(i)}{2} ,…, x^{(i)}_{n_i})$(这里的$n$是在第$i$个训练样本中的单词数目),那么这个数据的似然函数如下所示:
$$
\begin{aligned}
\mathcal{L}(\phi,\phi_{k|y=0},\phi_{k|y=1})& = \prod^m_{i=1}p( x^{(i)},y^{(i)})\
& = \prod^m_{i=1}(\prod^{n_i}{j=1}p(x_j^{(i)}|y;\phi{k|y=0},\phi_{k|y=1}))p( y^{(i)};\phi_y)\
\end{aligned}
$$
让上面的这个函数最大化就可以产生对参数的最大似然估计:
$$
\begin{aligned}
\phi_{k|y=1}&= \frac{\sum^m_{i=1}\sum^{n_i}{j=1}1{x_j^{(i)}=k\wedge y^{(i)}=1}}{\sum^m{i=1}1{y^{(i)}=1}n_i} \
\phi_{k|y=0}&= \frac{\sum^m_{i=1}\sum^{n_i}{j=1}1{x_j^{(i)}=k\wedge y^{(i)}=0}}{\sum^m{i=1}1{y^{(i)}=0}n_i} \
\phi_y&= \frac{\sum^m_{i=1}1{y^{(i)}=1}}{m}\
\end{aligned}
$$
如果使用拉普拉斯平滑(实践中会用这个方法来提高性能)来估计$\phi_{k|y=0}$ 和 $\phi_{k|y=1}$,就在分子上加1,然后分母上加$|V|$,就得到了下面的等式:
$$
\begin{aligned}
\phi_{k|y=1}&= \frac{\sum^m_{i=1}\sum^{n_i}{j=1}1{x_j^{(i)}=k\wedge y^{(i)}=1}+1}{\sum^m{i=1}1{y^{(i)}=1}n_i+|V|} \
\phi_{k|y=0}&= \frac{\sum^m_{i=1}\sum^{n_i}{j=1}1{x_j^{(i)}=k\wedge y^{(i)}=0}+1}{\sum^m{i=1}1{y^{(i)}=0}n_i+|V|} \
\end{aligned}
$$
当然了,这个并不见得就是一个最好的分类算法,不过朴素贝叶斯分选器通常用起来还都出乎意料地那么好。所以这个方法就是一个很好的”首发选择”,因为它很简单又很好实现。
第三章
第五部分 支持向量机(Support Vector Machines)
本章的讲义主要讲述的是 支持向量机(Support Vector Machine ,缩写为 SVM) 学习算法。SVM 算得上是现有的最好的现成的(“off-the-shelf”)监督学习算法之一,很多人实际上认为这里没有“之一”这两个字的必要,认为 SVM 就是最好的现成的监督学习算法。讲这个 SVM 的来龙去脉之前,我们需要先讲一些关于边界的内容,以及对数据进行分割成大的区块(gap)的思路。接下来,我们要讲一下最优边界分类器(optimal margin classifier,),其中还会引入一些关于拉格朗日对偶(Lagrange duality)的内容。然后我们还会接触到核(Kernels),这提供了一种在非常高的维度(例如无穷维度)中进行 SVM 学习的高效率方法,最终本章结尾部分会讲 SMO 算法,也就是 SVM 算法的一个有效实现方法。
1 边界(Margins):直觉(Intuition)
咱们这回讲 SVM 学习算法,从边界(margins)开始说起。这一节我们会给出关于边界的一些直观展示(intuitions),以及对于我们做出的预测的信心(confidence);在本章的第三节中,会对这些概念进行更正式化的表述。
考虑逻辑回归,其中的概率分布$p(y = 1|x;\theta)$ 是基于 $h_\theta(x) = g(\theta^Tx)$ 而建立的模型。当且仅当 $h_\theta(x) \geq 0.5$ ,也就是 $\theta^Tx \geq 0$ 的时候,我们才会预测出“$1$”。假如有一个正向(Positive)的训练样本(positive tra_ining example)($y = 1$)。那么$\theta^Tx$ 越大,$h_\theta (x) = p(y = 1|x; w, b)$ 也就越大,我们对预测 Label 为 $1$ 的“信心(confidence)”也就越强。所以如果 $y = 1$ 且 $\theta^T x \gg 0$(远大于 $0$),那么我们就对这时候进行的预测非常有信心,当然这只是一种很不正式的粗略认识。与之类似,在逻辑回归中,如果有 $y = 0$ 且 $\theta^T x \ll 0$(远小于 0),我们也对这时候给出的预测很有信心。所以还是以一种非常不正式的方式来说,对于一个给定的训练集,如果我们能找到一个 $\theta$,满足当 $y^{(i)} = 1$ 的时候总有 $\theta^T x^{(i)} \gg 0$,而 $y^{(i)} = 0$ 的时候则 $\theta^T x^{(i)} \ll 0$,我们就说这个对训练数据的拟合很好,因为这就能对所有训练样本给出可靠(甚至正确)的分类。似乎这样就是咱们要实现的目标了,稍后我们就要使用函数边界记号(notion of functional margins) 来用正规的语言来表达该思路。
还有另外一种的直观表示,例如下面这个图当中,画叉的点表示的是正向训练样本,而小圆圈的点表示的是负向训练样本,图中还画出了分类边界(decision boundary), 这条线也就是通过等式 $\theta^T x = 0$ 来确定的,也叫做分类超平面(separating hyperplane)。 图中还标出了三个点 $A,B 和 C$。
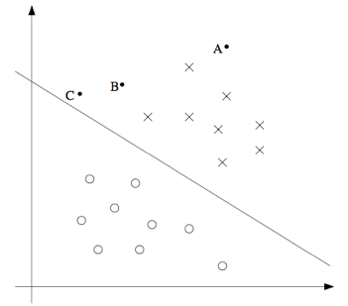
可以发现 $A$ 点距离分界线很远。如果我们对 $A$ 点的 $y$ 值进行预测,估计我们会很有信心地认为在那个位置的 $y = 1$。与之相反的是 $C$,这个点距离边界线很近,而且虽然这个 $C$ 点也在预测值 $y = 1$ 的一侧,但看上去距离边界线的距离实在是很近的,所以也很可能会让我们对这个点的预测为 $y = 0$。因此,我们对 $A$ 点的预测要比对 $C$ 点的预测更有把握得多。$B$ 点正好在上面两种极端情况之间,更广泛地说,如果一个点距离分类超平面(separating hyperplane) 比较远,我们就可以对给出的预测很有信心。那么给定一个训练集,如果我们能够找到一个分类边界,利用这个边界我们可以对所有的训练样本给出正确并且有信心(也就是数据点距离分类边界要都很远)的预测,那这就是我们想要达到的状态了。当然上面这种说法还是很不正规,后面我们会使用几何边界记号(notion of geometric margins) 来更正规地来表达。
2 记号(Notation)
在讨论 SVMs 的时候,出于简化的目的,我们先要引入一个新的记号,用来表示分类。假设我们要针对一个二值化分类的问题建立一个线性分类器,其中用来分类的标签(label)为 $y$,分类特征(feature)为 $x$。从此以后我们就用 $y \in <!–swig0–>
$$
现在,我们假设这个联合收敛成立(uniform convergence holds),也就是说,对于所有的 $h \in H$,都有 $|ε(h)-\hat\epsilon(h)| ≤ \gamma$。我们的学习算法选择了 $\hat{h} = arg\min_{h\in H} \hat\epsilon(h)$,关于这种算法的泛化,我们能给出什么相关的证明呢?
将 $h^∗ = arg \min_{h\in H} \epsilon(h)$ 定义为 $H$ 中最佳可能假设(best possible hypothesis)。这里要注意此处的 $h^∗$ 是我们使用假设集合 $H$ 所能找出的最佳假设,所以很自然地,我们就能理解可以用这个 $h^∗$ 来进行性能对比了。则有:
$$
\begin{aligned}
\epsilon(\hat h) & \le \hat\epsilon(\hat h)+\gamma \
& \le \hat\epsilon(h^*)+\gamma \
& \le \epsilon(h^*)+2\gamma
\end{aligned}
$$
上面的第一行用到了定理 $| \epsilon(\hat h) - \hat\epsilon (\hat h) | \le \gamma$(可以通过上面的联合收敛假设来推出)。第二行用到的定理是 $\hat{h}$ 是选来用于得到最小 $\hat\epsilon(h)$ ,然后因此对于所有的 $h$ 都有 $\hat\epsilon(\hat{h}) \leq \hat\epsilon(h)$,也就自然能推出 $\hat\epsilon(\hat{h}) \le \hat\epsilon(h^∗)$ 。第三行再次用到了上面的联合收敛假设,此假设表明 $\hat\epsilon(h^∗) \le \epsilon(h^∗) + \gamma$ 。所以,我们就能得出下面这样的结论:如果联合收敛成立,那么 $\hat h$ 的泛化误差最多也就与 $H$ 中的最佳可能假设相差 $2\gamma$。
好了,咱们接下来就把上面这一大堆整理成一条定理(theorem)。
定理: 设 $|H| = k$译者注:即 H 集合中元素个数为 k,然后设 $m$ 和 $\delta$ 为任意的固定值。然后概率至少为 $1 - \delta$,则有:
$$
\epsilon(\hat h)\le (\min_{h\in H}\epsilon(h))+2\sqrt{\frac{1}{2m}log\frac{2k}{\delta}}
$$
上面这个的证明,可以通过令 $\gamma$ 等于平方根$\sqrt{\cdot}$的形式,然后利用我们之前得到的概率至少为 $1 – \delta$ 的情况下联合收敛成立,接下来利用联合收敛能表明 $\epsilon(h)$ 最多比 $\epsilon(h^∗) = \min_{h\in H} \epsilon(h)$ 多 $2\gamma$(这个前面我们已经证明过了)。
这也对我们之前提到过的在模型选择的过程中在偏差(bias)/方差(variance)之间的权衡给出了定量方式。例如,加入我们有某个假设类 $H$,然后考虑切换成某个更大规模的假设类 $H’ \supseteq H$。如果我们切换到了 $H’$ ,那么第一次的 $\min_h \epsilon(h)$ 只可能降低(因为我们这次在一个更大规模的函数集合里面来选取最小值了)。因此,使用一个更大规模的假设类来进行学习,我们的学习算法的“偏差(bias)”只会降低。然而,如果 $k$ 值增大了,那么第二项的那个二倍平方根项$2\sqrt{\cdot}$也会增大。这一项的增大就会导致我们使用一个更大规模的假设的时候,“方差(variance)”就会增大。
通过保持 $\gamma$ 和 $\delta$ 为固定值,然后像上面一样求解 $m$,我们还能够得到下面的样本复杂度约束:
推论(Corollary): 设 $|H| = k$ ,然后令 $\delta,\gamma$ 为任意的固定值。对于满足概率最少为 $1 - \delta$ 的 $\epsilon(\hat{h}) \le min_{h\in H} \epsilon(h) + 2\gamma$ ,下面等式关系成立:
$$
\begin{aligned}
m &\ge \frac{1}{2\gamma^2}log\frac{2k}{\delta} \
& = O(\frac{1}{\gamma^2}log\frac{k}{\delta})
\end{aligned}
$$
4 无限个假设(infinite H)的情况
我们已经针对有限个假设类的情况证明了一些有用的定理。然而有很多的假设类都包含有无限个函数,其中包括用实数参数化的类(比如线性分类问题)。那针对这种无限个假设的情况,我们能证明出类似的结论么?
我们先从一些不太“准确”论证的内容开始(not the “right” argument)。当然也有更好的更通用的论证,但先从这种不太“准确”的内容除法,将有助于锻炼我们在此领域内的直觉(intuitions about the domain)。
若我们有一个假设集合 $H$,使用 $d$ 个实数来进行参数化(parameterized by d real numbers)。由于我们使用计算机表述实数,而 IEEE 的双精度浮点数( C 语言里面的 double 类型)使用了 64 bit 来表示一个浮点数(floating-point number,),这就意味着如果我们在学习算法中使用双精度浮点数(double- precision floating point),那我们的算法就由 64 d 个 bit 来进行参数化(parameterized by 64d bits)。这样我们的这个假设类实际上包含的不同假设的个数最多为 $k = 2^{64d}$ 。结合上一节的最后一段那个推论(Corollary),我们就能发现,要保证 $\epsilon(\hat{h}) \leq \epsilon(h^∗) + 2\gamma$ ,同时还要保证概率至少为 $1 - \delta$ ,则需要训练样本规模 $m$ 满足$m \ge O(\frac{1}{\gamma^2}log\frac{2^{64d}}{\delta})=O(\frac{d}{\gamma^2}log\frac{1}{\delta})=O_{\gamma,\delta}(d)$(这里的 $\gamma$,$\delta$下标表示最后一个大$O$可能是一个依赖于$\gamma$和$\delta$的隐藏常数。)因此,所需的训练样本规模在模型参数中最多也就是线性的(the number of training examples needed is at most linear in the parameters of the model)。
The fact that we relied on 64-bit floating point makes this argument not entirely satisfying, but the conclusion is nonetheless roughly correct: If what we’re going to do is try to minimize training error, then in order to learn “well” using a hypothesis class that has d parameters, generally we’re going to need on the order of a linear number of training examples in d.
上述论证依赖于假定参数是 64 位浮点数(但是实际上实数参数不一定如此实现),因此还不能完全令人满意,但这个结论大致上是正确的:如果我们试图使训练误差(training error)最小化,那么为了使用具有 $d$ 个参数的假设类(hypothesis class)的学习效果“较好(well)”,通常就需要 $d$ 的线性规模个训练样本。
(在这里要注意的是,对于使用经验风险最小化(empirical risk minimization ,ERM)的学习算法,上面这些结论已经被证明适用。因此,样本复杂度(sample complexity)对 $d$ 的线性依赖性通常适用于大多数分类识别学习算法(discriminative learning algorithms),但训练误差或者训练误差近似值的最小化,就未必适用于分类识别了。对很多的非 ERM 学习算法提供可靠的理论论证,仍然是目前很活跃的一个研究领域。)
前面的论证还有另外一部分让人不太满意,就是依赖于对 $H$ 的参数化(parameterization)。根据直觉来看,这个参数化似乎应该不会有太大影响:我们已经把线性分类器(linear classifiers)写成了 $h_\theta(x) = 1{\theta_0 + \theta_1x_1 + ···\theta_n x_n \geq 0}$ 的形式,其中有 $n+1$ 个参数 $\theta_0,…,\theta_n$ 。但也可以写成 $h_{u,v}(x) = 1{(u^2_0 - v_0^2) + (u^2_1 - v_1^2)x1 + ··· (u^2_n - v_n^2)x_n \geq 0}$ 的形式,这样就有 $2n+2$ 个参数 $u_i, v_i$ 了。然而这两种形式都定义了同样的一个 $H:$ 一个 $n$ 维的线性分类器集合。
要推导出更让人满意的论证结果,我们需要再额外定义一些概念。
给定一个点的集合 $S = {x^{(i)}, …, x^{(d)}}$(与训练样本集合无关),其中 $x(i) \in X$,如果 $H$ 能够对 集合 $S$ 实现任意的标签化(can realize any labeling on S),则称 $H$ 打散(shatter) 了 $S$。例如,对于任意的标签集合 (set of labels)${y^{(1)}, …, y^{(d)}}$,都有 一些$h\in H$ ,对于所有的$i = 1, …d$,式子$h(x^{(i)}) = y^{(i)}$都成立。(译者注:关于 shattered set 的定义可以参考:https://en.wikipedia.org/wiki/Shattered_set 更多关于 VC 维 的内容也可以参考:https://www.zhihu.com/question/38607822 )
给定一个假设类 $H$,我们定义其 VC维度(Vapnik-Chervonenkis dimension), 写作 $VC(H)$,这个值也就是能被 $H$ 打散(shatter)的最大的集合规模。(如果 $H$ 能打散任意大的集合(arbitrarily large sets),那么 $VC(H) = ∞$。)
例如,若一个集合由下图所示的三个点组成:
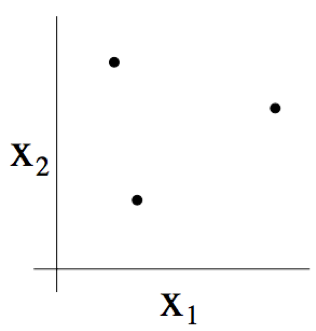
那么二维线性分类器 $(h(x) = 1{\theta_0 +\theta_1 x_1 + \theta_2 x_2 \geq 0})$ 的集合 $H$ 能否将上图所示的这个集合打散呢?答案是能。具体来看则如下图所示,以下八种分类情况中的任意一个,我们都能找到一种用能够实现 “零训练误差(zero training error)” 的线性分类器(linear classifier):
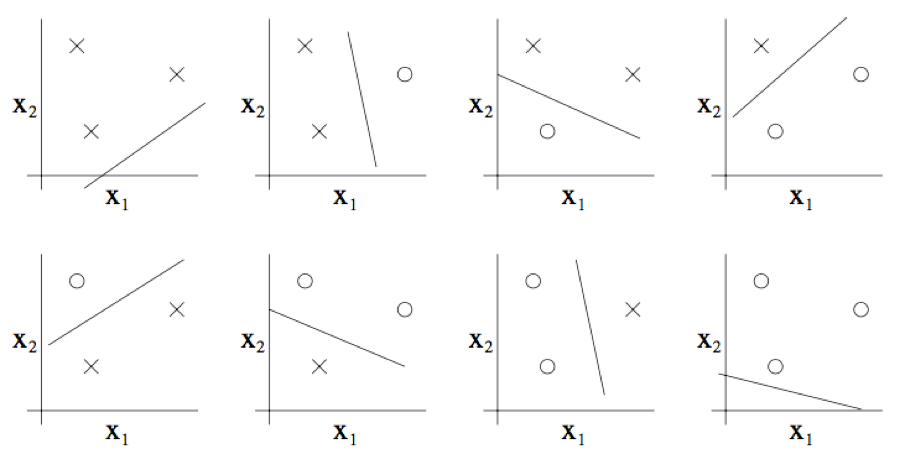
此外,这也有可能表明,这个假设类 $H$ 不能打散(shatter)4 个点构成的集合。因此,$H$ 可以打散(shatter)的最大集合规模为 3,也就是说 $VC(H)= 3$。
这里要注意,$H$ 的 $VC$ 维 为3,即便有某些 3 个点的集合不能被 $H$ 打散。例如如果三个点都在一条直线上(如下图左侧的图所示),那就没办法能够用线性分类器来对这三个点的类别进行划分了(如下图右侧所示)。
换个方式来说,在 $VC$ 维 的定义之下,要保证 $VC(H)$ 至少为 $d$,只需要证明至少有一个规模为 $d$ 的集合能够被 $H$ 打散 就可以了。
这样就能够给出下面的定理(theorem)了,该定理来自 Vapnik。(有不少人认为这是所有学习理论中最重要的一个定理。)
Theorem. Let H be given, and let d = VC(H). Then with probability at least 1-δ, we have that for all h∈H,
定理:给定 $H$,设 $d = VC(H)$。然后对于所有的 $h\in H$,都有至少为 $1-\delta$ 的概率使下面的关系成立:
$$
|\epsilon(h)-\hat\epsilon(h)|\le O(\sqrt{\frac{d}{m}log\frac{d}{m}+\frac 1mlog\frac 1\delta})
$$
此外,有至少为 $1-\delta$ 的概率:
$$
\epsilon(\hat h)\le \epsilon(h^*)+O(\sqrt{\frac{d}{m}log\frac{d}{m}+\frac 1mlog\frac 1\delta})
$$
换句话说,如果一个假设类有有限的 $VC$ 维,那么只要训练样本规模 $m$ 增大,就能够保证联合收敛成立(uniform convergence occurs)。和之前一样,这就能够让我们以 $\epsilon(h)$ 的形式来给 $\epsilon(h^∗)$ 建立一个约束(bound)。此外还有下面的推论(corollary):
Corollary. For $|ε(h) - \hat\epsilon(h)| ≤ \gamma$ to hold for all h ∈ H (and hence $\epsilon(\hat{h}) ≤ \epsilon(h^∗) + 2\gamma$) with probability at least 1 - δ, it suffices that $m = O_{\gamma,\delta}(d)$.
推论(Corollary): 对于所有的 $h \in H$ 成立的 $|\epsilon(h) - \epsilon(\hat h)| \le \gamma$ (因此也有 $\epsilon(\hat h) ≤ \epsilon(h^∗) + 2\gamma$),则有至少为 $1 – \delta$ 的概率,满足 $m = O_{\gamma,\delta}(d)$。
In other words, the number of training examples needed to learn “well” using H is linear in the VC dimension of H. It turns out that, for “most” hypothesis classes, the VC dimension (assuming a “reasonable” parameterization) is also roughly linear in the number of parameters. Putting these together, we conclude that (for an algorithm that tries to minimize training error) the number of training examples needed is usually roughly linear in the number of parameters of H.
换个方式来说,要保证使用 假设集合 $H$ 的 机器学习的算法的学习效果“良好(well)”,那么训练集样本规模 $m$ 需要与 $H$ 的 $VC$ 维度 线性相关(linear in the VC dimension of H)。这也表明,对于“绝大多数(most)”假设类来说,(假设是“合理(reasonable)”参数化的)$VC$ 维度也大概会和参数的个数线性相关。把这些综合到一起,我们就能得出这样的一个结论:对于一个试图将训练误差最小化的学习算法来说:训练样本个数 通常都大概与假设类 $H$ 的参数个数 线性相关。
第五章
第七部分 正则化与模型选择
设想一个机器学习的问题,我们要从一系列不同的模型中进行挑选。例如,我们可能是用一个多项式回归模型 (polynomial regression model) $h_\theta (x)=g(\theta_0+\theta_1x+\theta_2x^2+\cdots+\theta_kx^k)$ 想要判定这里的多项式次数 $k$ 应该是多少,$0, 1, …, 或者10$。那么我们怎么才能自动选择一个能够在偏差 (bias)/方差(variance)$^1$之间进行权衡的模型呢? 或者换一个说法,假如我们希望能够自动选出来一个带宽参数 (bandwidth parameter) $\tau$ 来用于局部加权回归(locally weighted regression,所谓为 LWR,参考 note1的第2节),或 者要自动选出一个参数 $C$ 用于拉格朗日正则化的支持向量机算法(l1-regularized SVM)。怎么来实现呢?
1 考虑到前面的讲义中我们已经提到过偏差(bias)/方差(variance)这两个概念很大区别,有的读者可能觉得是不是应该把它们叫做一对“孪生 (twin)”魔鬼(evils)。或许可以把它们俩当做是一对异卵双胞胎(non-identical twins)。理解概念差别就好了,怎么说什么的都不要紧的。
为了具体一些,咱们这一系列讲义中都假设备选集合的模型个数有限 $M = {M_1,\cdots,M_d}$。例如,在我们上面刚刚随便举的本章第一个例子中,$M_i$ 就是一个 $i$次多项式拟合模型(i-th order polynomial regression model)。(其实把 $M$ 扩展到无穷集合 也不难的。$^2$)换个说法就是,如果我们要从支持向量机算法 (SVM)、神经网络算法(neural network)、逻辑回归算法(logistic regression)当中三选一,那么这里的 $M$ 就应该都 包含了这些模型了。
2 如果我们要从一个无穷的模型集合中进行选取一个,假如说要选取一个带宽参数 $\tau\in \mathbb R^+$ (正实数)的某个可能的值,可以将 $\tau$ 离散化,而只考虑 有限的一系列值。更广泛来说,我们要讲到的大部分算法都可以看做在模型空间(space of models) 中进行优化搜索 (performing optimization search)的 问题,这种搜索也可以在无穷模型类(infinite model classes)上进行。
1 交叉验证(Cross Validation)
假如我们得到了一个训练集 $S$。我们已经了解了经验风险最小化(empirical risk minimization,缩写为 ERM),那么接下来就要通过使用 ERM 来进行模型选择来推导出一种新的算法:
- 对训练集 $S$ 中的每一个模型 (model) $M_i$ 进行训练,得到某假设类 (hypothesis) $h_i$
- 从这些假设中选取训练误差最小的假设 (hypothesis)
上面这个算法是行不通的。比如考虑要选择多项式的阶(最高次项的次数)的情况。多项式的阶越高,对训练集 $S$ 的拟合程度就越好,训练误差自然也就更小。然而,这个方法选出来 的总是那种波动非常强 (high-variance) 的高次多项式模型 (high-degree polynomial model) ,这种情况我们之前就讲过了,通常都是很差的选择。
下面这个算法就更好一些。这个方法叫保留交叉验证 (hold-out cross validation),也叫简单交叉验证 (simple cross validation),步骤如下:
- 随机拆分训练集 $S$ 成 $S_{train}$ (例如,可以选择整体数据中 的 70% 用于训练) 和 $S_{cv}$ (训练集中剩余的 30%用于验 证)。这里的 $S_{cv}$ 就叫做保留交叉验证集(hold-out cross validation set)。
- 只对集合 $S_{train}$ 中的每一个模型 $M_i$ 进行训练,然后得到假设类(hypothesis) $h_i$。
- 筛选并输出对保留交叉验证集有最小误差 $\hat\epsilon_{S_{cv}}(h_i)$ 的假设$h_i$ 。(回忆一下,这里的 $\hat\epsilon_{S_{cv}}(h_i)$ 表示的是假设 $h$ 在保留交叉验证集 $S_{cv}$ 中的样本的经验误差(empirical error)。)
这样通过在一部分未进行训练的样本集合 $S_{cv}$ 上进行测试, 我们对每个假设 $h_i$ 的真实泛化误差 (generalization error) 就能得到一个比上一个方法更好的估计,然后就能选择出来一个有最小估计泛化误差 (smallest estimated generalization error) 的假设了。通常可以选择 1/4 到 1/3 的数据样本用来作为保留交叉验证集(hold out cross validation set),30% 是一个很典型的选择。
还有另外一种备选方法,就是在第三步的时候,也可以换做选 择与最小估计经验误差 $\hat\epsilon_{S_{cv}}(h_i)$ 对应的模型 $M_i$ ,然后对整 个训练样本数据集 $S$ 使用 $M_i$ 来进行再次训练。(这个思路通常都不错,但有一种情景例外,就是学习算法对初始条件和数据的扰动(perturbations of the initial conditions and/or data) 非常敏感的情况。在这样的方法中,适用于 $S_{train}$ 的模型未必就能够同样适用于 $S_{cv}$,这样就最好还是放弃再训练的步骤 (forgo this retraining step)。)
使用保留交叉验证集(hold out cross validation set)的一个弊端就是“浪费(waste)”了训练样本数据集的 30% 左右。甚至即便我们使用了备选的那个针对整个训练集使用模型进行 重新训练的步骤,也还不成,因为这无非是相当于我们只尝试在一个 $0.7m$ 规模的训练样本集上试图寻找一个好的模型来解决一个机器学习问题,而并不是使用了全部的 $m$ 个训练样 本,因为我们进行测试的都是每次在仅 $0.7m$ 规模样本上进 行训练而得到的模型。当然了,如果数据非常充足,或者是很廉价的话,也可以用这种方法,而如果训练样本数据本身就很 稀缺的话(例如说只有 20 个样本),那就最好用其他方法了。
下面就是一种这样的方法,名字叫 k-折交叉验证(k-fold cross validation),这样每次的用于验证的保留数据规模都更小:
随机将训练集 $S$ 切分成 $k$ 个不相交的子集。其中每一个子集的规模为 $m/k$ 个训练样本。这些子集为 $S_1,\cdots,S_k$
对每个模型 $M_i$,我们都按照下面的步骤进行评估(evaluate):
对 $j=1,\cdots,k$
在 $S_1\cup\cdots\cup S_{j-1}\cup S_{j+1}\cup\cdots\cup S_k$ (也就是除了 $S_j$ 之外的其他数据),对模型 $M_i$ 得到假设 $h_{ij}$ 。接下来针对 $S_j$ 使用假设 $h_{ij}$ 进行测试,得到经验误差 $\hat\epsilon_{S_{cv}}(h_{ij})$
对$\hat\epsilon_{S_{cv}}(h_{ij})$ 取平均值,计算得到的值就当作是模型 $M_i$ 的估计泛化误差(estimated generalization error)
选择具有最小估计泛化误差(lowest estimated generalization error)的模型 $M_i$ 的,然后在整个训练样本集 $S$ 上重新训练该模型。这样得到的假设 (hypothesis)就可以输出作为最终结果了。
通常这里进行折叠的次数 (number of folds) $k$ 一般是 10,即 $k = 10$。这样每次进行保留用于验证的数据块就只有 $1/k$ ,这 就比之前的 30% 要小多了,当然这样一来这个过程也要比简单的保留交叉验证方法消耗更多算力成本,因为现在需要对每个模型都进行 $k$ 次训练。
虽然通常选择都是设置 $k = 10$,不过如果一些问题中数据量 确实很匮乏,那有时候也可以走一点极端,设 $k = m$,这样是为了每次能够尽可能多地利用数据,尽可能少地排除数据。这 种情况下,我们需要在训练样本集 $S$ 中除了某一个样本外的其他所有样本上进行训练,然后在保留出来的单独样本上进行检验。然后把计算出来的 $m = k$ 个误差放到一起求平均值, 这样就得到了对一个模型的泛化误差的估计。这个方法有专门的名字,由于每次都保留了一个训练样本,所以这个方法就叫做弃一法交叉验证(leave-one-out cross validation)。
最后总结一下,咱们讲了不同版本的交叉验证,在上文中是用来作为选择模型的方法,实际上也可以更单纯地用来对一个具体的模型或者算法进行评估。例如,如果你已经实现了某中学习算法,然后想要估计一下针对你的用途这个算法的性能表现 (或者是你创造了一种新的学习算法,然后希望在技术论文中 报告你的算法在不同测试集上的表现),交叉验证都是个很好 的解决方法。
2 特征选择(Feature Selection)
模型选择(model selection)的一个非常重要的特殊情况就是特征选择(feature selection)。设想你面对一个监督学习问题 (supervised learning problem),其中特征值的数量 $n$ 特别大 (甚至可能比训练样本集规模还大,即$n >> m$),然而你怀疑可能只有一小部分的特征 (features) 是与学习任务“相关 (relevant)”的。甚至即便是针对 $n$ 个输入特征值使用一个简单的线性分类器 (linear classifier,例如感知器 perceptron),你的假设类(hypothesis class)的 $VC$ 维(VC dimension) 也依然能达到 $O(n)$,因此有过拟合 (overfitting) 的潜在风险,除非训练样本集也足够巨大 (fairly large)。
在这样的一个背景下,你就可以使用一个特征选择算法,来降 低特征值的数目。假设有 $n$ 个特征,那么就有 $2^n$ 种可能的特征子集 (因为 $n$ 个特征中的任意一个都可以被某个特征子集(feature subsets)包含或者排除),因此特征选择(feature selection)就可以看做是一个对 $2^n$ 种可能的模型进行选择 (model selection problem)的形式。对于特别大的 $n$,要是彻底枚举(enumerate)和对比全部 $2^n$ 种模型,成本就太高了, 所以通常的做法都是使用某些启发式的搜索过程(heuristic search procedure)来找到一个好的特征子集。下面的搜索过程叫做向前搜索(forward search) :
初始化一个集合为空集 $\mathcal F=\emptyset$
循环下面的过程{
(a) 对于 $i=1,\cdots,n$ 如果 $i\notin \mathcal F$,则令 $\mathcal F_i=\mathcal F\cup {i}$,然后使用某种交叉验证来评估特征 $\mathcal F_i$
(b) 令 $\mathcal F$ 为(a)中最佳特征子集
}
整个搜索过程中筛选出来了最佳特征子集(best feature subset),将其输出。
算法的外层循环可以在 $\mathcal F={1,\cdots,n}$ 达到全部特征规模时停止,也可以在 $|\mathcal F|$ 超过某个预先设定的阈值时停止(阈值和你想要算法用到特征数量最大值有关)。
这个算法描述的是对模型特征选择进行包装(包装器特征选择,Wrapper feature selection )的一个实例,此算法本身就是一个将学习算法进行“打包(wraps)”的过程,然后重复调用这个学习算法来评估(evaluate)此算法对不同的特征子集(feature subsets)的处理效果。除了向前搜索外,还可以使用其他的搜索过程。例如,可以**逆向搜索(backward search)**,从$\mathcal F = {1, …, n}$ ,即规模等同于全部特征开始,然后重复,每次删减一个特征,直到 $\mathcal F$ 为空集时终止。
这种包装器特征选择算法(Wrapper feature selection algorithms)通常效果不错,不过对算力开销也很大,尤其是要对学习算法进行多次调用。实际上,完整的向前搜索 (forward search,也就是 $\mathcal F$ 从空集开始,到最终达到整个样本集规模,即 $\mathcal F ={1, …, n}$ 终止)将要对学习算法调用约 $O(n^2)$ 次。
过滤器特征选择(Filter feature selection methods) 给出的特征子集选择方法更具有启发性(heuristic),而且在算力上的开销成本也更低。这里的一个思路是,计算一个简单的分数 $S(i)$,用来衡量每个特征 $x_i$ 对分类标签(class labels) $y$ 所能体现的信息量。然后,只需根据需要选择最大分数 $S(i)$ 的 $k$ 个特征。
怎么去定义用于衡量信息量的分值 $S(i)$ 呢?一种思路是使用 $x_i$ 和 $y$ 之间的相关系数的值(或其绝对值),这可以在训练 样本数据中算出。这样我们选出的就是与分类标签(class labels)的关系最密切的特征值(features)。实践中,通常(尤其当特征 $x_i$ 为离散值(discrete-valued features))选择 $x_i$ 和 $y$ 的互信息( mutual information, ${\rm{MI}}(x_i, y)$ ) 来作为 $S(i)$ 。
$$
{\rm{MI}}(x_i, y)=\sum_{x_i\in{0, 1}}\sum_{y\in{0,1}}p(x_i,y)\log\frac{p(x_i,y)}{p(x_i)p(y)}
$$
(上面这个等式假设了 $x_i$ 和 $y$ 都是二值化;更广泛的情况下将会超过变量的范围 。)上式中的概率$p(x_i,y)$,$p(x_i)$ 和 $p(y)$ 都可以根据它们在训练集上的经验分布(empirical distributions)而推测(estimated)得到。
要对这个信息量分值的作用有一个更直观的印象,也可以将互信息(mutual information)表达成 $KL$ 散度(Kullback-Leibler divergence,也称 $KL$ 距离,常用来衡量两个概率分布的距离):
$$
{\rm{MI}}(x_i,y)={\rm KL}(p(x_i,y),|,p(x_i)p(y))
$$
在下一节当中,你会与 $KL$ 散度进行更多的接触,这里比较通俗地说,这个概念对 $p(x_i,y)$ 和 $p(x_i)p(y)$ 的概率分布的差异程度给出一个衡量。如果 $x_i$ 和 $y$ 是两个独立的随机变量,那么必然有 $p(x_i, y) = p(x_i)p(y)$,而两个分布之间的 $KL$ 散度就应该是 $0$。这也符合下面这种很自然的认识:如果 $x_i$ 和 $y$ 相互独立,那么 $x_i$ 很明显对 $y$ 是“完全无信息量”(non-informative),因此对应的信息量分值 $S(i)$ 就应该很小。与之相反地,如果 $x_i$ 对 $y$ “有很大的信息量 (informative)”,那么这两者的互信息 ${\rm MI}(x_i,y)$ 就应该很大。
最后一个细节:现在你已经根据信息量分值 $S(i)$ 的高低来对特征组合(features)进行了排序,那么要如何选择特征个数 $k$ 呢?一个标准办法就是使用交叉验证(cross validation)来从可能的不同 $k$ 值中进行筛选。例如,在对文本分类(text classification)使用朴素贝叶斯方法(naive Bayes),这个问题中的词汇规模(vocabulary size) $n$ 通常都会特别大,使用 交叉验证的方法来选择特征子集(feature subset),一般都 提高分类器精度。
3 贝叶斯统计(Bayesianstatistics)和正则化 (regularization)
在本章,我们要讲一下另一种工具,用于我们对抗过拟合(overfitting)。
在本章的开头部分,我们谈到了使用最大似然(maximum likelihood,缩写为 ML)来进行参数拟合,然后根据下面的式子来选择参数:
$$
\theta_{\rm ML}=\arg \max_{\theta}\prod_{i=1}^{m}p(y^{(i)}|x^{(i)};\theta)
$$
在后续的讨论中,我们都是把 $\theta$ 看作是一个未知参数 (unknown parameter)。在频率统计(frequentist statistics) 中,往往采用的观点是认为 $\theta$ 是一个未知的常量(constant- valued)。在频率论(frequentist)的世界观中, $\theta$ 只是碰巧未知,而不是随机的,而我们的任务就是要找出某种统计过程 (statistical procedures,例如最大似然法(maximum likelihood)),来对这些参数进行估计。
另外一种解决我们这个参数估计问题的方法是使用贝叶斯世界观,把 $\theta$ 当做是未知的随机变量。在这个方法中,我们要先指定一个在 $\theta$ 上的先验分布(prior distribution) $p(\theta)$,这个 分布表达了我们关于参数的“预先判断(prior beliefs)”。给定一个训练集合 $S = {(x^{(i)},y^{(i)})}^m_{i=1}$,当我们被要求对一个新的 $x$ 的值进行预测的时候,我们可以计算在参数上的后验分布 (posterior distribution):
$$
\begin{aligned}
p(\theta|S)
&=\frac{p(S|\theta)p(\theta)}{p(S)}\
&=\frac{(\prod_{i=1}^{m}p(y^{(i)}|x^{(i)},\theta))p(\theta)}{\int_{\theta} {\left(\prod_{i=1}^{m}p(y^{(i)}|x^{(i)},\theta)p(\theta)\right)}d\theta}\qquad (1)
\end{aligned}
$$
在上面的等式中,$p(y(i)|x(i),\theta)$ 来自你所用的机器学习问题中的模型。例如,如果你使用贝叶斯逻辑回归(Bayesian logistic regression),你可能就会选择 $p(y^{(i)}|x^{(i)},\theta)=h_\theta(x^{(i)})^{y^{(i)}} (1-h_\theta(x^{(i)}))^{(1-y^{(i)})}$ 其中,$h_\theta(x^{(i)})=1/(1+\exp(-\theta^Tx^{(i)}))$.$^3$
3 由于我们在这里把 $\theta$ 看作是一个随机变量了,就完全可以在其值上使用 条件判断,然后写成 “$p(y|x, \theta)$” 来替代 “$p(y|x; \theta)$”。
若有一个新的测试样本 $x$,然后要求我们对这个新样本进行预测,我们可以使用 $\theta$ 上的后验分布(posterior distribution)来计算分类标签(class label)上的后验分布:
$$
p(y|x,S)=\int_\theta p(y|x,\theta)p(\theta|S)d\theta\qquad (2)
$$
在上面这个等式中,$p(\theta|S)$ 来自等式 (1)。例如,如果目标是要根据给定的 $x$ 来预测对应的 $y$ 的值,那就可以输出$^4$:
4 如果 $y$ 是一个离散值(discrete-valued),那么此处的积分(integral)就用求和(summation)来替代。
$$
E[y|x,S]=\int_y y p(y|x,S)dy
$$
这里我们简单概述的这个过程,可认为是一种“完全贝叶斯 (fully Bayesian)”预测,其中我们的预测是通过计算相对于 $\theta$ 上的后验概率 $p(\theta|S)$ 的平均值而得出的。然而很不幸,这 个后验分布的计算通常是比较困难的。这是因为如等式 (1) 所示,这个计算需要对 $\theta$ 进行积分(integral),而 $\theta$ 通常是高维度的(high-dimensional),这通常是不能以闭合形式 (closed-form)来实现的。
因此在实际应用中,我们都是用一个与 $\theta$ 的后验分布 (posterior distribution)近似的分布来替代。常用的一个近似是把对 $\theta$ 的后验分布(正如等式$(2)$中所示)替换为一个单点估计(single point estimate)。对 $\theta$ 的最大后验估计 (MAP,maximum a posteriori estimate)为:
$$
\theta_{MAP}=\arg \max_\theta \prod_{i=1}^{m} p(y^{(i)}|x^{(i)})p(\theta)
$$
注意到了么,这个式子基本和对 $\theta$ 的最大似然估计(ML (maximum likelihood) estimate)是一样的方程,除了末尾多了 一个先验概率分布 $p(\theta)$。
实际应用里面,对先验概率分布 $p(\theta)$ 的常见选择是假设 $\theta\sim N(0 , \tau ^2I)$。使用这样的一个先验概率分布,拟合出来的参数 $\theta_{MAP}$ 将比最大似然得到的参数有更小的范数(norm)。 (更多细节参考习题集 #3。)在实践中,贝叶斯最大后验估计(Bayesian MAP estimate)比参数的最大似然估计 (ML estimate of the parameters)更易于避免过拟合。例如,贝叶斯逻辑回归(Bayesian logistic regression)就是一种非常有效率的文本分类(text classification)算法,即使文本分类中参数规模 $n$ 通常是远远大于样本规模 $m$ 的,即 $n\gg m$。
第六章
1 感知器(perceptron)和大型边界分类器(large margin classifiers)
本章是讲义中关于学习理论的最后一部分,我们来介绍另外机器学习模式。在之前的内容中,我们考虑的都是批量学习的情况,即给了我们训练样本集合用于学习,然后用学习得到的假设 $h$ 来评估和判别测试数据。在本章,我们要讲一种新的机器学习模式:在线学习,这种情况下,我们的学习算法要在进行学习的同时给出预测。
学习算法会获得一个样本序列,其中内容为有次序的学习样本,$(x^{(1)},y^{(1)}), (x^{(2)},y^{(2)}), …(x^{(m)},y^{(m)})$。最开始获得的就是$x^{(1)}$,然后需要预测$y^{(1)}$。在完成了这个预测之后,再把$y^{(1)}$的真实值告诉给算法(然后算法就利用这个信息来进行某种学习了)。接下来给算法提供$x^{(2)}$,再让算法对$y^{(2)}$进行预测,然后再把$y^{(2)}$ 的真实值告诉给算法,这样算法就又能学习到一些信息了。这样的过程一直持续到最末尾的样本$(x^{(m)},y^{(m)})$。在这种在线学习的背景下,我们关心的是算法在此过程中出错的总次数。因此,这适合需要一边学习一边给出预测的应用情景。
接下来,我们将对感知器学习算法(perceptron algorithm)的在线学习误差给出一个约束。为了让后续的推导(subsequent derivations)更容易,我们就用正负号来表征分类标签,即设 $y =\in {-1, 1}$。
回忆一下感知器算法(在第二章中有讲到),其参数 $\theta \in R^{n+1}$,该算法据下面的方程来给出预测:
$$
h_\theta(x)=g(\theta^T x)\qquad (1)
$$
其中:
$$
g(z)= \begin{cases} 1 & if\quad z\ge 0 \
-1 & if\quad z<0 \end{cases}
$$
然后,给定一个训练样本 $(x, y)$,感知器学习规则(perceptron learning rule)就按照如下所示来进行更新。如果 $h_\theta(x) = y$,那么不改变参数。若二者相等关系不成立,则进行更新$^1$:
$$
\theta :=\theta+yx
$$
1 这和之前我们看到的更新规则(update rule)的写法稍微有一点点不一样,因为这里我们把分类标签(labels)改成了 $y \in {-1, 1}$。另外学习速率参数(learning rate parameter) $\alpha$ 也被省去了。这个速率参数的效果只是使用某些固定的常数来对参数 $\theta$ 进行缩放,并不会影响生成器的行为效果。
当感知器算法作为在线学习算法运行的时候,每次对样本给出错误判断的时候,则更新参数,下面的定理给出了这种情况下的在线学习误差的约束边界。要注意,下面的错误次数的约束边界与整个序列中样本的个数 $m$ 不具有特定的依赖关系(explicit dependence),和输入特征的维度 $n$ 也无关。
定理 (Block, 1962, and Novikoff, 1962)。 设有一个样本序列:$(x^{(1)},y^{(1)}), (x^{(2)},y^{(2)}), …(x^{(m)},y^{(m)})$。假设对于所有的 $i$ ,都有 $||x^{(i)}|| \le D$,更进一步存在一个单位长度向量 $u (||u||_2 = 1)$ 对序列中的所有样本都满足 $y(i) \cdot (u^T x^{(i)}) \ge \gamma$(例如,如果$y^{(i)} = 1$,则$u^T x^{(i)} \ge \gamma$, 而如果 $y^{(i)} = -1$,则 $u^T x^{(i)} \le -\gamma$,以便 $u$ 就以一个宽度至少为 $\gamma$ 的边界分开了样本数据)。而此感知器算法针对这个序列给出错误预测的总数的上限为 $(D/\gamma)^2$ 。
证明: 感知器算法每次只针对出错的样本进行权重更新。设 $\theta(k)$ 为犯了第 $k$ 个错误(k-th mistake)的时候的权重。则 $\theta^{(1)} = -\theta$(因为初始权重为零),若第 $k$ 个错误发生在样本 $(x^{(i)},y^{(i)})$,则$g((x(i))^T \theta^{(k)}) \ne y^{(i)}$,也就意味着:
$$
(x^{(i)})^T\theta^{(k)}y^{(i)}\le 0\qquad(2)
$$
另外根据感知器算法的定义,我们知道 $\theta^{(k+1)} = \theta^{(k)} + y^{(i)}x^{(i)}$
然后就得到:
$$
\begin{aligned}
(\theta^{(k+1)})^T u &= (\theta^{(k)})^T u + y^{(i)}(x^{(i)})^T u\
&\ge (\theta^{(k)})^T u + \gamma
\end{aligned}
$$
利用一个简单的归纳法(straightforward inductive argument)得到:
$$
(\theta^{(k+1)})^T u \ge k\gamma\qquad (3)
$$
还是根据感知器算法的定义能得到:
$$
\begin{aligned}
||\theta^{(k+1)}||^2 &= ||\theta^{(k)} + y^{(i)}x^{(i)}||^2 \
&= ||\theta^{(k)}||^2 + ||x^{(i)}||^2 + 2y^{(i)}(x^{(i)})^T\theta^{(k)} \
&\le ||\theta^{(k)}||^2 + ||x^{(i)}||^2 \
&\le ||\theta^{(k)}||^2 + D\qquad\qquad(4)
\end{aligned}
$$
上面这个推导过程中,第三步用到了等式(2)。另外这里还要使用一次简单归纳法,上面的不等式(4) 表明:
$$
||\theta^{(k+1)}||^2 \le KD^2
$$
把上面的等式 (3) 和不等式 (4) 结合起来:
$$
\begin{aligned}
\sqrt{k}D &\ge ||\theta^{(k+1)}|| \
&\ge (\theta^{(k+1)})^T u \
&\ge k\gamma
\end{aligned}
$$
上面第二个不等式是基于 $u$ 是一个单位长度向量($z^T u = ||z||\cdot ||u|| cos \phi\le ||z||\cdot ||u||$,其中的$\phi$是向量 $z$ 和向量 $u$ 的夹角)。结果则表明 $k\le (D/\gamma)^2$。因此,如果感知器犯了一个第 $k$ 个错误,则 $k\le (D/\gamma)^2$。
第七章a
k 均值聚类算法(k-means clustering algorithm)
在聚类的问题中,我们得到了一组训练样本集 ${x^{(1)},…,x^{(m)}}$,然后想要把这些样本划分成若干个相关的“类群(clusters)”。其中的 $x^{(i)}\in R^n$,而并未给出分类标签 $y^{(i)}$ 。所以这就是一个无监督学习的问题了。
$K$ 均值聚类算法如下所示:
- 随机初始化(initialize)聚类重心(cluster centroids) $\mu_1, \mu_2,…, \mu_k\in R^n$ 。
- 重复下列过程直到收敛(convergence): {
对每个 $i$,设
$$
c^{(i)}:=arg\min_j||x^{(i)}-\mu_j||^2
$$
对每个 $j$,设
$$
\mu_j:=\frac{\sum_{i=1}^m1{c^{(i)}=j}x^{(i)}}{\sum_{i=1}^m1{c^{(i)}=j}}
$$
}
在上面的算法中,$k$ 是我们这个算法的一个参数,也就是我们要分出来的群组个数(number of clusters);而聚类重心 $\mu_j$ 表示的是我们对各个聚类的中心位置的当前猜测。在上面算法的第一步当中,需要初始化(initialize)聚类重心(cluster centroids),可以这样实现:随机选择 $k$ 个训练样本,然后设置聚类重心等于这 $k$ 个样本 各自的值。(当然也还有其他的初始化方法。)
算法的第二步当中,循环体内重复执行两个步骤:(i)将每个训练样本$x^{(i)}$ “分配(assigning)”给距离最近的聚类重心$\mu_j$;(ii)把每个聚类重心$\mu_j$ 移动到所分配的样本点的均值位置。下面的 图1 就展示了运行 $k$均值聚类算法的过程。
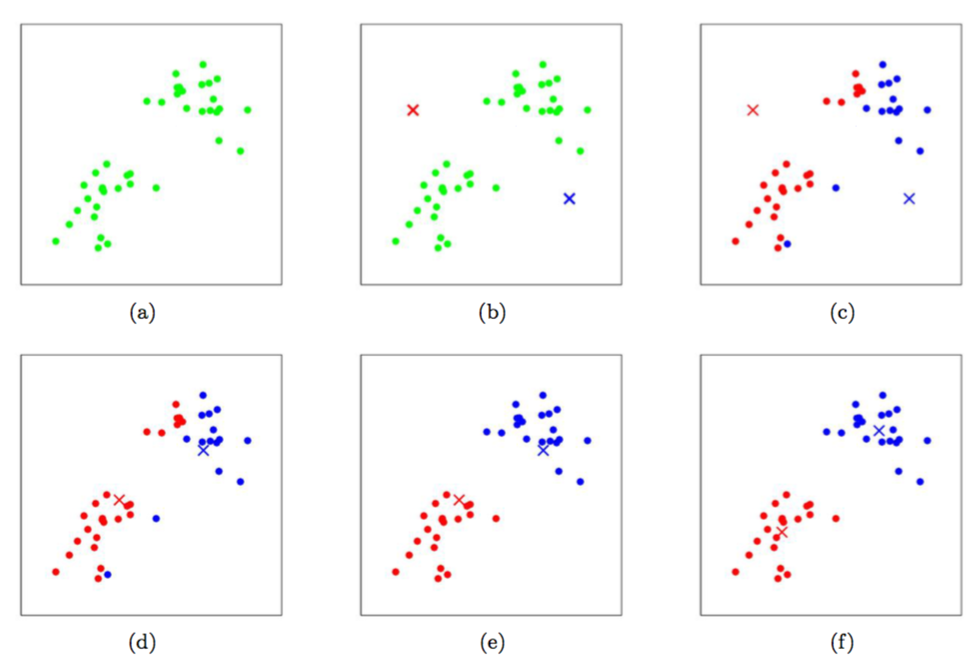
图1:$k$ 均值聚类算法。图中的圆形点表示的是训练样本,交叉符号表示的是聚类重心。(a) 原始训练样本数据集。 (b) 随机初始化的聚类重心(这里的初始化方法就跟我们上面说的不一样,并没有从训练样本中选择两个点)。(c-f) 运行 $k$ 均值聚类算法中的两步迭代的示意图。在每一次迭代中,我们把每个训练样本分配给距其最近的聚类重心(用同样颜色标识出),然后把聚类重心移动到所分配的样本的均值位置。(用颜色区分效果最好了。)图片引用自 Michael Jordan。
$K$ 均值聚类算法能保证收敛性么?可以的,至少在一定意义上能这么说。尤其是我们可以定义一个下面这样的函数作为失真函数(distortion function):
$$
J(c,\mu)=\sum_{i=1}^m ||x^{(i)}-\mu_{c^{(i)}}||^2
$$
这样就可以用 $J$ 来衡量每个样本 $x^{(i)}$ 和对应的聚类重心$\mu_{c^{(i)}}$之间距离的平方和。很明显能看出 $k$ 均值聚类算法正好就是对 $J$ 的坐标下降过程。尤其是内部的循环体中,$k$ 均值聚类算法重复对 $J$ 进行最小化,当 $\mu$ 固定的时候用 $c$ 来最小化 $J$,当 $c$ 固定的时候则用 $\mu$ 最小化 $J$。这样就保证了 $J$ 是单调降低的(monotonically decrease),它的值也就必然收敛(converge)。(通常这也表明了 $c$ 和 $\mu$ 也收敛。在理论上来讲,$k$均值 可能会在几种不同的聚类之间摆动(oscillate),也就是说某些组不同值的 $c$ 和/或 $\mu$ 对应有完全相同的 $J$ 值,不过在实践中这种情况几乎不会遇到。)
失真函数 $J$,是一个非凸函数(non-convex function),所以对 $J$ 进行坐标下降(coordinate descent)并不一定能够收敛到全局最小值(global minimum)。也就是说,$k$ 均值聚类算法可能只是局部最优的(local optima)。通常除了这个问题之外,$k$ 均值聚类效果都不错,能给出很好的聚类。如果你担心陷入到某些比较差的局部最小值,通常可以多次运行 $k$ 均值距离(使用不同的随机值进行来对聚类重心 $\mu_j$ 进行初始化)。然后从所有的不同聚类方案(clusterings)中,选择能提供最小失真(distortion) $J(c,\mu)$ 的。
第七章b
混合高斯 (Mixtures of Gaussians) 和期望最大化算法(the EM algorithm)
在本章讲义中,我们要讲的是使用期望最大化算法(EM,Expectation-Maximization)来进行密度估计(density estimation)。
一如既往,还是假设我们得到了某一个训练样本集${x^{(1)},…,x^{(m)}}$。由于这次是非监督学习(unsupervised learning)环境,所以这些样本就没有什么分类标签了。
我们希望能够获得一个联合分布 $p(x^{(i)},z^{(i)}) = p(x^{(i)}|z^{(i)})p(z^{(i)})$ 来对数据进行建模。其中的 $z^{(i)} \sim Multinomial(\phi)$ (即$z^{(i)}$ 是一个以 $\phi$ 为参数的多项式分布,其中 $\phi_j \ge 0, \sum_{j=1}^k \phi_j=1$,而参数 $\phi_j$ 给出了 $p(z^{(i)} = j)$),另外 $x^{(i)}|z^{(i)} = j \sim N(μ_j,\Sigma_j)$ (译者注:$x^{(i)}|z^{(i)} = j$是一个以 $μ_j$ 和 $\Sigma_j$ 为参数的正态分布)。我们设 $k$ 来表示 $z^{(i)}$ 能取的值的个数。因此,我们这个模型就是在假设每个$x^{(i)}$ 都是从${1, …, k}$中随机选取$z^{(i)}$来生成的,然后 $x^{(i)}$ 就是服从$k$个高斯分布中的一个,而这$k$个高斯分布又取决于$z^{(i)}$。这就叫做一个混合高斯模型(mixture of Gaussians model)。 此外还要注意的就是这里的 $z^{(i)}$ 是潜在的随机变量(latent random variables),这就意味着其取值可能还是隐藏的或者未被观测到的。这就会增加这个估计问题(estimation problem)的难度。
我们这个模型的参数也就是 $\phi, \mu$ 和 $\Sigma$。要对这些值进行估计,我们可以写出数据的似然函数(likelihood):
$$
\begin{aligned}
l(\phi,\mu,\Sigma) &= \sum_{i=1}^m \log p(x^{(i)};\phi,\mu,\Sigma) \
&= \sum_{i=1}^m \log \sum_{z^{(i)}=1}^k p(x^{(i)}|z^{(i)};\mu,\Sigma)p(z^{(i)};\phi)
\end{aligned}
$$
然而,如果我们用设上面方程的导数为零来尝试解各个参数,就会发现根本不可能以闭合形式(closed form)来找到这些参数的最大似然估计(maximum likelihood estimates)。(不信的话你自己试试咯。)
随机变量 $z^{(i)}$表示着 $x^{(i)}$ 所属于的 $k$ 个高斯分布值。这里要注意,如果我们已知 $z^{(i)}$,这个最大似然估计问题就简单很多了。那么就可以把似然函数写成下面这种形式:
$$
l(\phi,\mu,\Sigma)=\sum_{i=1}^m \log p(x^{(i)}|z^{(i)};\mu,\Sigma) + \log p(z^{(i)};\phi)
$$
对上面的函数进行最大化,就能得到对应的参数$\phi, \mu$ 和 $\Sigma$:
$$
\begin{aligned}
&\phi_j=\frac 1m\sum_{i=1}^m 1{z^{(i)}=j}, \
&\mu_j=\frac{\sum_{i=1}^m 1{z^{(i)}=j}x^{(i)}}{\sum_{i=1}^m 1{z^{(i)}=j}}, \
&\Sigma_j=\frac{\sum_{i=1}^m 1{z^{(i)}=j}(x^{(i)}-\mu_j)(x^{(i)}-\mu_j)^T}{\sum_{i=1}^m 1{z^{(i)}=j}}.
\end{aligned}
$$
事实上,我们已经看到了,如果 $z^{(i)}$ 是已知的,那么这个最大似然估计就几乎等同于之前用高斯判别分析模型(Gaussian discriminant analysis model)中对参数进行的估计,唯一不同在于这里的 $z^{(i)}$ 扮演了高斯判别分析当中的分类标签$^1$的角色。
1 这里的式子和之前在 PS1 中高斯判别分析的方程还有一些小的区别,这首先是因为在此处我们把 $z^{(i)}$ 泛化为多项式分布(multinomial),而不是伯努利分布(Bernoulli),其次是由于这里针对高斯分布中的每一项使用了一个不同的 $\Sigma_j$。
然而,在密度估计问题里面,$z^{(i)}$ 是不知道的。这要怎么办呢?
期望最大化算法(EM,Expectation-Maximization)是一个迭代算法,有两个主要的步骤。针对我们这个问题,在 $E$ 这一步中,程序是试图去“猜测(guess)” $z^{(i)}$ 的值。然后在 $M$ 这一步,就根据上一步的猜测来对模型参数进行更新。由于在 $M$ 这一步当中我们假设(pretend)了上一步是对的,那么最大化的过程就简单了。下面是这个算法:
 重复下列过程直到收敛(convergence): {
  ($E$-步骤)对每个 $i, j$, 设
$$
w_j^{(i)} := p(z^{(i)}=j|x^{(i)};\phi,\mu,\Sigma)
$$
  ($M$-步骤)更新参数:
$$
\begin{aligned}
&\phi_j=\frac 1m\sum_{i=1}^m w_j^{(i)}, \
&\mu_j=\frac{\sum_{i=1}^m w_j^{(i)}x^{(i)}}{\sum_{i=1}^m w_j^{(i)}}, \
&\Sigma_j=\frac{\sum_{i=1}^m w_j^{(i)}(x^{(i)}-\mu_j)(x^{(i)}-\mu_j)^T}{\sum_{i=1}^m w_j^{(i)}}.
\end{aligned}
$$
}
在 $E$ 步骤中,在给定 $x^{(i)}$ 以及使用当前参数设置(current setting of our parameters)情况下,我们计算出了参数 $z^{(i)}$ 的后验概率(posterior probability)。使用贝叶斯规则(Bayes rule),就得到下面的式子:
$$
p(z^{(i)}=j|x^{(i)};\phi,\mu,\Sigma)=
\frac{p(x^{(i)}|z^{(i)}=j;\mu,\Sigma)p(z^{(i)}=j;\phi)}
{\sum_{l=1}^k p(x^{(i)}|z^{(i)}=l;\mu,\Sigma)p(z^{(i)}=l;\phi)}
$$
上面的式子中,$p(z^{(i)}=j|x^{(i)};\phi,\mu,\Sigma)$ 是通过评估一个高斯分布的密度得到的,这个高斯分布的均值为 $\mu_i$,对$x^{(i)}$的协方差为$\Sigma_j$;$p(z^{(i)} = j;\phi)$ 是通过 $\phi_j$ 得到,以此类推。在 $E$ 步骤中计算出来的 $w_j^{(i)}$ 代表了我们对 $z^{(i)}$ 这个值的“弱估计(soft guesses)”$^2$。
2 这里用的词汇“弱(soft)”是指我们对概率进行猜测,从 $[0, 1]$ 这样一个闭区间进行取值;而与之对应的“强(hard)”值得是单次最佳猜测,例如从集合 ${0,1}$ 或者 ${1, …, k}$ 中取一个值。
另外在 $M$ 步骤中进行的更新还要与 $z^{(i)}$ 已知之后的方程式进行对比。它们是相同的,不同之处只在于之前使用的指示函数(indicator functions),指示每个数据点所属的高斯分布,而这里换成了 $w_j^{(i)}$。
$EM$ 算法也让人想起 $K$ 均值聚类算法,而在 $K$ 均值聚类算法中对聚类重心 $c(i)$ 进行了“强(hard)”赋值,而在 $EM$ 算法中,对$w_j^{(i)}$ 进行的是“弱(soft)”赋值。与 $K$ 均值算法类似,$EM$ 算法也容易导致局部最优,所以使用不同的初始参数(initial parameters)进行重新初始化(reinitializing),可能是个好办法。
很明显,$EM$ 算法对 $z^{(i)}$ 进行重复的猜测,这种思路很自然;但这个算法是怎么产生的,以及我们能否确保这个算法的某些特性,例如收敛性之类的?在下一章的讲义中,我们会讲解一种对 $EM$ 算法更泛化的解读,这样我们就可以在其他的估计问题中轻松地使用 $EM$ 算法了,只要这些问题也具有潜在变量(latent variables),并且还能够保证收敛。
第八章
第九部分 期望最大化算法(EM algorithm)
在前面的若干讲义中,我们已经讲过了期望最大化算法(EM algorithm),使用场景是对一个高斯混合模型进行拟合(fitting a mixture of Gaussians)。在本章里面,我们要给出期望最大化算法(EM algorithm)的更广泛应用,并且演示如何应用于一个大系列的具有潜在变量(latent variables)的估计问题(estimation problems)。我们的讨论从 Jensen 不等式(Jensen’s inequality) 开始,这是一个非常有用的结论。
1 Jensen 不等式(Jensen’s inequality)
设 $f$ 为一个函数,其定义域(domain)为整个实数域(set of real numbers)。这里要回忆一下,如果函数 $f$ 的二阶导数 $f’’(x) \ge 0$ (其中的 $x \in R$),则函数 $f$ 为一个凸函数(convex function)。如果输入的为向量变量,那么这个函数就泛化了,这时候该函数的海森矩阵(hessian) $H$ 就是一个半正定矩阵(positive semi-definite $H \ge 0$)。如果对于所有的 $x$ ,都有二阶导数 $f’’(x) > 0$,那么我们称这个函数 $f$ 是严格凸函数(对应向量值作为变量的情况,对应的条件就是海森矩阵必须为正定,写作 $H > 0$)。这样就可以用如下方式来表述 Jensen 不等式:
定理(Theorem): 设 $f$ 是一个凸函数,且设 $X$ 是一个随机变量(random variable)。然后则有:
$$
E[f(X)] \ge f(EX).
$$
译者注:函数的期望大于等于期望的函数值
此外,如果函数 $f$ 是严格凸函数,那么 $E[f(X)] = f(EX)$ 当且仅当 $X = E[X]$ 的概率(probability)为 $1$ 的时候成立(例如 $X$ 是一个常数)。
还记得我们之前的约定(convention)吧,写期望(expectations)的时候可以偶尔去掉括号(parentheses),所以在上面的定理中, $f(EX) = f(E[X])$。
为了容易理解这个定理,可以参考下面的图:
上图中,$f$ 是一个凸函数,在图中用实线表示。另外 $X$ 是一个随机变量,有 $0.5$ 的概率(chance)取值为 $a$,另外有 $0.5$ 的概率取值为 $b$(在图中 $x$ 轴上标出了)。这样,$X$ 的期望值就在图中所示的 $a$ 和 $b$ 的中点位置。
图中在 $y$ 轴上也标出了 $f(a)$, $f(b)$ 和 $f(E[X])$。接下来函数的期望值 $E[f(X)]$ 在 $y$ 轴上就处于 $f(a)$ 和 $f(b)$ 之间的中点的位置。如图中所示,在这个例子中由于 $f$ 是凸函数,很明显 $E[f(X)] ≥ f(EX)$。
顺便说一下,很多人都记不住不等式的方向,所以就不妨用画图来记住,这是很好的方法,还可以通过图像很快来找到答案。
备注。 回想一下,当且仅当 $-f$ 是严格凸函数([strictly] convex)的时候,$f$ 是严格凹函数([strictly] concave)(例如,二阶导数 $f’’(x)\le 0$ 或者其海森矩阵 $H ≤ 0$)。Jensen 不等式也适用于凹函数(concave)$f$,但不等式的方向要反过来,也就是对于凹函数,$E[f(X)] \le f(EX)$。
2 期望最大化算法(EM algorithm)
假如我们有一个估计问题(estimation problem),其中由训练样本集 ${x^{(1)}, …, x^{(m)}}$ 包含了 $m$ 个独立样本。我们用模型 $p(x, z)$ 对数据进行建模,拟合其参数(parameters),其中的似然函数(likelihood)如下所示:
$$
\begin{aligned}
l(\theta) &= \sum_{i=1}^m\log p(x;\theta) \
&= \sum_{i=1}^m\log\sum_z p(x,z;\theta)
\end{aligned}
$$
然而,确切地找到对参数 $\theta$ 的最大似然估计(maximum likelihood estimates)可能会很难。此处的 $z^{(i)}$ 是一个潜在的随机变量(latent random variables);通常情况下,如果 $z^{(i)}$ 事先得到了,然后再进行最大似然估计,就容易多了。
这种环境下,使用期望最大化算法(EM algorithm)就能很有效地实现最大似然估计(maximum likelihood estimation)。明确地对似然函数$l(\theta)$进行最大化可能是很困难的,所以我们的策略就是使用一种替代,在 $E$ 步骤 构建一个 $l$ 的下限(lower-bound),然后在 $M$ 步骤 对这个下限进行优化。
对于每个 $i$,设 $Q_i$ 是某个对 $z$ 的分布($\sum_z Q_i(z) = 1, Q_i(z)\ge 0$)。则有下列各式$^1$:
$$
\begin{aligned}
\sum_i\log p(x^{(i)};\theta) &= \sum_i\log\sum_{z^{(i)}}p(x^{(i)},z^{(i)};\theta)&(1) \
&= \sum_i\log\sum_{z^{(i)}}Q_i(z^{(i)})\frac{p(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})} &(2)\
&\ge \sum_i\sum_{z^{(i)}}Q_i(z^{(i)})\log\frac{p(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})}&(3)
\end{aligned}
$$
1 如果 $z$ 是连续的,那么 $Q_i$ 就是一个密度函数(density),上面讨论中提到的对 $z$ 的求和(summations)就要用对 $z$ 的积分(integral)来替代。
上面推导(derivation)的最后一步使用了 Jensen 不等式(Jensen’s inequality)。其中的 $f(x) = log x$ 是一个凹函数(concave function),因为其二阶导数 $f’’(x) = -1/x^2 < 0$ 在整个定义域(domain) $x\in R^+$ 上都成立。
此外,上式的求和中的单项:
$$
\sum_{z^{(i)}}Q_i(z^{(i)})[\frac{p(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})}]
$$
是变量(quantity)$[p(x^{(i)}, z^{(i)}; \theta)/Q_i(z^{(i)})]$ 基于 $z^{(i)}$ 的期望,其中 $z^{(i)}$ 是根据 $Q_i$ 给定的分布确定。然后利用 Jensen 不等式(Jensen’s inequality),就得到了:
$$
f(E_{z^{(i)}\sim Q_i}[\frac{p(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})}])\ge
E_{z^{(i)}\sim Q_i}[f(\frac{p(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})})]
$$
其中上面的角标 $“z^{(i)}\sim Q_i”$ 就表明这个期望是对于依据分布 $Q_i$ 来确定的 $z^{(i)}$ 的。这样就可以从等式 $(2)$ 推导出等式 $(3)$。
接下来,对于任意的一个分布 $Q_i$,上面的等式 $(3)$ 就给出了似然函数 $l(\theta)$ 的下限(lower-bound)。那么对于 $Q_i$ 有很多种选择。咱们该选哪个呢?如果我们对参数 $\theta$ 有某种当前的估计,很自然就可以设置这个下限为 $\theta$ 这个值。也就是,针对当前的 $\theta$ 值,我们令上面的不等式中的符号为等号。(稍后我们能看到,这样就能证明,随着 $EM$迭代过程的进行,似然函数 $l(\theta)$ 就会单调递增(increases monotonically)。)
为了让上面的限定值(bound)与 $\theta$ 特定值(particular value)联系紧密(tight),我们需要上面推导过程中的 Jensen 不等式这一步中等号成立。要让这个条件成立,我们只需确保是在对一个常数值随机变量(“constant”-valued random variable)求期望。也就是需要:
$$
\frac{p(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})}=c
$$
其中常数 $c$ 不依赖 $z^{(i)}$。要实现这一条件,只需满足:
$$
Q_i(z^{(i)})\propto p(x^{(i)},z^{(i)};\theta)
$$
实际上,由于我们已知 $\sum_z Q_i(z^{(i)}) = 1$(因为这是一个分布),这就进一步表明:
$$
\begin{aligned}
Q_i(z^{(i)}) &= \frac{p(x^{(i)},z^{(i)};\theta)}{\sum_z p(x^{(i)},z;\theta)} \
&= \frac{p(x^{(i)},z^{(i)};\theta)}{p(x^{(i)};\theta)} \
&= p(z^{(i)}|x^{(i)};\theta)
\end{aligned}
$$
因此,在给定 $x^{(i)}$ 和参数 $\theta$ 的设置下,我们可以简单地把 $Q_i$ 设置为 $z^{(i)}$ 的后验分布(posterior distribution)。
接下来,对 $Q_i$ 的选择,等式 $(3)$ 就给出了似然函数对数(log likelihood)的一个下限,而似然函数(likelihood)正是我们要试图求最大值(maximize)的。这就是 $E$ 步骤。接下来在算法的 $M$ 步骤中,就最大化等式 $(3)$ 当中的方程,然后得到新的参数 $\theta$。重复这两个步骤,就是完整的 $EM$ 算法,如下所示:
 重复下列过程直到收敛(convergence): {
  ($E$ 步骤)对每个 $i$,设
$$
Q_i(z^{(i)}):=p(z^{(i)}|x^{(i)};\theta)
$$
  ($M$ 步骤) 设
$$
\theta := arg\max_\theta\sum_i\sum_{z^{(i)}}Q_i(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})}
$$
}
怎么才能知道这个算法是否会收敛(converge)呢?设 $\theta^{(t)}$ 和 $\theta^{(t+1)}$ 是上面 $EM$ 迭代过程中的某两个参数(parameters)。接下来我们就要证明一下 $l(\theta^{(t)})\le l(\theta^{(t+1)})$,这就表明 $EM$ 迭代过程总是让似然函数对数(log-likelihood)单调递增(monotonically improves)。证明这个结论的关键就在于对 $Q_i$ 的选择中。在上面$EM$迭代中,参数的起点设为 $\theta^{(t)}$,我们就可以选择 $Q_i^{(t)}(z^{(i)}): = p(z^{(i)}|x^{(i)};\theta^{(t)})$。之前我们已经看到了,正如等式 $(3)$ 的推导过程中所示,这样选择能保证 Jensen 不等式的等号成立,因此:
$$
l(\theta^{(t)})=\sum_i\sum_{z^{(i)}}Q_i^{(t)}(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta^{(t)})}{Q_i^{(t)}(z^{(i)})}
$$
参数 $\theta^{(t+1)}$ 可以通过对上面等式中等号右侧进行最大化而得到。因此:
$$
\begin{aligned}
l(\theta^{(t+1)}) &\ge \sum_i\sum_{z^{(i)}}Q_i^{(t)}(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta^{(t+1)})}{Q_i^{(t)}(z^{(i)})} &(4)\
&\ge \sum_i\sum_{z^{(i)}}Q_i^{(t)}(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta^{(t)})}{Q_i^{(t)}(z^{(i)})} &(5)\
&= l(\theta^{(t)}) &(6)
\end{aligned}
$$
上面的第一个不等式推自:
$$
l(\theta)\ge \sum_i\sum_{z^{(i)}}Q_i(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})}
$$
上面这个不等式对于任意值的 $Q_i$ 和 $\theta$ 都成立,尤其当 $Q_i = Q_i^{(t)}, \theta = \theta^{(t+1)}$。要得到等式 $(5)$,我们要利用 $\theta^{(t+1)}$ 的选择能够保证:
$$
arg\max_\theta \sum_i\sum_{z^{(i)}}Q_i(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})}
$$
这个式子对 $\theta^{(t+1)}$ 得到的值必须大于等于 $\theta^{(t)}$ 得到的值。最后,推导等式$(6)$ 的这一步,正如之前所示,因为在选择的时候我们选的 $Q_i^{(t)}$ 就是要保证 Jensen 不等式对 $\theta^{(t)}$ 等号成立。
因此,$EM$ 算法就能够导致似然函数(likelihood)的单调收敛。在我们推导 $EM$ 算法的过程中,我们要一直运行该算法到收敛。得到了上面的结果之后,可以使用一个合理的收敛检测(reasonable convergence test)来检查在成功的迭代(successive iterations)之间的 $l(\theta)$ 的增长是否小于某些容忍参数(tolerance parameter),如果 $EM$ 算法对 $l(\theta)$ 的增大速度很慢,就声明收敛(declare convergence)。
备注。 如果我们定义
$$
J(Q, \theta)=\sum_i\sum_{z^{(i)}}Q_i(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta)}{Q_i(z^{(i)})}
$$
通过我们之前的推导,就能知道 $l(\theta) ≥ J(Q, \theta)$。这样 $EM$ 算法也可看作是在 $J$ 上的坐标上升(coordinate ascent),其中 $E$ 步骤在 $Q$ 上对 $J$ 进行了最大化(自己检查哈),然后 $M$ 步骤则在 $\theta$ 上对 $J$ 进行最大化。
3 高斯混合模型回顾(Mixture of Gaussians revisited )
有了对 $EM$ 算法的广义定义(general definition)之后,我们就可以回顾一下之前的高斯混合模型问题,其中要拟合的参数有 $\phi, \mu$ 和$\Sigma$。为了避免啰嗦,这里就只给出在 $M$ 步骤中对$\phi$ 和 $\mu_j$ 进行更新的推导,关于 $\Sigma_j$ 的更新推导就由读者当作练习自己来吧。
$E$ 步骤很简单。还是按照上面的算法推导过程,只需要计算:
$$
w_j^{(i)}=Q_i(z^{(i)}=j)=P(z^{(i)}=j|x^{(i)};\phi,\mu,\Sigma)
$$
这里面的 $“Q_i(z^{(i)} = j)”$ 表示的是在分布 $Q_i$上 $z^{(i)}$ 取值 $j$ 的概率。
接下来在 $M$ 步骤,就要最大化关于参数 $\phi,\mu,\Sigma$的值:
$$
\begin{aligned}
\sum_{i=1}^m&\sum_{z^{(i)}}Q_i(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\phi,\mu,\Sigma)}{Q_i(z^{(i)})}\
&= \sum_{i=1}^m\sum_{j=1}^kQ_i(z^{(i)}=j)log\frac{p(x^{(i)}|z^{(i)}=j;\mu,\Sigma)p(z^{(i)}=j;\phi)}{Q_i(z^{(i)}=j)} \
&= \sum_{i=1}^m\sum_{j=1}^kw_j^{(i)}log\frac{\frac{1}{(2\pi)^{n/2}|\Sigma_j|^{1/2}}exp(-\frac 12(x^{(i)}-\mu_j)^T\Sigma_j^{-1}(x^{(i)}-\mu_j))\cdot\phi_j}{w_j^{(i)}}
\end{aligned}
$$
先关于 $\mu_l$ 来进行最大化。如果去关于 $\mu_l$ 的(偏)导数(derivative),得到:
$$
\begin{aligned}
\nabla_{\mu_l}&\sum_{i=1}^m\sum_{j=1}^kw_j^{(i)}log\frac{\frac{1}{(2\pi)^{n/2}|\Sigma_j|^{1/2}}exp(-\frac 12(x^{(i)}-\mu_j)^T\Sigma_j^{-1}(x^{(i)}-\mu_j))\cdot\phi_j}{w_j^{(i)}} \
&= -\nabla_{\mu_l}\sum_{i=1}^m\sum_{j=1}^kw_j^{(i)}\frac 12(x^{(i)}-\mu_j)^T\Sigma_j^{-1}(x^{(i)}-\mu_j) \
&= \frac 12\sum_{i=1}^m w_l^{(i)}\nabla_{\mu_l}2\mu_l^T\Sigma_l^{-1}x^{(i)}-\mu_l^T\Sigma_l^{-1}\mu_l \
&= \sum_{i=1}^m w_l^{(i)}(\Sigma_l^{-1}x^{(i)}-\Sigma_l^{-1}\mu_l)
\end{aligned}
$$
设上式为零,然后解出 $\mu_l$ 就产生了更新规则(update rule):
$$
\mu_l := \frac{\sum_{i=1}^m w_l^{(i)}x^{(i)}}{\sum_{i=1}^m w_l^{(i)}}
$$
这个结果咱们在之前的讲义中已经见到过了。
咱们再举一个例子,推导在 $M$ 步骤中参数 $\phi_j$ 的更新规则。把仅关于参数 $\phi_j$ 的表达式结合起来,就能发现只需要最大化下面的表达式:
$$
\sum_{i=1}^m\sum_{j=1}^kw_j^{(i)}log\phi_j
$$
然而,还有一个附加的约束,即 $\phi_j$ 的和为$1$,因为其表示的是概率 $\phi_j = p(z^{(i)} = j;\phi)$。为了保证这个约束条件成立,即 $\sum^k_{j=1}\phi_j = 1$,我们构建一个拉格朗日函数(Lagrangian):
$$
\mathcal L(\phi)=\sum_{i=1}^m\sum_{j=1}^kw_j^{(i)}log\phi_j+\beta(\sum^k_{j=1}\phi_j - 1)
$$
其中的 $\beta$ 是 拉格朗日乘数(Lagrange multiplier)$^2$ 。求导,然后得到:
$$
\frac{\partial}{\partial{\phi_j}}\mathcal L(\phi)=\sum_{i=1}^m\frac{w_j^{(i)}}{\phi_j}+1
$$
2 这里我们不用在意约束条件 $\phi_j \ge 0$,因为很快就能发现,这里推导得到的解会自然满足这个条件的。
设导数为零,然后解方程,就得到了:
$$
\phi_j=\frac{\sum_{i=1}^m w_j^{(i)}}{-\beta}
$$
也就是说,$\phi_j\propto \sum_{i=1}^m w_j^{(i)} $。结合约束条件(constraint)$\Sigma_j \phi_j = 1$,可以很容易地发现 $-\beta = \sum_{i=1}^m\sum_{j=1}^kw_j^{(i)} = \sum_{i=1}^m 1 =m$. (这里用到了条件 $w_j^{(i)} =Q_i(z^{(i)} = j)$,而且因为所有概率之和等于$1$,即$\sum_j w_j^{(i)}=1$)。这样我们就得到了在 $M$ 步骤中对参数 $\phi_j$ 进行更新的规则了:
$$
\phi_j := \frac 1m \sum_{i=1}^m w_j^{(i)}
$$
接下来对 $M$ 步骤中对 $\Sigma_j$ 的更新规则的推导就很容易了。
第九章
第十部分 因子分析(Factor analysis)
如果有一个从多个高斯混合模型(a mixture of several Gaussians)而来的数据集 $x^{(i)} \in R^n$ ,那么就可以用期望最大化算法(EM algorithm)来对这个混合模型(mixture model)进行拟合。这种情况下,对于有充足数据(sufficient data)的问题,我们通常假设可以从数据中识别出多个高斯模型结构(multiple-Gaussian structure)。例如,如果我们的训练样本集合规模(training set size) $m$ 远远大于(significantly larger than)数据的维度(dimension) $n$,就符合这种情况。
然后来考虑一下反过来的情况,也就是 $n$ 远远大于 $m$,即 $n \gg m$。在这样的问题中,就可能用单独一个高斯模型来对数据建模都很难,更不用说多个高斯模型的混合模型了。由于 $m$ 个数据点所张成(span)的只是一个 $n$ 维空间 $R^n$ 的低维度子空间(low-dimensional subspace),如果用高斯模型(Gaussian)对数据进行建模,然后还是用常规的最大似然估计(usual maximum likelihood estimators)来估计(estimate)平均值(mean)和方差(covariance),得到的则是:
$$
\begin{aligned}
&\mu = \frac 1m\sum_{i=1}^m x^{(i)} \
&\Sigma = \frac 1m\sum_{i=1}^m (x^{(i)}-\mu)(x^{(i)}-\mu)^T
\end{aligned}
$$
我们会发现这里的 $\Sigma$ 是一个奇异(singular)矩阵。这也就意味着其逆矩阵 $\Sigma^{-1}$ 不存在,而 $1/|\Sigma|^{1/2} = 1/0$。 但这几个变量都还是需要的,要用来计算一个多元高斯分布(multivariate Gaussian distribution)的常规密度函数(usual density)。还可以用另外一种方法来讲述清楚这个难题,也就是对参数(parameters)的最大似然估计(maximum likelihood estimates)会产生一个高斯分布(Gaussian),其概率分布在由样本数据$^1$所张成的仿射空间(affine space)中,对应着一个奇异的协方差矩阵(singular covariance matrix)。
1 这是一个点集,对于某些 $\alpha_i$,此集合中的点 $x$ 都满足 $x = \sum_{i=1}^m \alpha_i x^{(i)}$, 因此 $\sum_{i=1}^m \alpha_1 = 1$。
通常情况下,除非 $m$ 比 $n$ 大出相当多(some reasonable amount),否则最大似然估计(maximum likelihood estimates)得到的均值(mean)和方差(covariance)都会很差(quite poor)。尽管如此,我们还是希望能用已有的数据,拟合出一个合理(reasonable)的高斯模型(Gaussian model),而且还希望能识别出数据中的某些有意义的协方差结构(covariance structure)。那这可怎么办呢?
在接下来的这一部分内容里,我们首先回顾一下对 $\Sigma$ 的两个可能的约束(possible restrictions),这两个约束条件能让我们使用小规模数据来拟合 $\Sigma$,但都不能就我们的问题给出让人满意的解(satisfactory solution)。然后接下来我们要讨论一下高斯模型的一些特点,这些后面会用得上,具体来说也就是如何找到高斯模型的边界和条件分布。最后,我们会讲一下因子分析模型(factor analysis model),以及对应的期望最大化算法(EM algorithm)。
1 $\Sigma$ 的约束条件(Restriction)
如果我们没有充足的数据来拟合一个完整的协方差矩阵(covariance matrix),就可以对矩阵空间 $\Sigma$ 给出某些约束条件(restrictions)。例如,我们可以选择去拟合一个对角(diagonal)的协方差矩阵 $\Sigma$。这样,读者很容易就能验证这样的一个协方差矩阵的最大似然估计(maximum likelihood estimate)可以由对角矩阵(diagonal matrix) $\Sigma$ 满足:
$$
\Sigma_{jj} = \frac 1m \sum_{i=1}^m (x_j^{(i)}-\mu_j)^2
$$
因此,$\Sigma_{jj}$ 就是对数据中第 $j$ 个坐标位置的方差值的经验估计(empirical estimate)。
回忆一下,高斯模型的密度的形状是椭圆形的。对角线矩阵 $\Sigma$ 对应的就是椭圆长轴(major axes)对齐(axis- aligned)的高斯模型。
有时候,我们还要对这个协方差矩阵(covariance matrix)给出进一步的约束,不仅设为对角的(major axes),还要求所有对角元素(diagonal entries)都相等。这时候,就有 $\Sigma = \sigma^2I$,其中 $\sigma^2$ 是我们控制的参数。对这个 $\sigma^2$ 的最大似然估计则为:
$$
\sigma^2 = \frac 1{mn} \sum_{j=1}^n\sum_{i=1}^m (x_j^{(i)}-\mu_j)^2
$$
这种模型对应的是密度函数为圆形轮廓的高斯模型(在二维空间也就是平面中是圆形,在更高维度当中就是球(spheres)或者超球体(hyperspheres))。
如果我们对数据要拟合一个完整的,不受约束的(unconstrained)协方差矩阵 $\Sigma$,就必须满足 $m \ge n + 1$,这样才使得对 $\Sigma$ 的最大似然估计不是奇异矩阵(singular matrix)。在上面提到的两个约束条件之下,只要 $m \ge 2$,我们就能获得非奇异的(non-singular) $\Sigma$。
然而,将 $\Sigma$ 限定为对角矩阵,也就意味着对数据中不同坐标(coordinates)的 $x_i,x_j$建模都将是不相关的(uncorrelated),且互相独立(independent)。通常,还是从样本数据里面获得某些有趣的相关信息结构比较好。如果使用上面对 $\Sigma$ 的某一种约束,就可能没办法获取这些信息了。在本章讲义里面,我们会提到因子分析模型(factor analysis model),这个模型使用的参数比对角矩阵 $\Sigma$ 更多,而且能从数据中获得某些相关性信息(captures some correlations),但也不能对完整的协方差矩阵(full covariance matrix)进行拟合。
2 多重高斯模型(Gaussians )的边界(Marginal)和条件(Conditional)
在讲解因子分析(factor analysis)之前,我们要先说一下一个联合多元高斯分布(joint multivariate Gaussian distribution)下的随机变量(random variables)的条件(conditional)和边界(marginal)分布(distributions)。
假如我们有一个值为向量的随机变量(vector-valued random variable):
$$
x=\begin{bmatrix}
x_1 \ x_2
\end{bmatrix}
$$
其中 $x_1 \in R^r, x_2 \in R^s$,因此 $x \in R^{r+s}$。设 $x\sim N(\mu,\Sigma)$,则这两个参数为:
$$
\mu=\begin{bmatrix}
\mu_1 \ \mu_2
\end{bmatrix}\qquad
\Sigma = \begin{bmatrix}
\Sigma_{11} & \Sigma_{12} \ \Sigma_{21} & \Sigma_{22}
\end{bmatrix}
$$
其中, $\mu_1 \in R^r, \mu_2 \in R^s, \Sigma_{11} \in R^{r\times r}, \Sigma_{12} \in R^{r\times s}$,以此类推。由于协方差矩阵(covariance matrices)是对称的(symmetric),所以有 $\Sigma_{12} = \Sigma_{21}^T$。
基于我们的假设,$x_1$ 和 $x_2$ 是联合多元高斯分布(jointly multivariate Gaussian)。 那么 $x_1$ 的边界分布是什么?不难看出 $x_1$ 的期望 $E[x_1] = \mu_1$ ,而协方差 $Cov(x_1) = E[(x_1 - \mu_1)(x_1 - \mu_1)] = \Sigma_{11}$。接下来为了验证后面这一项成立,要用 $x_1$ 和 $x_2$的联合方差的概念:
$$
\begin{aligned}
Cov(x) &= \Sigma \
&= \begin{bmatrix}
\Sigma_{11} & \Sigma_{12} \ \Sigma_{21} & \Sigma_{22}
\end{bmatrix} \
&= E[(x-\mu)(x-\mu)^T] \
&= E\begin{bmatrix}
\begin{pmatrix}x_1-\mu_1 \ x_2-\mu_2\end{pmatrix} &
\begin{pmatrix}x_1-\mu_1 \ x_2-\mu_2\end{pmatrix}^T
\end{bmatrix} \
&= \begin{bmatrix}(x_1-\mu_1)(x_1-\mu_1)^T & (x_1-\mu_1)(x_2-\mu_2)^T\
(x_2-\mu_2)(x_1-\mu_1)^T & (x_2-\mu_2)(x_2-\mu_2)^T
\end{bmatrix}
\end{aligned}
$$
在上面的最后两行中,匹配(Matching)矩阵的左上方子阵(upper-left sub blocks),就可以得到结果了。
高斯分布的边界分布(marginal distributions)本身也是高斯分布,所以我们就可以给出一个正态分布 $x_1\sim N(\mu_,\Sigma_{11})$ 来作为 $x_1$ 的边界分布(marginal distributions)。
此外,我们还可以提出另一个问题,给定 $x_2$ 的情况下 $x_1$ 的条件分布是什么呢?通过参考多元高斯分布的定义,就能得到这个条件分布 $x_1|x_2 \sim N (\mu_{1|2}, \Sigma_{1|2})$为:
$$
\begin{aligned}
&\mu_{1|2} = \mu_1 + \Sigma_{12}\Sigma_{22}^{-1}(x_2-\mu_2)\qquad&(1) \
&\Sigma_{1|2} = \Sigma_{11} - \Sigma_{12}\Sigma_{22}^{-1}\Sigma_{21}&(2)
\end{aligned}
$$
在下一节对因子分析模型(factor analysis model)的讲解中,上面这些公式就很有用了,可以帮助寻找高斯分布的条件和边界分布(conditional and marginal distributions)。
3 因子分析模型(Factor analysis model)
在因子分析模型(factor analysis model)中,我们制定在 $(x, z)$ 上的一个联合分布,如下所示,其中 $z \in R^k$ 是一个潜在随机变量(latent random variable):
$$
\begin{aligned}
z &\sim N(0,I) \
x|z &\sim N(\mu+\Lambda z,\Psi)
\end{aligned}
$$
上面的式子中,我们这个模型中的参数是向量 $\mu \in R^n$ ,矩阵 $\Lambda \in R^{n×k}$,以及一个对角矩阵 $\Psi \in R^{n×n}$。$k$ 的值通常都选择比 $n$ 小一点的。
这样,我们就设想每个数据点 $x^{(i)}$ 都是通过在一个 $k$ 维度的多元高斯分布 $z^{(i)}$ 中取样获得的。然后,通过计算 $\mu+\Lambda z^{(i)}$,就可以映射到实数域 $R^n$ 中的一个 $k$ 维仿射空间(k-dimensional affine space),在 $\mu + \Lambda z^{(i)}$ 上加上协方差 $\Psi$ 作为噪音,就得到了 $x^{(i)}$。
反过来,咱们也就可以来定义因子分析模型(factor analysis model),使用下面的设定:
$$
\begin{aligned}
z &\sim N(0,I) \
\epsilon &\sim N(0,\Psi) \
x &= \mu + \Lambda z + \epsilon
\end{aligned}
$$
其中的 $\epsilon$ 和 $z$ 是互相独立的。
然后咱们来确切地看看这个模型定义的分布(distribution our)。其中,随机变量 $z$ 和 $x$ 有一个联合高斯分布(joint Gaussian distribution):
$$
\begin{bmatrix}
z\x
\end{bmatrix}\sim N(\mu_{zx},\Sigma)
$$
然后咱们要找到 $\mu_{zx}$ 和 $\Sigma$。
我们知道 $z$ 的期望 $E[z] = 0$,这是因为 $z$ 服从的是均值为 $0$ 的正态分布 $z\sim N(0,I)$。 此外我们还知道:
$$
\begin{aligned}
E[x] &= E[\mu + \Lambda z + \epsilon] \
&= \mu + \Lambda E[z] + E[\epsilon] \
&= \mu
\end{aligned}
$$
综合以上这些条件,就得到了:
$$
\mu_{zx} = \begin{bmatrix}
\vec{0}\ \mu
\end{bmatrix}
$$
下一步就是要找出 $\Sigma$,我们需要计算出 $\Sigma_{zz} = E[(z - E[z])(z - E[z])^T]$(矩阵$\Sigma$的左上部分(upper-left block)),$\Sigma_{zx} = E[(z - E[z])(x - E[x])^T]$(右上部分(upper-right block)),以及$\Sigma_{xx}=E[(x - E[x])(x - E[x])^T]$ (右下部分(lower-right block))。
由于 $z$ 是一个正态分布 $z \sim N (0, I)$,很容易就能知道 $\Sigma_{zz} = Cov(z) = I$。另外:
$$
\begin{aligned}
E[(z - E[z])(x - E[x])^T] &= E[z(\mu+\Lambda z+\epsilon-\mu)^T] \
&= E[zz^T]\Lambda^T+E[z\epsilon^T] \
&= \Lambda^T
\end{aligned}
$$
在上面的最后一步中,使用到了结论 $E[zz^T] = Cov(z)$(因为 $z$ 的均值为 $0$),而且 $E[z\epsilon^T ] = E[z]E[\epsilon^T ] = 0$)(因为 $z$ 和 $\epsilon$ 相互独立,因此乘积(product)的期望(expectation)等于期望的乘积)。
同样的方法,我们可以用下面的方法来找到 $\Sigma_{xx}$:
$$
\begin{aligned}
E[(x - E[x])(x - E[x])^T] &= E[\mu+\Lambda z+\epsilon-\mu)(\mu+\Lambda z+\epsilon-\mu)^T] \
&= E[\Lambda zz^T\Lambda^T+\epsilon z^T\Lambda^T+\Lambda z\epsilon^T+\epsilon\epsilon^T] \
&= \Lambda E[zz^T]\Lambda^T+E[\epsilon\epsilon^T] \
&= \Lambda\Lambda^T+\Psi
\end{aligned}
$$
把上面这些综合到一起,就得到了:
$$
\begin{bmatrix}
z\x
\end{bmatrix}\sim
\begin{pmatrix}
\begin{bmatrix}
\vec{0}\ \mu
\end{bmatrix},\begin{bmatrix}
I&\Lambda^T\ \Lambda&\Lambda\Lambda^T+\Psi
\end{bmatrix}
\end{pmatrix}\qquad(3)
$$
因此,我们还能发现 $x$ 的边界分布(marginal distribution)为 $x \sim N(\mu,\Lambda\Lambda^T +\Psi)$。所以,给定一个训练样本集合 ${x^{(i)}; i = 1, …, m}$,参数(parameters)的最大似然估计函数的对数函数(log likelihood),就可以写为:
$$
l(\mu,\Lambda,\Psi)=log\prod_{i=1}^m\frac{1}
{(2\pi)^{n/2}|\Lambda\Lambda^T+\Psi|^{1/2}}
exp(-\frac 12(x^{(i)}-\mu)^T(\Lambda\Lambda^T+\Psi)^{-1}(x^{(i)}-\mu))
$$
为了进行最大似然估计,我们就要最大化上面这个关于参数的函数。但确切地对上面这个方程式进行最大化,是很难的,不信你自己试试哈,而且我们都知道没有算法能够以封闭形式(closed-form)来实现这个最大化。所以,我们就改用期望最大化算法(EM algorithm)。下一节里面,咱们就来推导一下针对因子分析模型(factor analysis)的期望最大化算法(EM)。
4 针对因子分析模型(factor analysis)的期望最大化算法(EM)
$E$ 步骤的推导很简单。只需要计算出来 $Q_i(z^{(i)}) = p(z^{(i)}|x^{(i)}; \mu, \Lambda, \Psi)$。把等式$(3)$ 当中给出的分布代入到方程$(1-2)$,来找出一个高斯分布的条件分布,我们就能发现 $z^{(i)}|x^{(i)}; \mu, \Lambda, \Psi \sim N (\mu_{z^{(i)}|x^{(i)}} , \Sigma_{z^{(i)}|x^{(i)}} )$,其中:
$$
\begin{aligned}
\mu_{z^{(i)}|x^{(i)}}&=\Lambda^T(\Lambda\Lambda^T+\Psi)^{-1}(x^{(i)}-\mu) \
\Sigma_{z^{(i)}|x^{(i)}}&=I-\Lambda^T(\Lambda\Lambda^T+\Psi)^{-1}\Lambda
\end{aligned}
$$
所以,通过对 $\mu_{z^{(i)}|x^{(i)}}$ 和 $\Sigma_{z^{(i)}|x^{(i)}}$,进行这样的定义,就能得到:
$$
Q_i(z^{(i)})=\frac{1}
{(2\pi)^{k/2}|\Sigma_{z^{(i)}|x^{(i)}}|^{1/2}}
exp(-\frac 12(z^{(i)}-\mu_{z^{(i)}|x^{(i)}})^T\Sigma_{z^{(i)}|x^{(i)}}^{-1}(z^{(i)}-\mu_{z^{(i)}|x^{(i)}}))
$$
接下来就是 $M$ 步骤了。这里需要去最大化下面这个关于参数 $\mu, \Lambda$, $\Psi$ 的函数值:
$$
\sum_{i=1}^m\int_{z^{(i)}}Q_i(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\mu,\Lambda,\Psi)}{Q_i(z^{(i)})}dz^{(i)}\qquad(4)
$$
我们在本文中仅仅对 $\Lambda$ 进行优化,关于 $\mu$ 和 $\Psi$ 的更新就作为练习留给读者自己进行推导了。
把等式$(4)$ 简化成下面的形式:
$$
\begin{aligned}
\sum_{i=1}^m&\int_{z^{(i)}}Q_i(z^{(i)})[log p(x^{(i)}|z^{(i)};\mu,\Lambda,\Psi)+log p(z^{(i)})-log Q_i(z^{(i)})]dz^{(i)} &(5)\
&=\sum_{i=1}^m E_{z^{(i)}\sim Q_i}[log p(x^{(i)}|z^{(i)};\mu,\Lambda,\Psi)+log p(z^{(i)})-log Q_i(z^{(i)})] &(6)
\end{aligned}
$$
上面的等式中,$“z^{(i)} \sim Q_i”$ 这个下标(subscript),表示的意思是这个期望是关于从 $Q_i$ 中取得的 $z^{(i)}$ 的。在后续的推导过程中,如果没有歧义的情况下,我们就会把这个下标省略掉。删除掉这些不依赖参数的项目后,我们就发现只需要最大化:
$$
\begin{aligned}
\sum_{i=1}^m&E[log p(x^{(i)}|z^{(i)};\mu,\Lambda,\Psi)] \
&=\sum_{i=1}^m E[log\frac{1}{(2\pi)^{n/2}|\Psi|^{1/2}}
exp(-\frac 12(x^{(i)}-\mu-\Lambda z^{(i)})^T\Psi^{-1}(x^{(i)}-\mu-\Lambda z^{(i)}))] \
&=\sum_{i=1}^m E[-\frac 12log|\Psi|-\frac n2log(2\pi)-\frac 12(x^{(i)}-\mu-\Lambda z^{(i)})^T\Psi^{-1}(x^{(i)}-\mu-\Lambda z^{(i)})]
\end{aligned}
$$
我们先对上面的函数进行关于 $\Lambda$ 的最大化。可见只有最后的一项依赖 $\Lambda$。求导数,同时利用下面几个结论:$tr a = a (for\quad a \in R), tr AB = tr BA, \nabla_A tr ABA^T C = CAB + C^T AB$,就能得到:
$$
\begin{aligned}
\nabla_\Lambda&\sum_{i=1}^m -E[\frac 12(x^{(i)}-\mu-\Lambda z^{(i)})^T\Psi^{-1}(x^{(i)}-\mu-\Lambda z^{(i)})] \
&=\sum_{i=1}^m \nabla_\Lambda E[-tr\frac 12 z^{(i)T}\Lambda^T\Psi^{-1}\Lambda z^{(i)}+tr z^{(i)T}\Lambda^T\Psi^{-1}(x^{(i)}-\mu)] \
&=\sum_{i=1}^m \nabla_\Lambda E[-tr\frac 12 \Lambda^T\Psi^{-1}\Lambda z^{(i)}z^{(i)T}+tr \Lambda^T\Psi^{-1}(x^{(i)}-\mu)z^{(i)T}] \
&=\sum_{i=1}^m E[-\Psi^{-1}\Lambda z^{(i)}z^{(i)T}+\Psi^{-1}(x^{(i)}-\mu)z^{(i)T}] \
\end{aligned}
$$
设置导数为 $0$,然后简化,就能得到:
$$
\sum_{i=1}^m\Lambda E_{z^{(i)}\sim Q_i}[z^{(i)}z^{(i)T}]=
\sum_{i=1}^m(x^{(i)}-\mu)E_{z^{(i)}\sim Q_i}[z^{(i)T}]
$$
接下来,求解 $\Lambda$,就能得到:
$$
\Lambda=(\sum_{i=1}^m(x^{(i)}-\mu)E_{z^{(i)}\sim Q_i}[z^{(i)T}])(\sum_{i=1}^m E_{z^{(i)}\sim Q_i}[z^{(i)}z^{(i)T}])^{-1}\qquad(7)
$$
有一个很有意思的地方需要注意,上面这个等式和用最小二乘线性回归(least squares regression)推出的正则方程(normal equation)有密切关系:
$$
“\theta^T=(y^TX)(X^TX)^{-1}”
$$
与之类似,这里的 $x$ 是一个关于 $z$(以及噪音 noise)的线性方程。考虑在 $E$ 步骤中对 $z$ 已经给出了猜测,接下来就可以尝试来对与 $x$ 和 $z$ 相关的未知线性量(unknown linearity)$\Lambda$ 进行估计。接下来不出意料,我们就会得到某种类似正则方程的结果。然而,这个还是和利用对 $z$ 的“最佳猜测(best guesses)” 进行最小二乘算法有一个很大的区别的;这一点我们很快就会看到了。
为了完成 $M$ 步骤的更新,接下来我们要解出等式$(7)$ 当中的期望值(values of the expectations)。由于我们定义 $Q_i$ 是均值(mean)为 $\mu_{z^{(i)}|x^{(i)}}$,协方差(covariance)为 $\Sigma_{z^{(i)}|x^{(i)}}$ 的一个高斯分布,所以很容易能得到:
$$
\begin{aligned}
E_{z^{(i)}\sim Q_i}[z^{(i)T}]&= \mu_{z^{(i)}|x^{(i)}}^T \
E_{z^{(i)}\sim Q_i}[z^{(i)}z^{(i)T}]&= \mu_{z^{(i)}|x^{(i)}}\mu_{z^{(i)}|x^{(i)}}^T+\Sigma_{z^{(i)}|x^{(i)}}
\end{aligned}
$$
上面第二个等式的推导依赖于下面这个事实:对于一个随机变量 $Y$,协方差 $Cov(Y ) = E[Y Y^T ]-E[Y]E[Y]^T$ ,所以 $E[Y Y^T ] = E[Y ]E[Y ]^T +Cov(Y)$。把这个代入到等式$(7)$,就得到了 $M$ 步骤中 $\Lambda$ 的更新规则:
$$
\Lambda=(\sum_{i=1}^m(x^{(i)}-\mu)\mu_{z^{(i)}|x^{(i)}}^T)(\sum_{i=1}^m\mu_{z^{(i)}|x^{(i)}} \mu_{z^{(i)}|x^{(i)}}^T + \Sigma_{z^{(i)}|x^{(i)}})^{-1}\qquad(8)
$$
上面这个等式中,要特别注意等号右边这一侧的 $\Sigma_{z^{(i)}|x^{(i)}}$。这是一个根据 $z^{(i)}$ 给出的 $x^{(i)}$ 后验分布(posterior distribution)$p(z^{(i)}|x^{(i)})$ 的协方差,而在 $M$ 步骤中必须要考虑到在这个后验分布中 $z^{(i)}$ 的不确定性(uncertainty)。推导 $EM$ 算法的一个常见错误就是在 $E$ 步骤进行假设,只需要算出潜在随机变量(latent random variable) $z$ 的期望 $E[z]$,然后把这个值放到 $M$ 步骤当中 $z$ 出现的每个地方来进行优化(optimization)。当然,这能解决简单问题,例如高斯混合模型(mixture of Gaussians),在因子模型的推导过程中,就同时需要 $E[zz^T ]$ 和 $E[z]$;而我们已经知道,$E[zz^T ]$ 和 $E[z]E[z]T$ 随着 $\Sigma_{z|x}$ 而变化。因此,在 $M$ 步骤就必须要考虑到后验分布(posterior distribution)$p(z^{(i)}|x^{(i)})$中 $z$ 的协方差(covariance)。
最后,我们还可以发现,在 $M$ 步骤对参数 $\mu$ 和 $\Psi$ 的优化。不难发现其中的 $\mu$ 为:
$$
\mu=\frac 1m\sum_{i=1}^m x^{(i)}
$$
由于这个值不随着参数的变换而改变(也就是说,和 $\Lambda$ 的更新不同,这里等式右侧不依赖 $Q_i(z^{(i)}) = p(z^{(i)}|x^{(i)}; \mu, \Lambda, \Psi)$,这个 $Qi(z^{(i)})$ 是依赖参数的),这个只需要计算一次就可以,在算法运行过程中,也不需要进一步更新。类似地,对角矩阵 $\Psi$ 也可以通过计算下面这个式子来获得:
$$
\Phi=\frac 1m\sum_{i=1}^m x^{(i)}x^{(i)T}-x^{(i)}\mu_{z^{(i)}|x^{(i)}}^T\Lambda^T - \Lambda\mu_{z^{(i)}|x^{(i)}}x^{(i)T}+\Lambda(\mu_{z^{(i)}|x^{(i)}}\mu_{z^{(i)}|x^{(i)}}^T+\Sigma_{z^{(i)}|x^{(i)}})\Lambda^T
$$
然后只需要设 $\Psi_{ii} = \Phi_{ii}$(也就是说,设 $\Psi$ 为一个仅仅包含矩阵 $Φ$ 中对角线元素的对角矩阵)。
第十章
第十一部分 主成分分析(Principal components analysis)
前面我们讲了因子分析(factor analysis),其中在某个 $k$ 维度子空间对 $x \in R^n$ 进行近似建模,$k$ 远小于 $n$,即 $k \ll n$。具体来说,我们设想每个点 $x^{(i)}$ 用如下方法创建:首先在 $k$ 维度仿射空间(affine space) ${\Lambda z + \mu; z \in R^k}$ 中生成某个 $z^{(i)}$ ,然后增加 $Ψ$-协方差噪音(covariance noise)。因子分析(factor analysis)是基于一个概率模型(probabilistic model),然后参数估计(parameter estimation)使用了迭代期望最大化算法(iterative EM algorithm)。
在本章讲义中,我们要学习一种新的方法,主成分分析(Principal Components Analysis,缩写为 PCA),这个方法也是用来对数据近似(approximately)所处的子空间(subspace)进行判别(identify)。然而,主成分分析算法(PCA)会更加直接,只需要进行一种特征向量(eigenvector)计算(在 Matlab 里面可以通过 eig 函数轻松实现),并且不需要再去使用期望最大化(EM)算法。
假如我们有一个数据集 ${x^{(i)}; i = 1, . . ., m}$,其中包括了 $m$ 种不同汽车的属性,例如最大速度(maximum speed),转弯半径(turn radius)等等。设其中每个 $i$ 都有 $x^{(i)} \in R^n,(n \ll m)$。但对于两个不同的属性,例如 $x_i$ 和 $x_j$,对应着以英里每小时(mph)为单位的最高速度和以公里每小时(kph)为单位的最高速度。因此这两个属性应该基本是线性相关(linearly dependent)的,只在对 $mph$ 和 $kph$ 进行四舍五入时候会有引入一些微小差异。所以,这个数据实际上应该是近似处于一个 $n-1$ 维度的子空间中的。我们如何自动检测和删除掉这一冗余(redundancy)呢?
举一个不那么麻烦的例子,设想有一个数据集,其中包含的是对一个无线电遥控直升机(radio-controlled helicopters)飞行员协会进行调查得到的数据,其中的 $x_1^{(i)}$ 指代的是飞行员 $i$ 的飞行技能的度量,而 $x_2^{(i)}$ 指代的是该飞行员对飞行的喜爱程度。无线电遥控直升机是很难操作的,只有那些非常投入,并且特别热爱飞行的学生,才能成为好的飞行员。所以,上面这两个属性 $x_1$ 和 $x_2$ 之间的相关性是非常强的。所以我们可以认为在数据中沿着对角线方向(也就是下图中的 $u_1$ 方向)表征了一个人对飞行投入程度的内在“源动力(karma)”,只有少量的噪音脱离这个对角线方向。如下图所示,我们怎么来自动去计算出 $u_1$ 的方向呢?
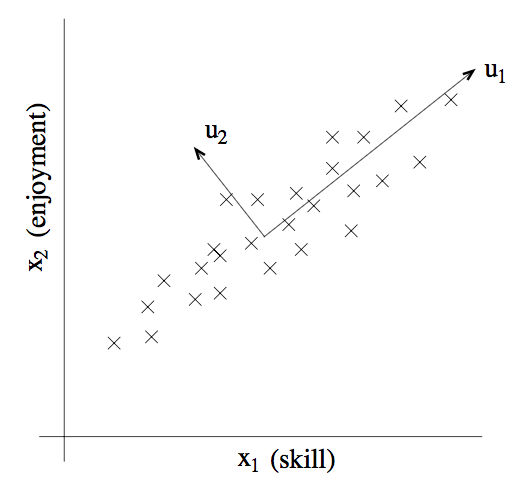
我们接下来很快就要讲到主成分分析算法(PCA algorithm)了。但在运行 PCA 之前,我们首先要进行一些预处理(pre-process),正则化(normalize)数据的均值(mean)和方差(variance),如下所示:
- 设$\mu=\frac 1m\sum_{i=1}^m x^{(i)}$
- 将每个 $x^{(i)}$ 替换成 $x^{(i)} - \mu$
- 设$\sigma_j^2=\frac 1m\sum_{i} (x_j^{(i)})^2$
- 将每个 $x_j^{(i)}$ 替换成 $x_j^{(i)}/\sigma_j$.
第$(1-2)$步把数据的平均值清零(zero out),然后可以省略掉所有有零均值的数据(例如,对应语音或者其他声学信号的时间序列)。第$(3-4)$步将每个坐标缩放,使之具有单位方差(unit variance),这确保了不同的属性(attributes)都在同样的“尺度(scale)”上来进行处理。例如,如果 $x_1$ 是汽车的最大速度(以 mph 为单位,精确到十位),然后 $x_2$ 是汽车的座位数量(取值一般在 2-4),这样这个重新正则化(renormalization)就把不同的属性(attributes)进行了缩放(scale),然后这些不同属性就更具有对比性(more comparable)。如果我们事先已经知道不同的属性在同一尺度上,就可以省略第$(3-4)$步。例如,如果每个数据点表示灰度图像(grayscale image)中的每个数据点,而每个 $x_j^{(i)}$ 就从 ${0, 1, . . . , 255}$ 中取值,对应的也就是在图像 $i$ 中像素 $j$ 位置的灰度值(intensity value)。
接下来,进行了正则化之后,对数据近似所处的方向,也就是“主要变异轴(major axis of variation)”$u$,该如何去计算呢?一种方法是找出一个单位向量(unit vector)$u$,使得数据投影在 $u$ 的方向上的时候,投影的数据的方差(variance)最大。直观来看,在这个方向上,数据开始有一定规模的方差(variance)/信息量(information)。我们要选择的是这样一个方向的单位向量 $u$:数据能近似投放到与单位向量 $u$ 一致的方向(direction)/子空间(subspace),并且尽可能多地保留上面的方差(variance)。
设下面的数据集,我们已经进行了正则化步骤(normalization steps):
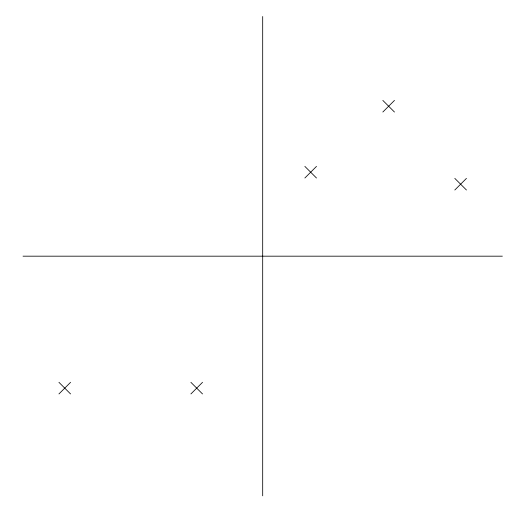
现在,加入我们选择的单位向量 $u$ 对应了下图中所示的方向。下图中的圆点表示的就是原始数据在这条线上面的投影(projections)。
可以看到,上面投影得到的数据依然有还算比较大的方差,而这些点距离零点也都比较远。反面样本则如下图所示,我们选择了另外一个方向的单位向量:
上面这幅图的投影中的方差就明显小了很多,而且投影得到的点位置也距离原点更近很多。
我们希望能自动地选择出来如上面两幅图中第一幅那样的方向的单位向量 $u$。要对这个过程进行方程化(formalize),要注意到给定一个向量 $u$ 和一个点 $x$,$x$ 投影到 $u$ 上的投影长度就可以用 $x^T u$ 来得到。也就是说,如果 $x^{(i)}$ 是我们数据集中的一个点(上面几个图中画叉的 $x$ 点中的一个),那么这个点在 $u$ 上的投影(对应的是图中的圆点)就是从原点到 $x^T u$ 的距离。因此,要最大化投影的方差,就要找到一个能够将下面式子最大化的单位长度向量 $u$:
$$
\begin{aligned}
\frac 1m\sum_{i=1}^m (x^{(i)T}u)^2 &= \frac 1m\sum_{i=1}^m u^Tx^{(i)}x^{(i)T}u \
&= u^T(\frac 1m\sum_{i=1}^m x^{(i)}x^{(i)T})u
\end{aligned}
$$
很容易就能发现,要让上面的式子最大化,$||u||_2 = 1$ 给出了 的主特征向量(principal eigenvector),而这也正好就是数据的经验协方差矩阵(假设有零均值)。$^1$
1 如果以前没见到过这种形式,可以用拉格朗日乘数法将 $u^T \Sigma u$ 最大化,使得 $u^T u = 1$。你应该能发现对于某些 $\lambda,\Sigma u = \lambda u$,这就意味着向量 $u$ 是 $\Sigma$ 的特征向量(eigenvector),特征值(eigenvalue)为 $\lambda$。
总结一下,如果我们要找一个 1维度子控件来近似数据,就要选择 $\Sigma$ 的主特征向量(principal eigenvector)作为单位向量 $u$。更广义地理解,就是如果要讲数据投影到一个 $k$ 维度子空间($k < n$),就应当选择 $\Sigma$ 的 $k$ 个特征向量(eigenvectors) 来作为单位向量 $u_1, . . ., u_k$。这里的 $u_i$ 就形成了数据的一组新的正交基(orthogonal basis)。$^2$
2 由于 $\Sigma$ 是对称的,所以向量 $u_i$ 就总是(或者总能选出来)彼此正交的(orthogonal)
然后,要使用这组正交基来表示 $x^{(i)}$,只需要计算对应的向量:
$$
y^{(i)}=\begin{bmatrix}
u_1^T x^{(i)}\ u_2^T x^{(i)}\ \vdots\ u_k^T x^{(i)}
\end{bmatrix} \in R^k
$$
因此,$x^{(i)} \in R^n$,向量 $y^{(i)}$就是对 $x^{(i)}$ 的近似/表示。因此,主成分分析算法(PCA)也被称为是一种维度降低 算法(dimensionality reduction algorithm)。而其中的单位向量 $u_1,…,u_k$ 也就叫做数据集的前 $k$ 个主成分(principal components)。
备注。 虽然我们已经正式表述了,仅当 $k = 1$ 的情况下,使用特征向量(eigenvectors)的众所周知的特性,很明显,在所有可能的正交基(orthogonal bases)当中,我们选择的那一组就能使得取最大值。因此,我们对基向量(basis)的选择应当是尽可能保留原始数据的方差信息(variability)。
在习题集 $4$ 中,你会发现主成分分析算法(PCA)也可以有另外一种推导方式:将数据投影到数据所张成的 $k$ 维度子空间中,选择一组基向量,使得投影引起的近似误差(approximation error)最小。
主成分分析算法(PCA)有很多用法;我们接下来收尾这部分就来给出若干样例。首先是压缩—用更低维度的 $y^{(i)}$ 来表示 $x^{(i)}$ ,这很明显就是一种用途了。如果我们把高维度的数据降维到 $k = 2$ 或者 $3$,那么就可以将 $y^{(i)}$ 进行可视化了。例如,如果我们把汽车数据降维到 $2$ 维,那么就可以把压缩后的数据投图(例如这时候投图中的一二点可能就代表了骑车的类型),来看看哪些车彼此相似,以及这些车可以聚集成那些组。
另一个常用应用就是在使用 $x^{(i)}$ 作为输入特征进行监督学习算法(supervised learning algorithm)之前降低数据维度的预处理步骤。除了有利于缓解计算性能压力之外,降低数据维度还可以降低假设类(hypothesis class)的复杂度(complexity),然后避免过拟合(overfitting)(例如,低维度的输入特征控件上的线性分类器(linear classifiers)会有更小的 $VC$ 维度)。
最后,正如在遥控直升机飞行员那个样例,我们可以把 PCA 用作为一种降噪算法(noise reduction algorithm)。在那个例子中,算法从对遥控飞行技巧和热爱程度的有噪音的衡量中估计了直观的“遥控飞行原动力(piloting karma)”。在课程中,我们还看到了把这种思路用于人脸图像,得到的就是面部特征算法(eigenface method)。其中每个点 $x^{(i)} \in R^{100×100}$ 都是一个 10000 维度的向量,每个坐标对应的是一个 100x100 的人脸图像中的一个像素灰度值。使用主特征分析算法(PCA),我们就可以用更低维度的 $y^{(i)}$ 来表示每个图像 $x^{(i)}$。在这个过程中,我们希望主成分(principal components)能够保存有趣的信息、面孔之间的系统变化(systematic variations),以便能捕获到一个人看上去的模样,而不是由于细微的光线变化、轻微的拍摄状况差别等而引起的图像中的“噪音(noise)”。然后我们通过降低纬度然后计算 $||y^{(i)} - y^{(j)}||_2$ 来测量面孔 $i$ 和 $j$ 之间的距离。这样就能得到一个令人惊艳的面部匹配和检索算法(face-matching and retrieval algorithm)。
第十一章
第十二部分 独立成分分析(Independent Components Analysis )
接下来我们要讲的主体是独立成分分析(Independent Components Analysis,缩写为 ICA)。这个方法和主成分分析(PCA)类似,也是要找到一组新的基向量(basis)来表征(represent)样本数据。然而,这两个方法的目的是非常不同的。
还是先用“鸡尾酒会问题(cocktail party problem)”为例。在一个聚会场合中,有 $n$ 个人同时说话,而屋子里的任意一个话筒录制到底都只是叠加在一起的这 $n$ 个人的声音。但如果假设我们也有 $n$ 个不同的话筒安装在屋子里,并且这些话筒与每个说话人的距离都各自不同,那么录下来的也就是不同的组合形式的所有人的声音叠加。使用这样布置的 $n$ 个话筒来录音,能不能区分开原始的 $n$ 个说话者每个人的声音信号呢?
把这个问题用方程的形式来表示,我们需要先假设有某个样本数据 $s \in R^n$,这个数据是由 $n$ 个独立的来源(independent sources)生成的。我们观察到的则为:
$$x = As,$$
上面式子中的 $A$ 是一个未知的正方形矩阵(square matrix),叫做混合矩阵(mixing matrix)。 通过重复的观察,我们就得到了训练集 ${x^{(i)} ; i = 1, . . . , m}$,然后我们的目的是恢复出生成这些样本 $x^{(i)} = As^{(i)}$ 的原始声音源 $s^{(i)}$ 。
在咱们的“鸡尾酒会问题”中,$s^{(i)}$ 就是一个 $n$ 维度向量,而 $s_j^{(i)}$ 是第 $j$ 个说话者在第 $i$ 次录音时候发出的声音。$x^{(i)}$ 同样也是一个 $n$ 维度向量,而 $x_j^{(i)}$是第 $j$ 个话筒在第 $i$ 次录制到的声音。
设混合矩阵 $A$ 的逆矩阵 $W = A^{-1}$ 是混合的逆向过程,称之为还原矩阵(unmixing matrix)。 那么咱们的目标就是找出这个 $W$,这样针对给定的话筒录音 $x^{(i)}$,我们就可以通过计算 $s^{(i)} = Wx^{(i)}$ 来还原出来声音源。为了方便起见,我们就用 $w_i^T$ 来表示 $W$ 的第 $i$ 行,这样就有:
$$
w=\begin{bmatrix}
-w_1^T- \
\vdots \
-w_n^T-
\end{bmatrix}
$$
这样就有 $w_i \in R^n$,通过计算 $s_j^{(i)} = w_j^T x^{(i)}$ 就可以恢复出第 $j$ 个声源了。
1 独立成分分析(ICA)的模糊性(ambiguities)
$W = A^{-1}$ 能恢复到怎样的程度呢?如果我们对声源和混合矩阵都有预先的了解(prior knowledge),那就不难看出,混合矩阵 $A$ 当中存在的某些固有的模糊性,仅仅给定了 $x^{(i)}$ 可能无法恢复出来。
例如,设 $p$ 是一个 $n×n$ 的置换矩阵(permutation matrix)。这就意味着矩阵 $P$ 的每一行和每一列都只有一个 $1$。下面就是几个置换矩阵的样例:
$$
P=\begin{bmatrix}
0&1&0 \
1&0&0 \
0&0&1
\end{bmatrix};\quad
P=\begin{bmatrix}
0&1 \
1&0
\end{bmatrix};\quad
P=\begin{bmatrix}
1&0 \
0&1
\end{bmatrix}
$$
如果 $z$ 是一个向量,那么 $Pz$ 就是另外一个向量,这个向量包含了 $z$ 坐标的置换版本(permuted version)。如果只给出 $x^{(i)}$,是没有办法区分出 $W$ 和 $PW$ 的。具体来说,原始声源的排列(permutation)是模糊的(ambiguous),这一点也不奇怪。好在大多数情况下,这个问题都并不重要。
进一步来说,就是没有什么办法能恢复出 $w_i$ 的正确的缩放规模。例如,如果把$A$ 替换成了 $2A$,那么每个 $s^{(i)}$ 都替换成了 $(0.5)s^{(i)}$,那么观测到的 $x^{(i)} = 2A · (0.5)s^{(i)}$ 还是跟原来一样的。再进一步说,如果 $A$ 当中的某一列,都用一个参数 $\alpha$ 来进行缩放,那么对应的音源就被缩放到了 $1/\alpha$,这也表明,仅仅给出 $x^{(i)}$,是没办法判断这种情况是否发生的。因此,我们并不能还原出音源的“正确”缩放规模。然而,在我们应用的场景中,例如本文提到的这个“鸡尾酒会问题”中,这种不确定性并没有关系。具体来说,对于一个说话者的声音信号 $s^{(i)}$ 的缩放参数 $\alpha$ 只影响说话者声音的大小而已。另外,符号变换也没有影响,因为$s_j^{(i)}$ 和 $-s_j^{(i)}$ 都表示了扬声器中同样的声音大小。所以,如果算法找到的 $w_i$ 被乘以任意一个非零数进行了缩放,那么对应的恢复出来的音源 $s_i = w_i^T x$ 也进行了同样的缩放;这通常都不要紧。(这些考量也适用于课堂上讨论的对 Brain/MEG 数据使用的 ICA 算法。)
上面这些是 ICA 算法模糊性的唯一来源么?还真是这样,只要声源 $s_i$ 是非高斯分布(non-Gaussian)的即可。如果是高斯分布的数据(Gaussian data),例如一个样本中,$n = 2$,而 $s\sim N(0,I)$ 。(译者注:即 $s$ 是一个以 $0$ 和 $I$ 为参数的正态分布,正态分布属于高斯分布) 其中的 $I$ 是一个 $2×2$ 的单位矩阵(identity matrix)。要注意,这是一个标准正态分布,其密度(density)轮廓图(contour)是以圆点为中心的圆,其密度是旋转对称的(rotationally symmetric)。
接下来,假如我们观测到了某个 $x = As$,其中的$A$ 就是混合矩阵(mixing matrix)。这样得到的 $x$ 也是一个高斯分布的,均值为 $0$,协方差 $E[xx^T ] = E[Ass^T A^T ] = AA^T$。 然后设 $R$ 为任意的正交矩阵(不太正式地说,也可以说成是旋转(rotation)矩阵或者是反射(reflection)矩阵),这样则有 $RR^T = R^TR = I$,然后设 $A’ = AR$。如果使用 $A’$ 而不是 $A$ 作为混合矩阵,那么观测到的数据就应该是 $x’ = A’s$。这个 $x’$ 也还是个高斯分布,依然是均值为 $0$,协方差为 $E[x’(x’)^T ] = E[A’ss^T (A’)^T ] = E[ARss^T (AR)^T ] = ARR^T A^T = AA^T$。看到没,无论混合矩阵使用 $A$ 还是 $A’$ ,得到的数据都是一个正态分布 $N (0, AA^T )$(以 0 为均值,协方差为 $AA^T$) 。这样就根本不能区分出来混合矩阵使用的是 $A$ 还是 $A’$。所以,只要混合矩阵中有一个任意的旋转分量(arbitrary rotational component),并且不能从数据中获得,那么就不能恢复出原始数据源了。
上面这些论证,是基于多元标准正态分布(multivariate standard normal distribution)是旋转对称(rotationally symmetric)的这个定理。这些情况使得 ICA 面对高斯分布的数据(Gaussian data)的时候很无力,但是只要数据不是高斯分布的,然后再有充足的数据,那就还是能恢复出 $n$ 个独立的声源的。
2 密度(Densities)和线性变换(linear transformations)
在继续去推导 ICA 算法之前,我们先来简要讲一讲对密度函数进行线性变换的效果(effect)。
加入我们有某个随机变量 $s$,可以根据某个密度函数 $p_s(s)$ 来绘制。简单起见,咱们现在就把 $s$ 当做是一个实数,即 $s \in R$。然后设 $x$ 为某个随机变量,定义方式为 $x = As$ (其中 $x \in R, A \in R$)。然后设 $p_x$ 是 $x$ 的密度函数。那么这个 $p_x$ 是多少呢?
设 $W = A^{-1}$。要计算 $x$ 取某一个特定值的“概率(probability)”,可以先计算对于 $s = Wx$,在这一点上的 $p_s$,然后推导出$“p_x(x) = p_s(Wx)”$。然而,这是错误的。例如,假设 $s\sim Uniform[0, 1]$,即其密度函数 $p_s(s) = 1{0 ≤ s ≤ 1}$。然后设 $A = 2$,这样 $x = 2s$。很明显, $x$ 在 $[0,2]$ 这个区间均匀分布(distributed uniformly)。所以其密度函数也就是 $p_x(x) = (0.5)1{0 ≤ x ≤ 2}$。这并不等于 $p_s(W x)$,其中的 $W = 0.5 = A^{-1}$。所以正确的推导公式应该是 $p_x(x) = p_s(Wx)|W|$。
推广一下,若 $s$ 是一个向量值的分布,密度函数为 $p_s$,而 $x = As$,其中的 $A$ 是一个可逆的正方形矩阵,那么 $x$ 的密度函数则为:
$$
p_x(x) = p_s(Wx) · |W|
$$
上式中 $W = A^{-1}$。
Remark. If you’ve seen the result that A maps [0, 1]n to a set of volume |A|, then here’s another way to remember the formula for px given above, that also generalizes our previous 1-dimensional example.
备注。 可能你已经看到了用 $A$ 映射 $[0, 1]^n$ 得到的就是一个由 $volume |A|$ 组成的集合(译者注:这里的 volume 我不确定该怎么翻译),然后就又有了一个办法可以记住上面给出的关于 $p_x$的公式了,这也是对之前讨论过的 $1$ 维样例的一个泛化扩展。具体来说,设给定了 $A \in R^{n×n}$,然后还按照惯例设 $W = A^{-1}$。接着设 $C_1 = [0, 1]^n$ 是一个 $n$ 维度超立方体,然后设 $C_2 ={As:s\in C1}\subseteq R^n$ 为由 $A$ 给定的映射下的 $C_1$ 的投影图像。这就是线性代数里面,用 $|A|$ 来表示 $C_2$ 的体积的标准结果,另外也是定义行列式(determinants)的一种方式。接下来,设 $s$在 $[0, 1]^n$ 上均匀分布(uniformly distributed),这样其密度函数为 $p_s(s) = 1{s \in C_1}$。然后很明显,$x$ 也是在 $C_2$ 内均匀分布(uniformly distributed)。因此可以知道其密度函数为 $p_x(x) = 1{x \in C_2}/vol(C_2)$,必须在整个 $C_2$ 累积为$1$(integrate to $1$,这是概率的性质)。但利用逆矩阵的行列式等于行列式的倒数这个定理,就有了 $1/vol(C_2) = 1/|A| = |A^{-1}| = |W|$。所以则有 $p_x(x) = 1{x \in C_2}|W| = 1{Wx \in C_1}|W | = p_s(W x)|W |$。
3 独立成分分析算法(ICA algorithm)
现在就可以推导 ICA 算法了。我们这里描述的算法来自于 Bell 和 Sejnowski,然后我们对算法的解释也是基于他们的算法,作为一种最大似然估计(maximum likelihood estimation)的方法。(这和他们最初的解释不一样,那个解释里面要涉及到一个叫做最大信息原则(infomax principal) 的复杂概念,考虑到对 ICA 的现代理解,推导过程已经不需要那么复杂了。)
我们假设每个声源的分布 $s_i$ 都是通过密度函数 $p_s$ 给出,然后联合分布 $s$ 则为:
$$
p(s)=\prod_{i=1}^n p_s(s_i)
$$
这里要注意,通过在建模中将联合分布(joint distribution)拆解为边界分布(marginal)的乘积(product),就能得出每个声源都是独立的假设(assumption)。利用上一节推导的共识,这就表明对 $x = As = W^{-1}s$ 的密度函数为:
$$
p(x)=\prod_{i=1}^n p_s(w_i^T x)\cdot |w|
$$
剩下的就只需要去确定每个独立的声源的密度函数 $p_s$ 了。
回忆一下,给定某个实数值的随机变量 $z$,其累积分布函数(cumulative distribution function,cdf)$F$ 的定义为$F(z_0)=P(z\le z_0)=\int_{-\infty}^{z_0}p_z(z)dz$。然后,对这个累积分布函数求导数,就能得到 z 的密度函数:$p_z(z) = F’(z)$。
因此,要确定 $s_i$ 的密度函数,首先要做的就是确定其累积分布函数(cdf)。这个 $cdf$ 函数必然是一个从 $0$ 到 $1$ 的单调递增函数。根据我们之前的讨论,这里不能选用高斯分布的 $cdf$,因为 ICA 不适用于高斯分布的数据。所以这里我们选择一个能够保证从 $0$ 增长到 $1$ 的合理的“默认(default)” 函数就可以了,比如 $s$ 形函数(sigmoid function) $g(s) = 1/(1 + e^{-s})$。这样就有,$p_s(s) = g’(s)$。$^1$
1 如果你对声源的密度函数的形式有了事先的了解,那么在这个位置替换过来就是个很好的办法。不过如果没有这种了解,就可以用 $s$ 形函数(sigmoid function),可以把这个函数当做是一个比较合理的默认函数,在很多问题中,这个函数用起来效果都不错。另外这里讲述的是假设要么所有的数据 $x^{(i)}$ 已经被证明均值为 $0$,或者可以自然预期具有 $0$ 均值,比如声音信号就是如此。这很有必要,因为我们的假设 $p_s(s) = g’(s)$ 就意味着期望 $E[s] = 0$(这个逻辑函数(logistic function)的导数是一个对称函数,因此给出的就是均值为 $0$ 的随机变量对应的密度函数),这也意味着 $E[x] = E[As] = 0$。
$W$ 是一个正方形矩阵,是模型中的参数。给定一个训练集合 ${x^{(i)};i = 1,…,m}$,然后对数似然函数(log likelihood)则为:
$$
l(W)=\sum_{i=1}^m(\sum_{j=1}^n log g’(w_j^Tx^{(i)})+log|W|))
$$
我们要做的就是上面这个函数找出关于 $W$ 的最大值。通过求导,然后利用前面讲义中给出的定理 $\nabla_W|W| = |W|(W^{-1})^T$,就可以很容易推导出随机梯度上升(stochastic gradient ascent)学习规则(learning rule)。对于一个给定的训练样本 $x^{(i)}$,这个更新规则为:
$$
W:=W+\alpha\begin{pmatrix}
\begin{bmatrix}
1-2g(w_1^T x^{(i)}) \
1-2g(w_2^T x^{(i)}) \
\vdots \
1-2g(w_n^T x^{(i)})
\end{bmatrix}x^{(i)T} + (W^T)^{-1}
\end{pmatrix}
$$
上式中的 $\alpha$ 是学习速率(learning rate)。
在算法收敛(converges)之后,就能计算出 $s^{(i)} = Wx^{(i)}$,这样就能恢复出原始的音源了。
备注。 在写下数据的似然函数的时候,我们隐含地假设了这些 $x^{(i)}$ 都是彼此独立的(这里指的是对于不同的 $i$ 值来说彼此独立;注意这个问题并不是说 $x^{(i)}$ 的不同坐标是独立的),这样对训练集的似然函数则为$\prod_i p(x^{(i)};W)$。很显然,对于语音数据和其他 $x^{(i)}$ 有相关性的时间序列数据来说,这个假设是不对的,但是这可以用来表明,只要有充足的数据,那么有相关性的训练样本并不会影响算法的性能。但是,对于成功训练的样本具有相关性的问题,如果我们把训练样本当做一个随机序列来进行访问,使用随机梯度上升(stochastic gradient ascent)的时候,有时候也能帮助加速收敛。(也就是说,在训练集的一个随机打乱的副本中运行随机梯度上升。)
第十二章
第十三部分 强化学习(Reinforcement Learning)和控制(Control)
这一章我们就要学习强化学习(reinforcement learning)和适应性控制(adaptive control)了。
在监督学习(supervised learning)中,我们已经见过的一些算法,输出的标签类 $y$ 都是在训练集中已经存在的。这种情况下,对于每个输入特征 $x$,都有一个对应的标签作为明确的“正确答案(right answer)”。与之相反,在很多的连续判断(sequential decisions making)和控制(control)的问题中,很难提供这样的明确的显示监督(explicit supervision)给学习算法。例如,假设咱们制作了一个四条腿的机器人,然后要编程让它能走路,而我们并不知道怎么去采取“正确”的动作来进行四条腿的行走,所以就不能给他提供一个明确的监督学习算法来进行模仿。
在强化学习(reinforcement learning)的框架下,我们就并不提供监督学习中那种具体的动作方法,而是只给出一个奖励函数(reward function),这个函数会告知学习程序(learning agent) 什么时候的动作是好的,什么时候的是不好的。在四腿机器人这个样例中,奖励函数会在机器人有进步的时候给出正面回馈,即奖励,而有退步或者摔倒的时候给出负面回馈,可以理解成惩罚。接下来随着时间的推移,学习算法就会解决如何选择正确动作以得到最大奖励。
强化学习(Reinforcement learning,下文中缩写为 RL)已经成功用于多种场景了,例如无人直升机的自主飞行,机器人用腿来运动,手机的网络选择,市场营销策略筛选,工厂控制,高效率的网页索引等等。我们对强化学习的探索,要先从马尔可夫决策过程(Markov decision processes,缩写为 MDP) 开始,这个概念给出了强化学习问题的常见形式。
1 马尔可夫决策过程(Markov decision processes)
一个马尔可夫决策过程(Markov decision process)由一个元组(tuple) $(S, A, {P_{sa}}, \gamma, R)$组成,其中元素分别为:
- $S$ 是一个状态集合(a set of states)。(例如,在无人直升机飞行的案例中,$S$ 就可以是直升机所有的位置和方向的集合。)
- $A$ 是一个动作集合(a set of actions)。(例如,还以无人直升机为例,$A$ 就可以是遥控器上面能够操作的所有动作方向。)
- $P_{sa}$ 为状态转移概率(state transition probabilities)。对于每个状态 $s \in S$ 和动作 $a \in A$, $P_{sa}$ 是在状态空间上的一个分布(a distribution over the state space)。后面会再详细讲解,不过简单来说, $P_{sa}$ 给出的是在状态 $s$ 下进行一个动作 $a$ 而要转移到的状态的分布。
- $\gamma \in [0, 1)$ 叫做折扣因子(discount factor)。
- $R : S × A → R$ 就是奖励函数(reward function)。(奖励函数也可以写成仅对状态 $S$ 的函数,这样就可以写成 $R : S → R$。)
马尔可夫决策过程(MDP)的动力学(dynamics)过程如下所示:于某个起始状态 $s_0$ 启动,然后选择某个动作 $a_0 \in A$ 来执行 MDP 过程。根据所选的动作会有对应的结果,MDP 的状态则转移到某个后继状态(successor state),表示为 $s_1$,根据 $s_1 \sim P_{s_0a_0}$ 得到。然后再选择另外一个动作 $a_1$,接下来又有对应这个动作的状态转移,状态则为 $s_2 \sim P_{s_1a_1}$。接下来再选择一个动作 $a_2$,就这样进行下去。如果将这个过程绘制出来的话,结果如下所示:
$$
s_0\xrightarrow{a_0}s_1\xrightarrow{a_1}s_2\xrightarrow{a_2}s_3\xrightarrow{a_3}\dots
$$
通过序列中的所有状态 $s_0, s_1, \dots$ 和对应的动作 $a_0, a_1,\dots$,你就能得到总奖励值,即总收益函数(total payoff)为
$$
R(s_0,a_0) + \gamma R(s_1,a_1) + \gamma^2 R(s_2,a_2) + \dots
$$
如果把奖励函数作为仅与状态相关的函数,那么这个值就简化成了
$$
R(s_0) + \gamma R(s_1) + \gamma^2 R(s_2) + \dots
$$
多数情况下,我们都用后面这种仅为状态的函数$R(s)$这种形式,虽然扩展到对应状态-动作两个变量的函数 $R(s,a)$ 也并不难。
强化学习的目标就是找到的一组动作,能使得总收益函数(total payoff)的期望值最大:
$$
E[R(s_0) + \gamma R(s_1) + \gamma^2 R(s_2) + \dots]
$$
注意,在时间步长(timestep) $t$ 上的奖励函数(reward)通过一个参数(factor)$\gamma^t$ 而进行了缩减(discounted)。 因此,要使得期望最大化,就需要尽可能早积累符号为正的奖励(positive rewards),而尽量推迟负面奖励(negative rewards,即惩罚)的出现。在经济方面的应用中,其中的 $R(·)$ 就是盈利金额(amount of money made),$\gamma$ 也可以理解为利润率(interest rate)的表征,这样有自然的解释(natural interpretation),例如今天的一美元就比明天的一美元有更多价值。
有一种策略(policy), 是使用任意函数 $\pi : S → A$,从状态(states)到动作(actions)进行映射(mapping)。如果在状态 $s$,采取动作 $a = \pi(s)$,就可以说正在执行(executing) 某种策略(policy) $\pi$。然后还可以针对策略函数(policy)$\pi$ 来定义一个值函数(value function):
$$
V^\pi(s)=E[R(s_0) + \gamma R(s_1) + \gamma^2 R(s_2) + \dots | s_0=s,\pi]
$$
$V^\pi(s)$ 就是从状态 $s$ 开始,根据 $\pi^1$ 给出的动作来积累的部分奖励函数(discounted rewards)的期望总和(expected sum)。
1 实际上这里我们用 $\pi$ 这个记号来表示,严格来说不太正确,因为 $\pi$ 并不是一个随机变量,不过在文献里面这样表示很多,已经成了某种事实上的标准了。
给定一个固定的策略函数(policy) $\pi$,则对应的值函数 $V^\pi$ 满足贝尔曼等式(Bellman equations):
$$
V^\pi(s)=R(s)+\gamma \sum_{s’\in S}P_{s\pi(s)}(s’)V^\pi(s’)
$$
这也就意味着,从状态 $s$ 开始的这个部分奖励(discounted rewards)的期望总和(expected sum) $V^\pi(s)$ 由两部分组成:首先是在状态 $s$ 时候当时立即获得的奖励函数值 $R(s)$,也就是上面式子的第一项;另一个就是第二项,即后续的部分奖励函数值(discounted rewards)的期望总和(expected sum)。对第二项进行更深入的探索,就能发现这个求和项(summation term)可以写成 $E_{s’\sim P_{s\pi(s)}} [V^\pi(s’)]$ 的形式。这种形式也就是从状态 $s’$ 开始的这个部分奖励(discounted rewards)的期望总和(expected sum) $V^\pi(s’)$,此处的 $s’$ 是根据 $P_{s\pi(s)}$ 分布的,在 MDP 过程中从状态 $s$ 采取第一个动作 $\pi(s)$ 之后,确定了这个分布所在的空间。因此,上面的第二项实际上也就是给出了在 MDP 过程中第一步之后的部分奖励(discounted rewards)的期望总和(expected sum)。
贝尔曼等式(Bellman’s equations)可以有效地解出 $V^\pi$。尤其是在一个有限状态的 MDP 过程中,即 $(|S| < \infty)$,我们可以把每个状态 $s$ 对应的 $V^\pi (s)$ 的方程写出来。这样就得到了一系列的 $|S |$ 个线性方程,有 $|S |$ 个变量(也就是对应每个状态的未知的 $V^\pi(s)$ ),这些 $V^\pi(s)$ 都很容易解出来。
然后可以定义出最优值函数(optimal value function)
$$
V^*(s)=\max_\pi V^\pi(s)\qquad(1)
$$
换一种说法,这个值也就是能用任意一种策略函数(policy)来获得的,最佳的可能部分奖励(discounted rewards)的期望总和(expected sum)。另外对于最优值函数(optimal value function),也有一个版本的贝尔曼等式(Bellman’s equations):
$$
V^*(s)=R(s)+\max_{a\in A}\gamma\sum_{s’\in S}P_{sa}(s’)V^*(s’)\qquad(2)
$$
上面这个等式中的第一项,还是跟之前一样的,还是即时奖励函数值。第二项是在采取了动作 $a$ 之后的所有动作 $a$ 的部分奖励(discounted rewards)的未来期望总和(expected future sum)的最大值。要确保理解这个等式,并且要明白为什么这个等式有意义。译者注:抱歉,这里的这个 discounted rewards 弄得我不知道怎么翻译才顺,意思表达得很狗,非常抱歉。
另外还定义了一个策略函数(policy) $\pi^* : S → A$,如下所示
$$
\pi^*(s)=arg\max_{a\in A}\sum_{s’\in S}P_{sa}(s’)V^*(s’)\qquad(3)
$$
注意,这里的 $\pi^*(s)$ 给出的动作 $a$ 实现了上面等式$(2)$当中能够使 “max” 项取到最大值。
事实上,对于每个状态 $s$ 和每个策略函数(policy)$\pi$,我们都可以得出:
$$
V^*(s)=V^{\pi^*}(s)\ge V^\pi(s)
$$
上面的第一个等式关系表明,在任何状态 $s$ 下,对应策略函数(policy) $V^{\pi^*}$的值函数(value function)$\pi^*$ 等于最优值函数 $V^*$。右边的不等式则表明,$\pi^*$ 的值至少也等于任意其他策略函数的值。也就是说,上面在等式$(3)$当中定义的这个 $\pi^*$ 就是最佳策略函数(optimal policy)。
注意,这个 $\pi^*$ 有一个有趣的特性,它是所有状态 $s$ 下的最佳策略。具体来讲,并不是说只是从某些状态 $s$ 开始的MDP过程才使得这个$\pi^*$是对应这些状态的最佳策略,而如果从某些别的状态 $s’$ 开始就有其他的最佳策略。而是对于所有的状态 $s$,都是同样的一个策略函数 $\pi^*$ 能够使得等式$(1)$中的项目取得最大值。这也就意味着无论 MDP 过程的初始状态(initial state)如何,都可以使用同样的策略函数 $\pi^*$。
2 值迭代(Value iteration)和策略迭代(policy iteration)
现在我们要讲两种算法,都能很有效地解决有限状态的马尔可夫决策过程问题(finite-state MDPs)。目前为止,我们只考虑有限状态和动作空间的马尔可夫决策过程,也就是状态和动作的个数都是有限的,即$|S| < \infty, |A| < \infty$。
第一种算法,值迭代(value iteration), 过程如下所述:
- 对每个状态 $s$, 初始化 $V (s) := 0$.
- 重复直到收敛 {
  对每个状态,更新规则$V(s):=R(s)+\max_{a\in A}\gamma\sum_{s’}P_{sa}(s’)V(s’)$
}
这个算法可以理解成,利用贝尔曼等式(Bellman Equations)$(2)$重复更新估计值函数(estimated value function)。
在上面的算法的内部循环体中,有两种进行更新的方法。首先,我们可以为每一个状态 $s$ 计算新的值 $V(s)$,然后用新的值覆盖掉所有的旧值。这也叫做同步更新(synchronous update)。 在这种情况下,此算法可以看做是实现(implementing)了一个“贝尔曼备份运算符(Bellman backup operator)”,这个运算符接收值函数(value function)的当前估计(current estimate),然后映射到一个新的估计值(estimate)。(更多细节参考作业题目中的内容。)另外一种方法,即我们可以使用异步更新(asynchronous updates)。 使用这种方法,就可以按照某种次序来遍历(loop over)所有的状态,然后每次更新其中一个的值。
无论是同步还是异步的更新,都能发现最终值迭代(value iteration)会使 $V$ 收敛到 $V^*$ 。找到了 $V^*$ 之后,就可以利用等式$(3)$来找到最佳策略(optimal policy)。
除了值迭代(value iteration)之外,还有另外一种标准算法可以用来在马尔可夫决策过程(MDP)中寻找一个最佳策略(optimal policy)。这个策略迭代(policy iteration) 算法如下所述:
- 随机初始化 $\pi$。
- 重复直到收敛{
  $(a)$ 令 $V := V^\pi$.
  $(b)$ 对每个状态 $s$,令 $\pi(s):=arg\max_{a\in A}\sum_{s’}P_{sa}(s’)V(s’)$
}
因此,在循环体内部就重复计算对于当前策略(current policy)的值函数(value function),然后使用当前的值函数(value function)来更新策略函数(policy)。(在步骤 $(b)$ 中找到的策略 $\pi$ 也被称为对应 $V$ 的贪心策略(greedy with respect to V) )注意,步骤 $(a)$ 可以通过解贝尔曼等式(Bellman’s equation)来实现,之前已经说过了,在固定策略(fixed policy)的情况下,这个等式只是一系列有 $|S|$ 个变量(variables)的 $|S|$ 个线性方程(linear equations)。
在上面的算法迭代了某个最大迭代次数之后,$V$ 将会收敛到 $V^*$,而 $\pi$ 会收敛到 $\pi^*$。
值迭代(value iteration)和策略迭代(policy iteration)都是解决马尔可夫决策过程(MDPs)问题的标准算法, 而且目前对于这两个算法哪个更好,还没有一个统一的一致意见。对小规模的 MDPs 来说,策略迭代(policy iteration)通常非常快,迭代很少的次数就能瘦脸。然而,对有大规模状态空间的 MDPs,确切求解 $V^\pi$就要涉及到求解一个非常大的线性方程组系统,可能非常困难。对于这种问题,就可以更倾向于选择值迭代(value iteration)。因此,在实际使用中,值迭代(value iteration)通常比策略迭代(policy iteration)更加常用。
3 学习一个马尔可夫决策过程模型(Learning a model for an MDP)
目前为止,我们已经讲了 MDPs,以及用于 MDPs 的一些算法,这都是基于一个假设,即状态转移概率(state transition probabilities)以及奖励函数(rewards)都是已知的。在很多现实问题中,却未必知道这两样,而是必须从数据中对其进行估计。(通常 $S,A 和 \gamma$ 都是知道的。)
例如,加入对倒立摆问题(inverted pendulum problem,参考习题集 $4$),在 MDP 中进行了一系列的试验,过程如下所示:
$$
\begin{aligned}
&s_0^{(1)}\xrightarrow{a_0^{(1)}}s_1^{(1)}\xrightarrow{a_1^{(1)}}s_2^{(1)}\xrightarrow{a_2^{(1)}}s_3^{(1)}\xrightarrow{a_3^{(1)}}\dots \
&s_0^{(2)}\xrightarrow{a_0^{(2)}}s_1^{(2)}\xrightarrow{a_1^{(2)}}s_2^{(2)}\xrightarrow{a_2^{(2)}}s_3^{(2)}\xrightarrow{a_3^{(2)}}\dots \
&\cdots
\end{aligned}
$$
其中 $s_i^{(j)}$ 表示的是第 $j$ 次试验中第 $i$ 次的状态,而 $a_i^{(j)}$ 是该状态下的对应动作。在实践中,每个试验都会运行到 MDP 过程停止(例如在倒立摆问题(inverted pendulum problem)中杆落下(pole falls)),或者会运行到某个很大但有限的一个数的时间步长(timesteps)。
有了在 MDP 中一系列试验得到的“经验”,就可以对状态转移概率(state transition probabilities)推导出最大似然估计(maximum likelihood estimates)了:
$$
P_{sa}(s’)= \frac{在状态 s 执行动作 a 而到达状态 s’ 的次数}{在状态 s 执行动作 a 的次数}\qquad(4)
$$
或者,如果上面这个比例出现了$“0/0”$的情况,对应的情况就是在状态 $s$ 之前没进行过任何动作 $a$,这样就可以简单估计 $P_{sa}(s’)$ 为 $1/|S|$。(也就是说把 $P_{sa}$ 估计为在所有状态上的均匀分布(uniform distribution)。)
注意,如果在 MDP 过程中我们能获得更多经验信息(观察更多次数),就能利用新经验来更新估计的状态转移概率(estimated state transition probabilities),这样很有效率。具体来说,如果我们保存下来等式$(4)$中的分子(numerator)和分母(denominator)的计数(counts),那么观察到更多的试验的时候,就可以很简单地累积(accumulating)这些计数数值。计算这些数值的比例,就能够给出对 $P_{sa}$ 的估计。
利用类似的程序(procedure),如果奖励函数(reward) $R$ 未知,我们也可以选择在状态 $s$ 下的期望即时奖励函数(expected immediate reward) $R(s)$ 来当做是在状态 $s$ 观测到的平均奖励函数(average reward)。
学习了一个 MDP 模型之后,我们可以使用值迭代(value iteration)或者策略迭代(policy iteration),利用估计的状态转移概率(transition probabilities)和奖励函数,来去求解这个 MDP 问题。例如,结合模型学习(model learning)和值迭代(value iteration),就可以在未知状态转移概率(state transition probabilities)的情况下对 MDP 进行学习,下面就是一种可行的算法:
- 随机初始化 $\pi$ 。
- 重复 {
  $(a)$ 在 MDP 中执行 $\pi$ 作为若干次试验(trials)。
  $(b)$ 利用上面在 MDP 积累的经验(accumulated experience),更新对 $P_{sa}$ 的估计(如果可以的话也对奖励函数 $R$ 进行更新)。
  $(c)$ 利用估计的状态转移概率(estimated state transition probabilities)和奖励函数
(rewards),应用值迭代(value iteration),得到一个新的估计值函数(estimated value function) $V$。
  $(d)$ 更新 $\pi$ 为与 $V$ 对应的贪婪策略(greedy policy)。
}
我们注意到,对于这个特定的算法,有一种简单的优化方法(optimization),可以让该算法运行得更快。具体来说,在上面算法的内部循环中,使用了值迭代(value iteration),如果初始化迭代的时候不令 $V = 0$ 启动,而是使用算法中上一次迭代找到的解来初始化,这样就有了一个更好的迭代起点,能让算法更快收敛。
4 连续状态的马尔可夫决策过程(Continuous state MDPs)
目前为止,我们关注的都是有限个状态(a finite number of states)的马尔可夫决策过程(MDPs)。接下来我们要讲的就是有无限个状态(an infinite number of states)的情况下的算法。例如,对于一辆车,我们可以将其状态表示为 $(x, y, \theta, \dot x,\dot y,\dot\theta)$,其中包括位置(position) $(x, y)$,方向(orientation)$\theta$, 在 $x$ 和 $y$ 方向的速度分量 $\dot x$ 和 $\dot y$,以及角速度(angular velocity)$\dot\theta$。这样,$S = R^6$ 就是一个无限的状态集合,因为一辆车的位置和方向的个数是有无限可能$^2$。与此相似,在习题集 $4$ 中看到的倒立摆问题(inverted pendulum)中,状态也有$(x,\theta,\dot x,\dot\theta)$,其中的 $\theta$ 是杆的角度。在直升机飞行的三维空间中,状态的形式则为$(x,y,x,\phi,\theta,\psi,\dot x,\dot y,\dot z,\dot\phi,\dot\theta,\dot\psi)$,其中包含了滚动角(roll)$\phi$,俯仰角(pitch)$\theta$,以及偏航角(yaw)$\psi$,这几个角度确定了直升机在三维空间中的运动方向。在本节中,我们考虑状态空间为 $S = R^n$ 的情况,并描述此种情况下解决 MDPs 的方法。
2 从理论上讲,$\theta$ 是一个方向(orientation),所以更应当把 $\theta$ 的取值空间写为 $\theta \in [\pi, \pi)$,而不是写为实数集合 $\theta \in R$;不过在我们讨论的问题中,这种区别不要紧。
4.1 离散化(Discretization)
解决连续状态 MDP 问题最简单的方法可能就是将状态空间(state space)离散化(discretize),然后再使用之前讲过的算法,比如值迭代(value iteration)或者策略迭代(policy iteration)来求解。
例如,假设我们有一个二维状态空间$(s_1,s_2)$,就可以用下面的网格(grid)来将这个状态空间离散化:
如上图所示,每个网格单元(grid cell)表示的都是一个独立的离散状态 $\overline s$。这样就可以把一个连续状态 MDP 用一个离散状态的 $(\overline S, A, {P_{\overline sa}}, \gamma, R)$ 来进行逼近,其中的$\overline S$ 是离散状态集合,而${P_{\overline sa}}$ 是此离散状态上的状态转移概率(state transition probabilities),其他项目同理。然后就可以使用值迭代(value iteration)或者策略迭代(policy iteration)来求解出离散状态的 MDP $(\overline S, A, {P_{\overline sa}}, \gamma, R)$ 的 $V^*(\overline s)$ 和 $\pi^*(\overline s)$。当真实系统是某种连续值的状态 $s \in S$,而有需要选择某个动作来执行,就可以计算对应的离散化的状态 $\overline s$,然后执行对应的动作 $\pi^*(\overline s)$。
这种离散化方法(discretization approach)可以解决很多问题。然而,也有两个缺陷(downsides)。首先,这种方法使用了对 $V^*$ 和 $\pi^*$ 相当粗糙的表征方法。具体来说,这种方法中假设了在每个离散间隔(discretization intervals)中的值函数(value function)都是一个常数值(也就是说,值函数是在每个网格单元中分段的常数。)。
要更好理解这样表征的的局限性,可以考虑对下面这一数据集进行函数拟合的监督学习问题:
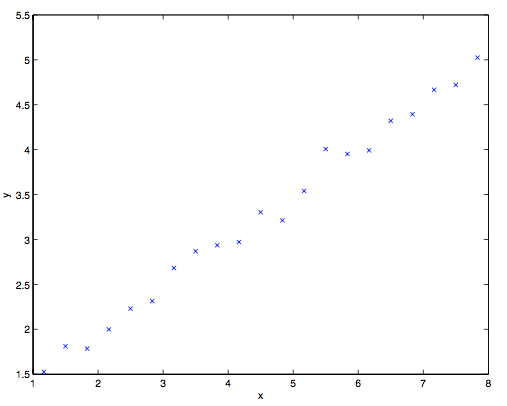
很明显,上面这个数据适合使用线性回归。然而,如果我们对 $x$ 轴进行离散化,那么在每个离散间隔中使用分段常数表示,对同样的数据进行拟合,得到的曲线则如下所示:
这种分段常数表示,对于很多的光滑函数,都不能算好。这会导致输入值缺乏平滑(little smoothing over the inputs),而且在不同的望各单元中间也没有进行扩展(generalization)。使用这种表示方法,我们还需要一种非常精细的离散化过程(也就是网格单元要非常小),才能得到一个比较好的近似估计。
第二个缺陷可以称之为维度的诅咒(curse of dimensionality)。 设 $S = R^n$ ,然后我们队每个 $n$ 维度状态离散成 $k$ 个值。这样总共的离散状态的个数就是 kn。在状态空间 $n$ 的维度中,这个值会呈指数级增长,对于大规模问题就不好缩放了。例如,对于一个 $10$ 维的状态,如果我们把每个状态变量离散化成为 $100$ 个值,那么就会有 $100^{10} = 10^{20}$ 个离散状态,这个维度太大了,远远超过了当前桌面电脑能应付的能力之外。
根据经验法则(rule of thumb),离散化通常非常适合用于 $1$ 维和 $2$ 维的问题(而且有着简单和易于快速实现的优势)。对于 $4$ 维状态的问题,如果使用一点小聪明,仔细挑选离散化方法,有时候效果也不错。如果你超级聪明,并且还得有点幸运,甚至也有可能将离散化方法使用于 $6$ 维问题。不过在更高维度的问题中,就更是极其难以使用这种方法了。
4.2 值函数近似(Value function approximation)
现在我们来讲另外一种方法,能用于在连续状态的 MDPs 问题中找出策略,这种方法也就是直接对进行近似 $V^*$,而不使用离散化。这个方法就叫做值函数近似(value function approximation),在很多强化学习的问题中都有成功的应用。
4.2.1 使用一个模型或模拟器(Using a model or simulator)
要开发一个值函数近似算法,我们要假设已经有一个对于 MDP 的模型, 或者模拟器。 简单来看,一个模拟器就是一个黑箱子(black-box),接收输入的任意(连续值的)状态 $s_t$ 和动作 $a_t$,然后输出下一个状态 $s_{t+1}$,这个新状态是根据状态转移概率(state transition probabilities) $P_{s_ta_t}$ 取样(sampled)得来:
有很多种方法来获取这样的一个模型。其中一个方法就是使用物理模拟(physics simulation)。 例如,在习题集 $4$ 中倒立摆模拟器,就是使用物理定律,给定当前时间 $t$ 和采取的动作 $a$,假设制导系统的所有参数,比如杆的长度、质量等等,来模拟计算在 $t+1$ 时刻杆所处的位置和方向。另外也可以使用现成的物理模拟软件包,这些软件包将一个机械系统的完整物理描述作为输入,当前状态 $s_t$ 和动作 $a_t$,然后计算出未来几分之一秒的系统状态 $s_{t+1}$。$^3$
3 开放动力引擎(Open Dynamics Engine,
http://www.ode.com)就是一个开源物理模拟器,可以用来模拟例如倒立摆这样的系统,在强化学习研究领域中,已经相当流行了。
另外一个获取模型的方法,就是从 MDP 中收集的数据来学习生成一个。例如,加入我们在一个 MDP 过程中重复进行了 $m$ 次试验(trials), 每一次试验的时间步长(time steps)为 $T$。这可以用如下方式实现,首先是随机选择动作,然后执行某些特定策略(specific policy),或者也可以用其他方法选择动作。接下来就能够观测到 $m$ 个状态序列,如下所示:
$$
\begin{aligned}
&s_0^{(1)}\xrightarrow{a_0^{(1)}}s_1^{(1)}\xrightarrow{a_1^{(1)}}s_2^{(1)}\xrightarrow{a_2^{(1)}}\dots\xrightarrow{a_{T-1}^{(1)}}s_T^{(1)} \
&s_0^{(2)}\xrightarrow{a_0^{(2)}}s_1^{(2)}\xrightarrow{a_1^{(2)}}s_2^{(2)}\xrightarrow{a_2^{(2)}}\dots\xrightarrow{a_{T-1}^{(2)}}s_T^{(2)} \
&\cdots \
&s_0^{(m)}\xrightarrow{a_0^{(m)}}s_1^{(m)}\xrightarrow{a_1^{(m)}}s_2^{(m)}\xrightarrow{a_2^{(m)}}\dots\xrightarrow{a_{T-1}^{(m)}}s_T^{(m)}
\end{aligned}
$$
然后就可以使用学习算法,作为一个关于 $s_t$ 和 $a_t$ 的函数来预测 $s_{t+1}$。
例如,对于线性模型的学习,可以选择下面的形式:
$$
s_{t+1}=As_t+Ba_t\qquad(5)
$$
然后使用类似线性回归(linear regression)之类的算法。上面的式子中,模型的参数是两个矩阵 $A$ 和 $B$,然后可以使用在 $m$ 次试验中收集的数据来进行估计,选择:
$$
arg\min_{A,B}\sum_{i=1}^m\sum_{t=0}^{T-1}||s_{t+1}^{(i)}-(As_t^{(i)}+Ba_t^{(i)})||^2
$$
(这对应着对参数(parameters)的最大似然估计(maximum likelihood estimate)。)
通过学习得到 $A$ 和 $B$ 之后,一种选择就是构建一个确定性 模型(deterministic model),在此模型中,给定一个输入 $s_t$ 和 $a_t$,输出的则是固定的 $s_{t+1}$。具体来说,也就是根据上面的等式$(5)$来计算 $s_{t+1}$。或者用另外一种办法,就是建立一个随机 模型(stochastic model),在这个模型中,输出的 $s_{t+1}$ 是关于输入值的一个随机函数,以如下方式建模:
$$
s_{t+1}=As_t+Ba_t+\epsilon_t
$$
上面式子中的 $\epsilon_t$ 是噪音项(noise term),通常使用一个正态分布来建模,即 $\epsilon_t\sim N (0, \Sigma)$。(协方差矩阵(covariance matrix) $\Sigma$ 也可以从数据中直接估计出来。)
这里,我们把下一个状态 $s_{t+1}$ 写成了当前状态和动作的一个线性函数;不过当然也有非线性函数的可能。比如我们学习一个模型 $s_{t+1} = A\phi_s(s_t) + B\phi_a(a_t)$,其中的 $\phi_s$ 和 $\phi_a$ 就可以使某些映射了状态和动作的非线性特征。另外,我们也可以使用非线性的学习算法,例如局部加权线性回归(locally weighted linear regression)进行学习,来将 $s_{t+1}$ 作为关于 $s_t$ 和 $a_t$ 的函数进行估计。 这些方法也可以用于建立确定性的(deterministic)或者随机的(stochastic)MDP 模拟器。
4.2.2 拟合值迭代(Fitted value iteration)
接下来我们要讲的是拟合值迭代算法(fitted value iteration algorithm), 作为对一个连续状态 MDP 中值函数的近似。在这部分钟,我们假设学习问题有一个连续的状态空间 $S = R^n$,而动作空间 $A$ 则是小规模的离散空间。$^4$
4 在实践中,大多数的 MDPs 问题中,动作空间都要远远比状态空间小得多。例如,一辆汽车可能有 $6$维的状态空间,但是动作空间则只有 $2$维,即转向和速度控制;倒立的摆有 $4$维状态空间,而只有 $1$维的动作空间;一架直升机有 $12$维状态空间,只有 $4$维的动作空间。所以对动作空间进行离散化,相比对状态空间进行离散化,遇到的问题通常会少得多。
回忆一下值迭代(value iteration),其中我们使用的更新规则如下所示:
$$
\begin{aligned}
V(s) &:= R(s)+\gamma\max_a \int_{s’}P_{sa}(s’)V(s’)ds’ \qquad&(6)\
&= R(s)+\gamma\max_a E_{s’\sim P_{sa}}[V(s’)]\qquad&(7)
\end{aligned}
$$
(在第二节当中,我们把值迭代的更新规则写成了求和(summation)的形式:$V(s) := R(s)+\gamma\max_a\sum_{s’}P_{sa}(s’)V(s’)$而没有像刚刚上面这样写成在状态上进行积分的形式;这里采用积分的形式来写,是为了表达我们现在面对的是连续状态的情况,而不再是离散状态。)
拟合值迭代(fitted value iteration)的主要思想就是,在一个有限的状态样本 $s^{(1)}, … s^{(m)}$ 上,近似执行这一步骤。具体来说,要用一种监督学习算法(supervised learning algorithm),比如下面选择的就是线性回归算法(linear regression),以此来对值函数(value function)进行近似,这个值函数可以使关于状态的线性或者非线性函数:
$$
V(s)=\theta^T\phi(s)
$$
上面的式子中,$\phi$ 是对状态的某种适当特征映射(appropriate feature mapping)。对于有限个 $m$ 状态的样本中的每一个状态 $s$,拟合值迭代算法将要首先计算一个量 $y^{(i)}$,这个量可以用 $R(s)+\gamma\max_aE_{s’\sim P_{sa}}[V(s’)]$ 来近似(根据等式$(7)$的右侧部分)。然后使用一个监督学习算法,通过逼近 $R(s) + \gamma\max_a E_{s’\sim P_{sa}}[V (s’)]$ 来得到$V(s)$(或者也可以说是通过逼近到 $y^{(i)}$ 来获取 $V(s)$)。
具体来说,算法如下所示:
- 从 $S$ 中随机取样 $m$ 个状态 $s^{(1)}, s^{(2)}, . . . s^{(m)}\in S$。
- 初始化 $\theta := 0$.
- 重复 {
  对 $i = 1, … , m$ {
    对每一个动作 $a \in A$ {
      取样 $s_1’,… , s_k’\sim P_{s^{(i)}a}$ (使用一个 MDP 模型)
      设$q(a)=\frac 1k\sum_{j=1}^kR(s^{(i)})+\gamma V(s_j’)$
        // 因此, $q(a)$ 是对$R(s)^{(i)}+\gamma E_{s’\sim P_{sa}}[V(s’)]$的估计。
    }
    设$y^{(i)} = \max_a q(a)$.
      // 因此, $y^{(i)}$是对$R(s^{(i)})+\gamma\max_aE_{s’\sim P_{sa}}[V(s’)]$的估计。
    }
    // 在原始的值迭代算法(original value iteration algorithm)中,(离散状态的情况 )
    // 是根据 $V(s^{(i)}) := y^{(i)}$ 来对值函数(value function)进行更新。
    // 而在这里的这个算法中,我们需要的让二者近似相等,即 $V(s^{(i)}) \approx y^{(i)}$,
    // 这可以通过使用监督学习算法(线性回归)来实现。
    设 $\theta := arg\min_\theta \frac 12\sum_{i=1}^m(\theta^T\phi(s^{(i)})-y^{(i)})^2$
  }
以上,我们就写出了一个拟合值迭代算法(fitted value iteration),其中使用线性回归作为算法(linear regression),使 $V (s^{(i)})$ 逼近 $y^{(i)}$。这个步骤完全类似在标准监督学习问题(回归问题)中面对 $m$ 个训练集 $(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),…,(x^{(m)},y^{(m)})$ ,而要利用学习得到从$x$ 到 $y$ 的映射函数的情况;唯一区别无非是这里的 $s$ 扮演了当时 $x$ 的角色。虽然我们上面描述的算法是线性回归,很显然其他的回归算法(例如局部加权线性回归)也都可以使用。
与离散状态集合上进行的的值迭代(value iteration)不同,拟合值迭代(fitted value iteration)并不一定总会收敛(converge)。然而,在实践中,通常都还是能收敛的(或者近似收敛),而且能解决大多数问题。另外还要注意,如果我们使用一个 MDP 的确定性模拟器/模型的话,就可以对拟合值迭代进行简化,设置算法中的 $k = 1$。这是因为等式$(7)$当中的期望值成为了对确定性分布(deterministic distribution)的期望,所以一个简单样本(single example)就足够计算该期望了。否则的话,在上面的算法中,就还要取样出 $k$ 个样本,然后取平均值,来作为对期望值的近似(参考在算法伪代码中的 $q(a)$ 的定义)。
最后,拟合值迭代输出的 $V$,也就是对 $V^*$ 的一个近似。这同时隐含着对策略函数(policy)的定义。 具体来说,当我们的系统处于某个状态 $s$ 的时候,需要选择一个动作,我们可能会选择的动作为:
$$
arg\max_a E_{s’\sim P_{sa}}[V(s’)]\qquad(8)
$$
这个计算/近似的过程很类似拟合值迭代算法的内部循环体,其中对于每一个动作,我们取样 $s_1’,…,s_k’\sim P_{sa}$ 来获得近似期望值(expectation)。(当然,如果模拟器是确定性的,就可以设 $k = 1$。)
在实际中,通常也有其他方法来实现近似这个步骤。例如,一种很常用的情况就是如果模拟器的形式为 $s_{t+1} = f(s_t,a_t) + \epsilon_t$,其中的 $f$ 是某种关于状态 $s$ 的确定性函数(例如 $f(s_t,a_t) = As_t + Ba_t$),而 $\epsilon$ 是均值为 $0$ 的高斯分布的噪音。在这种情况下,可以通过下面的方法来挑选动作:
$$
arg\max_a V(f(s,a))
$$
也就是说,这里只是设置 $\epsilon_t = 0$(即忽略了模拟器中的噪音项),然后设 $k = 1$。同样地,这也可以通过在等式$(8)$中使用下面的近似而推出:
$$
\begin{aligned}
E_{s’}[V(s’)] &\approx V(E_{s’}[s’]) &(9) \
&= V(f(s,a)) &(10)
\end{aligned}
$$
这里的期望是关于随机分布 $s’\sim P_{sa}$ 的。所以只要噪音项目 $\epsilon_t$ 很小,这样的近似通常也是合理的。
然而,对于那些不适用于这些近似的问题,就必须使用模型,取样 $k|A|$ 个状态,以便对上面的期望值进行近似,当然这在计算上的开销就很大了。
第十三章
第十四部分 线性二次调节,微分动态规划,线性二次高斯分布
上面三个名词的英文原版分别为:
- Linear Quadratic Regulation,缩写为LQR;
- Differential Dynamic Programming,缩写为DDP;
- Linear Quadratic Gaussian,缩写为LQG。
1 有限范围马尔科夫决策过程(Finite-horizon MDPs)
前面关于强化学习(Reinforcement Learning)的章节中,我们定义了马尔科夫决策过程(Markov Decision Processes,缩写为MDPs),还涉及到了简单情景下的值迭代(Value Iteration)和策略迭代(Policy Iteration)。还具体介绍了最优贝尔曼方程(optimal Bellman equation), 这个方程定义了对应最优策略(optimal policy)$\pi^*$的最优值函数(optimal value function)$V^{\pi^*}$。
$$
V^{\pi^*}(s)=R(s)+\max_{a \in \mathcal{A}} \gamma \sum_{s’ \in \mathcal{S}} P_{sa}(s’)V^{\pi^*}(s’)
$$
通过优化值函数,就可以恢复最优策略$\pi^*$:
$$
\pi^*(s)=\arg\max_{a\in \mathcal{A}} \sum_{s’\in \mathcal{S}} P_{sa} (s’)V^{\pi^*}(s’)
$$
本章的讲义将会介绍一个更通用的情景:
这次我们希望写出来的方程能够对离散和连续的案例都适用。因此就要用期望$E_{s’ \sim P_{sa}}[V^{\pi^*}(s’)]$替代求和$\sum_{s’\in S} P_{sa}(s’)V^{\pi^*}(s’)$。这就意味着在下一个状态中使用值函数的期望(exception)。对于离散的有限案例,可以将期望写成对各种状态的求和。在连续场景,可以将期望写成积分(integral)。上式中的记号$s’\sim P_{sa}$的意思是状态$s’$是从分布$P_{sa}$中取样得到的。
接下来还假设奖励函数(reward)同时依赖状态(states)和动作(actions)。 也就是说,$R:\mathcal{S}\times\mathcal{A} \rightarrow R$。这就意味着前面计算最优动作的方法改成了
$$
\pi^*(s)=\arg\max_{a\in A} R(s,a)+\gamma E_{s’\sim P_{sa}}[V^{\pi^*}(s’)]
$$
- 以前我们考虑的是一个无限范围马尔科夫决策过程(infinite horizon MDP),这回要改成有限范围马尔科夫决策过程(finite horizon MDP), 定义为一个元组(tuple):
$$
(\mathcal{S},\mathcal{A},P_{sa},T,R)
$$
其中的$T>0$的时间范围(time horizon), 例如$T=100$。这样的设定下,支付函数(payoff)就变成了:
$$
R(s_0,a_0)+R(s_1,a_1)+\dots+R(s_T,a_T)
$$
而不再是之前的:
$$
\begin{aligned}
& R(s_0,a_0)+\gamma R(s_1,a_1) + \gamma^2 R(s_2,a_2)+\dots\
& \sum^\infty_{t=0}R(s_t,a_t)\gamma^t
\end{aligned}
$$
折扣因子(discount factor)$\gamma$哪去了呢?还记得当初引入这个$\gamma$的一部分原因就是由于要保持无穷项求和(infinite sum)是有限值( finite)并且好定义(well-defined)的么?如果奖励函数(rewards)绑定了一个常数$\bar R$,则支付函数(payoff)也被绑定成:
$$
|\sum^{\infty}{t=0}R(s_t)\gamma^t|\le \bar R \sum^{\infty}{t=0}\gamma^t
$$
这就能识别是一个几何求和(geometric sum)!现在由于支付函数(payoff)是一个有限和(finite sum)了,那折扣因子(discount factor)$\gamma$就没有必要再存在了。
在这种新环境下,事情就和之前不太一样了。首先是最优策略(optimal policy)$\pi^*$可能是非稳定的(non-stationary),也就意味着它可能随着时间步发生变化。 也就是说现在有:
$$
\pi^{(t)}:\mathcal{S}\rightarrow\mathcal{A}
$$
上面括号中的$(t)$表示了在第$t$步时候的策略函数(policy)。遵循策略$\pi^{(t)}$的有限范围马尔科夫决策过程如下所示:开始是某个状态$s_0$,然后对应第$0$步时候的策略$\pi^{(0)}$采取某种行为$a_0:= \pi^{(0)}(s_0)$。然后马尔科夫决策过程(MDP)转换到接下来的$s_1$,根据$P_{s_0a_0}$来进行调整。然后在选择遵循第$1$步的新策略$\pi^{(1)}$的另一个行为$a_1:= \pi^{(1)}(s_1)$。依次类推进行下去。
为什么在有限范围背景下的优化策略函数碰巧就是非稳定的呢?直观来理解,由于我们只能够选择有限的应对行为,我们可能要适应不同环境的不同策略,还要考虑到剩下的时间(步骤数)。设想有一个网格,其中有两个目标,奖励值分别是$+1$和$+10$。那么开始的时候我们的行为肯定是瞄准了最高的奖励$+10$这个目标。但如果过了几步之后,我们更靠近$+1$这个目标而没有足够的剩余步数去到达$+10$这个目标,那更好的策略就是改为瞄准$+1$了。
- 这样的观察就使得我们可以使用对时间依赖的方法(time dependent dynamics):
$$
s_{t+1} \sim P^{(t)}_{s_t,a_t}
$$
这就意味着变换分布(transition distribution)$P^{(t)}_{s_t,a_t}$随着时间而变化。对$R^{(t)}$而言也是如此。要注意,现在这个模型就更加符合现实世界的情况了。比如对一辆车来说,油箱会变空,交通状况会变化,等等。结合前面提到的内容,就可以使用下面这个通用方程(general formulation)来表达我们的有限范围马尔科夫决策过程(fi nite horizon MDP):
$$
(\mathcal{S},\mathcal{A},P^{(t)}_{sa},T,R^{(t)})
$$
备注: 上面的方程其实和在状态中加入时间所得到的方程等价。
在时间$t$对于一个策略$\pi$的值函数也得到了定义,也就是从状态$s$开始遵循策略$\pi$生成的轨道(trajectories)的期望(expectation)。
$$
V_t(s)=E[R^{(t)}(s_t,a_t)+\dots+R^{(T)}(s_T,a_T)|s_t=s,\pi ]
$$
现在这个方程就是:在有限范围背景下,如何找到最优值函数(optimal value function):
$$
V^*t(s)=\max{\pi}V^{\pi}_t(s)
$$
结果表明对值迭代(Value Iteration)的贝尔曼方程(Bellman’s equation)正好适合动态规划(Dynamic Programming)。 这也没啥可意外的,因为贝尔曼(Bellman)本身就是动态规划的奠基人之一,而贝尔曼方程(Bellman equation)和这个领域有很强的关联性。为了理解为啥借助基于迭代的方法(iteration-based approach)就能简化问题,我们需要进行下面的观察:
- 在游戏终结(到达步骤$T$)的时候,最优值(optimal value)很明显就是
$$
\forall s\in \mathcal{S}: V^*T(s):=\max{a\in A} R^{(T)}(s,a) \qquad(1)
$$
- 对于另一个时间步$0\le t <T$,如果假设已经知道了下一步的最优值函数$V^*_{t+1}$,就有:
$$
\forall t<T,s \in \mathcal{S}: V^*t (s):= \max{a\in A} [R^{(t)}(s,a)+E_{s’\sim P^{(t)}{sa}}[V^*{t+1}(s’)]] \qquad (2)
$$
观察并思考后,就能想出一个聪明的算法来解最优值函数了:
- 利用等式$(1)$计算$V^*_T$。
- for $t= T-1,\dots,0$:
  使用$V^*_{t+1}$利用等式$(2)$计算$V^*_t$。
备注: 可以将标准值迭代(standard value iteration)看作是上述通用情况的一个特例,就是不用记录时间(步数)。结果表明在标准背景下,如果对$T$步骤运行值迭代,会得到最优值迭代的一个$\gamma^T$的近似(几何收敛,geometric convergence)。参考习题集4中有对下列结果的证明:
定理:设$B$表示贝尔曼更新函数(Bellman update),以及$||f(x)||_\infty:= \sup_x|f(x)|$。如果$V_t$表示在第$t$步的值函数,则有:
$$
\begin{aligned}
||V_{t+1}-V^*||_\infty &=||B(V_t)-V^*||_\infty\
&\le \gamma||V_t-V^*||_\infty\
&\le \gamma^t||V_1-V^*||_\infty
\end{aligned}
$$
也就是说贝尔曼运算器$B$成了一个$\gamma$收缩算子(contracting operator)。
2 线性二次调节(Linear Quadratic Regulation,缩写为LQR)
在本节,我们要讲一个上一节所提到的有限范围(finite-horizon)背景下精确解(exact solution) 很容易处理的特例。这个模型在机器人领域用的特别多,也是在很多问题中将方程化简到这一框架的常用方法。
首先描述一下模型假设。考虑一个连续背景,都用实数集了:
$$
\mathcal{S}=R^n,\quad\mathcal{A}=R^d
$$
然后设有噪音(noise)的线性转换(linear transitions):
$$
s_{t+1}=A_ts_t+B_ta_t+w_t
$$
上式中的$A_t\in R^{n\times n},B_t\in R^{n\times d}$实矩阵,而$w_t\sim N(0,\Sigma_t)$是某个高斯分布的噪音(均值为零)。我们接下来要讲的内容就表明:只要噪音的均值是$0$,就不会影响最优化策略。
另外还要假设一个二次奖励函数(quadratic rewards):
$$
R^{(t)}(s_t,a_t)=-s_t^TU_ts_t-a_t^TW_ta_t
$$
上式中的$U_t\in R^{n\times n},W_t\in R^{n\times d}$都是正定矩阵(positive definite matrices),这就意味着奖励函数总是负的(negative)。
要注意这里的奖励函数的二次方程(quadratic formulation)就等价于无论奖励函数是否更高我们都希望能接近原始值(origin)。例如,如果$U_t=I_n$就是$n$阶单位矩阵(identity matrix),而$W_t=I_d$为一个$d$阶单位矩阵,那么就有$R_t=-||s_t||^2-||a_t||^2$,也就意味着我们要采取光滑行为(smooth actions)($a_t$的范数(norm)要小)来回溯到原始状态($s_t$的范数(norm)要小)。这可以模拟一辆车保持在车道中间不发生突发运动。
接下来就可以定义这个线性二次调节(LQR)模型的假设了,这个LQR算法包含两步骤:
第一步设矩阵$A,B,\Sigma$都是未知的。那就得估计他们,可以利用强化学习课件中的值估计(Value Approximation)部分的思路。首先是从一个任意策略(policy)收集转换(collect transitions)。然后利用线性回归找到$\arg\min_{A,B}\sum^m_{i=1}\sum^{T-1}{t=0}||s^{(i)}_{t+1}- ( As^{(i)}_t +Ba^{(i)}_t)||^2$。最后利用高斯判别分析(Gaussian Discriminant Analysis,缩写为GDA)中的方法来学习$\Sigma$。
第二步假如模型参数已知了,比如可能是给出了,或者用上面第一步估计出来了,就可以使用动态规划(dynamic programming)来推导最优策略(optimal policy)了。
也就是说,给出了:
$$
\begin{cases}
s_{t+1} &= A_ts_t+B_ta_t+w_t\qquad 已知A_t,B_t,U_t,W_t,\Sigma_t\
R^{(t)}(s_t,a_t)&= -s_t^TU_ts_t-a^T_tW_ta_t
\end{cases}
$$
然后要计算出$V_t^*$。如果回到第一步,就可以利用动态规划,就得到了:
- 初始步骤(Initialization step)
  对最后一次步骤$T$,
$$
\begin{aligned}
V^*T(s_T)&=\max{a_T\in A}R_T(s_T,a_T)\
&=\max_{a_T\in A}-s^T_TU_ts_T - a^T_TW_ta_T\
&= -s^T_TU_ts_T\qquad\qquad(\text{对}a_T=0\text{最大化})
\end{aligned}
$$
   (译者注:原文这里第一步的第二行公式中用的是$U_T$,应该是写错了,结合上下文公式推导来看,分明应该是$U_t$)
- 递归步骤(Recurrence step)
  设$t<T$。加入已经知道了$V^*_{t+1}$。
定理1:很明显如果$V^*_{t+1}$是$s_t$的一个二次函数,则$V_t^*$也应该是$s_t$的一个二次函数。也就是说,存在某个矩阵$\Phi$以及某个标量$\Psi$满足:
$$
\begin{aligned}
\text{if} \quad V^*_{t+1}(s_{t+1}) &= s^T_{t+1}\Phi_{t+1}s_{t+1}+\Psi_{t+1}\
\text{then} \quad V^*_t(s_t)&=s^T_t\Phi_ts_t+\Psi_t
\end{aligned}
$$
对时间步骤$t=T$,则有$\Phi_t=-U_T,\Psi_T=0$。
定理2:可以证明最优策略是状态的一个线性函数。
已知$V^*_{t+1}$就等价于知道了$\Phi_{t+1},\Psi_{t+1}$,所以就只需要解释如何从$\Phi_{t+1},\Psi_{t+1}$去计算$\Phi_{t},\Psi_{t}$,以及问题中的其他参数。
$$
\begin{aligned}
V^*t(s_t)&= s_t^T\Phi_ts_t+\Psi_t \
&= \max{a_t}[R^{(t)}(s_t,a_t)+E_{s_{t+1}\sim P^{(t)}{s_t,a_t}}[V^*{t+1}(s_{t+1})]] \
&= \max_{a_t}[-s_t^TU_ts_t-a_t^TV_ta_t+E_{s_{t+1}\sim N(A_ts_t+B_ta_t,\Sigma_t)} [s_{t+1}^T\Phi_{t+1}s_{t+1}+\Psi_{t+1}] ] \
\end{aligned}
$$
上式中的第二行正好就是最优值函数(optimal value function)的定义,而第三行是通过代入二次假设和模型方法。注意最后一个表达式是一个关于$a_t$的二次函数,因此很容易就能优化掉$^1$。然后就能得到最优行为(optimal action)$a^*_t$:
1 这里用到了恒等式(identity)$E[w_t^T\Phi_{t+1}w_t] =Tr(\Sigma_t\Phi_{t+1}),\quad \text{其中} w_t\sim N(0,\Sigma_t)$)。
$$
\begin{aligned}
a^*t&= [(B_t^T\Phi{t+1}B_t-V_t)^{-1}B_t\Phi_{t+1}A_t]\cdot s_t\
&= L_t\cdot s_t\
\end{aligned}
$$
上式中的
$$
L_t := [(B_t^T\Phi_{t+1}B_t-V_t)^{-1}B_t\Phi_{t+1}A_t]
$$
这是一个很值得注意的结果(impressive result):优化策略(optimal policy)是关于状态$s_t$的线性函数。 对于给定的$a_t^*$,我们就可以解出来$\Phi_t$和$\Psi_t$。最终就得到了离散里卡蒂方程(Discrete Ricatti equations):
$$
\begin{aligned}
\Phi_t&= A^T_t(\Phi_{t+1}-\Phi_{t+1}B_t(B^T_t\Phi_{t+1}B_t-W_t)^{-1}B_t\Phi_{t+1})A_t-U_t\
\Psi_t&= -tr(\Sigma_t\Phi_{t+1})+\Psi_{t+1}\
\end{aligned}
$$
定理3:要注意$\Phi_t$既不依赖$\Psi_t$也不依赖噪音项$\Sigma_t$!由于$L_t$是一个关于$A_t,B_t,\Phi_{t+1}$的函数,这就暗示了最优策略也不依赖噪音! (但$\Psi_t$是依赖$\Sigma_t$的,这就暗示了最优值函数$V^*_t$也是依赖噪音$\Sigma_t$的。)
然后总结一下,线性二次调节(LQR)算法就如下所示:
- 首先,如果必要的话,估计参数$A_t,B_t,\Sigma_t$。
- 初始化$\Phi_T:=-U_T,\quad \Psi_T:=0$。
- 从$t=T-1,\dots,0$开始迭代,借助离散里卡蒂方程(Discrete Ricatti equations)来利用$\Phi_{t+1},\Psi_{t+1}$来更新$\Phi_{t},\Psi_{t}$,如果存在一个策略能朝着$0$方向推导状态,收敛就能得到保证。
利用定理3,我们知道最优策略不依赖与$\Psi_t$而只依赖$\Phi_t$,这样我们就可以只 更新$\Phi_t$,从而让算法运行得更快一点!
3 从非线性方法(non-linear dynamics)到线性二次调节(LQR)
很多问题都可以化简成线性二次调节(LDR)的形式,包括非线性的模型。LQR是一个很好的方程,因为我们能够得到很好的精确解,但距离通用还有一段距离。我们以倒立摆(inverted pendulum)为例。状态的变换如下所示:
$$
\begin{pmatrix}
x_{t+1}\
\dot x_{t+1}\
\theta_{t+1}\
\dot \theta_{t+1}
\end{pmatrix}=F\begin{pmatrix} \begin{pmatrix} x_t\
\dot x_t\
\theta_t\
\dot\theta_t \end{pmatrix},a_t\end{pmatrix}
$$
其中的函数$F$依赖于角度余弦等等。然后这个问题就成了:
$$
我们能将这个系统线性化么?
$$
3.1 模型的线性化(Linearization of dynamics)
假设某个时间$t$上,系统的绝大部分时间都处在某种状态$\bar s_t$上,而我们要选取的行为大概就在$\bar a_t$附近。对于倒立摆问题,如果我们达到了某种最优状态,就会满足:行为很小并且和竖直方向的偏差不大。
这就要用到泰勒展开(Taylor expansion)来将模型线性化。简单的情况下状态是一维的,这时候转换函数$F$就不依赖于行为,这时候就可以写成:
$$
s_{t+1}=F(s_t)\approx F(\bar s_t)+ F’(\bar s_t)\cdot (s_t-\bar s_t)
$$
对于更通用的情景,方程看着是差不多的,只是用梯度(gradients)替代简单的导数(derivatives):
$$
s_{t+1}\approx F(\bar s_t,\bar a_t)+\nabla _sF(\bar s_t,\bar a_t)\cdot (s_t-\bar s_t)+\nabla_aF(\bar s_t,\bar a_t)\cdot (a_t-\bar a_t) \qquad \text{(3)}
$$
现在$s_{t+1}$就是关于$s_t,a_t$的线性函数了,因为可以将等式$(3)$改写成下面的形式:
$$
s_{t+1}\approx As_t+Ba_t+k
$$
(译者注:原文这里的公式应该是写错了,写成了$s_{t+1}\approx As_t+Bs_t+k$)
上式中的$k$是某个常数,而$A,B$都是矩阵。现在这个写法就和在LQR里面的假设非常相似了。这时候只要摆脱掉常数项$k$就可以了!结果表明只要任意增长一个维度就可以将常数项吸收进$s_t$中区。这和我们在线性回归的课程里面用到的办法一样。
3.2 微分动态规划(Differential Dynamic Programming,缩写为DDP)
如果我们的目标就是保持在某个状态$s^*$,上面的方法都能够很适合所选情景(比如倒立摆或者一辆车保持在车道中间)。不过有时候我们的目标可能要更复杂很多。
本节要讲的方法适用于要符合某些轨道的系统(比如火箭发射)。这个方法将轨道离散化称为若干离散的时间步骤,然后运用前面的方法创建中间目标!这个方法就叫做微分动态规划(Differential Dynamic Programming,缩写为DDP)。 主要步骤包括:
第一步利用简单控制器(naive controller)创建一个标称轨道(nominal trajectory),对要遵循轨道进行近似。也就是说,我们的控制器可以用如下方法来近似最佳轨道:
$$
s^*_0,a^*_0\rightarrow s^*_1,a^*_1\rightarrow\dots
$$
第二步在每个轨道点(trajectory point)$s^*_t$将模型线性化,也就是:
$$
s_{t+1}\approx F(s^*_t,a^*_t)+\nabla_s F(s^*_t,a^*_t)(s_t-s^*_t)+\nabla_aF(s^*_t,a^*_t)(a_t-a^*_t)
$$
上面的$s_t,a_t$是当前的状态和行为。现在已经在每个轨道点都有了线性估计了,就可以使用前面的方法将其改写成:
$$
s_{t+1}=A_t\cdot s_t+B_t\cdot a_t
$$
(要注意在这个情况下,我们可以使用在本章一开头所提到的非稳定动力学模型背景。)
注意, 这里我们可以对奖励函数(reward)$R^{(t)}$推导一个类似的积分(derivation),使用一个二阶泰勒展开(second-order Taylor expansion)就可以了。
$$
\begin{aligned}
R(s_t,a_t)& \approx R(s^*_t,a^*_t)+\nabla_s R(s^*_t,a^*_t)(s_t-s^*_t) +\nabla_a R(s^*_t,a^*_t)(a_t-a^*_t) \
& + \frac{1}{2}(s_t-s^*t)^TH{ss}(s_t-s^*_t)+(s_t-s^*t)^TH{sa}(a_t-a^*_t)\
& + \frac{1}{2}(a_t-a^*t)^TH{aa}(a_t-a^*_t) \
\end{aligned}
$$
上式中的$H_{xy}$表示的 $R$ 的海森矩阵(Hessian)项,对应的$x$和$y$是在$(s^*_t,a^*_t)$中得到的(略去不表)。这个表达式可以重写成:
$$
R_t(s_t,a_t)= -s_t^TU_ts_t-a_t^TW_ta_t
$$
对于某些矩阵$U_t,W_t$,可以再次使用扩展维度的方法。注意:
$$
\begin{pmatrix} 1&x \end{pmatrix}\cdot \begin{pmatrix} a& b\c&d \end{pmatrix} \cdot \begin{pmatrix} 1\x \end{pmatrix} = a+2bx+cx^2
$$
第三步现在你就能够相信这个问题可以严格写成LQR框架的形式了吧。然后就可以利用线性二次调节(LQR)来找到最优策略$\pi_t$。这样新的控制器就会更好些!
注意: 如果LQR轨道和线性近似的轨道偏离太远,可能会出现一些问题,不过这些都可以通过调节奖励函数形态来进行修正…
第四步现在就得到了一个新的控制器了(新的策略$\pi_t$),使用这个新控制器来产生一个新的轨道:
$$
s^*_0,\pi_0(s^*_0)\rightarrow s^*_1,\pi_1(s^*_1)\rightarrow \quad \rightarrow s^*_T
$$
注意当我们生成了这个新的轨道的时候,使用真实的$F$而不是其线性估计来计算变换,这就意味着:
$$
s^*_{t+1}=F(s^*_t,a^*_t)
$$
然后回到第二步,重复,直到达到某个停止条件(stopping criterion)。
4 线性二次高斯分布(Linear Quadratic Gaussian,缩写为LQG)
在现实是集中我们可能没办法观测到全部的状态$s_t$。例如一个自动驾驶的汽车只能够从一个相机获取一个图像,这就是一次观察了,而不是整个世界的全部状态。目前为止都是假设所有状态都可用。可是在现实世界的问题中并不见得总是如此,我们需要一个新工具来对这种情况进行建模:部分观测的马尔科夫决策过程(Partially Observable MDPs,缩写为POMDP)。
POMDP是一个带有了额外观察层的马尔科夫决策过程(MDP)。也就是说要加入一个新变量$o_t$,在给定的当前状态下这个$o_t$遵循某种条件分布:
$$
o_t|s_t\sim O(o|s)
$$
最终,一个有限范围的部分观测的马尔科夫决策过程(finite-horizon POMDP)就是如下所示的一个元组(tuple):
$$
(\mathcal{S},\mathcal{O},\mathcal{A},P_{sa},T,R)
$$
在这个框架下,整体的策略就是要在观测$o_1,o_2,\dots,o_t$的基础上,保持一个置信状态(belief state,对状态的分布)。 这样在PDMDP中的策略就是从置信状态到行为的映射。
在本节,我们队LQR进行扩展以适应新的环境。假设我们观测的是$y_t\in R^m$,其中的$m<n$,且有:
$$
\begin{cases}
y_t &= C\cdot s_t +v_t\
s_{t+1} &= A\cdot s_t+B\cdot a_t+ w_t\
\end{cases}
$$
上式中的$C\in R^{m\times n}$是一个压缩矩阵(compression matrix),而$v_t$是传感器噪音(和$w_t$类似也是高斯分布的)。要注意这里的奖励函数$R^{(t)}$是未做更改的,是关于状态(而不是观察)和行为的函数。另外,由于分布都是高斯分布,置信状态就也将是高斯分布的。在这样的新框架下,看看找最优策略的方法:
第一步首先计算可能状态(置信状态)的分布,以已有观察为基础。也就是说要计算下列分布的均值$s_{t|t}$以及协方差$\Sigma_{t|t}$:
$$
s_t|y_1 ,\dots, y_t \sim \mathcal{N}(s_{t|t},\Sigma_{t|t})
$$
为了进行时间效率高的计算,这里要用到卡尔曼滤波器算法(Kalman Filter algorithm)(阿波罗登月舱上就用了这个算法)。
第二步然后就有了分布了,接下来就用均值$s_{t|t}$来作为对$s_t$的最佳近似。
第三步然后设置行为$a_t:= L_ts_{t|t}$,其中的$L_t$来自正规线性二次调节算法(regular LQR algorithm)。
从直觉来理解,这样做为啥能管用呢?要注意到$s_{t|t}$是$s_t$的有噪音近似(等价于在LQR的基础上增加更多噪音),但我们已经证明过了LQR是独立于噪音的!
第一步就需要解释一下。这里会给出一个简单情境,其中在我们的方法里没有行为依赖性(但整体上这个案例遵循相同的思想)。设有:
$$
\begin{cases}
s_{t+1} &= A\cdot s_t+w_t,\quad w_t\sim N(0,\Sigma_s)\
y_t &= C\cdot s_t+v_t,\quad v_t\sim N(0,\Sigma_y)\
\end{cases}
$$
由于噪音是高斯分布的,可以很明显证明联合分布也是高斯分布:
$$
\begin{pmatrix}
s_1\
\vdots\
s_t\
y_1\
\vdots\
y_t
\end{pmatrix} \sim \mathcal{N}(\mu,\Sigma) \quad\text{for some } \mu,\Sigma
$$
然后利用高斯分布的边缘方程(参考因子分析(Factor Analysis)部分的讲义),就得到了:
$$
s_t|y_1,\dots,y_t\sim \mathcal{N}(s_{t|t},\Sigma_{t|t})
$$
可是这里使用这些方程计算边缘分布的参数需要很大的算力开销!因为这需要对规模为$t\times t$的矩阵进行运算。还记得对一个矩阵求逆需要的运算时$O(t^3)$吧,这要是在时间步骤数目上进行重复,就需要$O(t^4)$的算力开销!
卡尔曼滤波器算法(Kalman filter algorithm) 提供了计算均值和方差的更好的方法,只用在时间$t$上以一个固定的时间(constant time) 来更新!卡尔曼滤波器算法有两个基础步骤。加入我们知道了分布$s_t|y_1,\dots,y_t$:
$$
\begin{aligned}
\text{预测步骤(predict step) 计算} & s_{t+1}|y_1,\dots,y_t
\
\text{更新步骤(update step) 计算} & s_{t+1}|y_1,\dots,y_{t+1}
\end{aligned}
$$
然后在时间步骤上迭代!预测和更新这两个步骤的结合就更新了我们的置信状态,也就是说整个过程大概类似:
$$
(s_{t}|y_1,\dots,y_t)\xrightarrow{predict} (s_{t+1}|y_1,\dots,y_t)
\xrightarrow{update} (s_{t+1}|y_1,\dots,y_{t+1})\xrightarrow{predict}\dots
$$
预测步骤 假如我们已知分布:
$$
s_{t}|y_1,\dots,y_t\sim \mathcal{N}(s_{t|t},\Sigma_{t|t})
$$
然后在下一个状态上的分布也是一个高斯分布:
$$
s_{t+1}|y_1,\dots,y_t\sim \mathcal{N}(s_{t+1|t},\Sigma_{t+1|t})
$$
其中有:
$$
\begin{cases}
s_{t+1|t}&= A\cdot s_{t|t}\
\Sigma_{t+1|t} &= A\cdot \Sigma_{t|t}\cdot A^T+\Sigma_s
\end{cases}
$$
更新步骤 给定了$s_{t+1|t}$和$\Sigma_{t+1|t}$,则有:
$$
s_{t+1}|y_1,\dots,y_t\sim \mathcal{N}(s_{t+1|t},\Sigma_{t+1|t})
$$
可以证明有:
$$
s_{t+1}|y_1,\dots,y_{t+1}\sim \mathcal{N}(s_{t+1|t+1},\Sigma_{t+1|t+1})
$$
其中有:
$$
\begin{cases}
s_{t+1|t+1}&= s_{t+1|t}+K_t(y_{t+1}-Cs_{t+1|t})\
\Sigma_{t+1|t+1} &=\Sigma_{t+1|t}-K_t\cdot C\cdot \Sigma_{t+1|t}
\end{cases}
$$
上式中的
$$
K_t:= \Sigma_{t+1|t} C^T (C \Sigma_{t+1|t} C^T + \Sigma_y)^{-1}
$$
这个矩阵$K_t$就叫做卡尔曼增益(Kalman gain)。
现在如果我们仔细看看方程就会发现根本不需要对时间步骤 $t$ 有观测先验。更新步骤只依赖与前面的分布。综合到一起,这个算法最开始向前运行传递计算$K_t,\Sigma_{t|t},s_{t|t}$(有时候在文献中被称为$\hat s$)。然后就向后运行(进行LQR更新)来计算变量$\Phi_t,\Psi_t,L_t$了,最终就得到了最优策略$a^*t=L_Ts{t|t}$。
CS229 Supplementary notes
表示函数
1. 广义损失函数
基于我们对监督学习的理解可知学习步骤:
- $(1)$选择问题的表示形式,
- $(2)$选择损失函数,
- $(3)$最小化损失函数。
让我们考虑一个稍微通用一点的监督学习公式。在我们已经考虑过的监督学习设置中,我们输入数据$x \in \mathbb{R}^{n}$和目标$y$来自空间$\mathcal{Y}$。在线性回归中,相应的$y \in \mathbb{R}$,即$\mathcal{Y}=\mathbb{R}$。在logistic回归等二元分类问题中,我们有$y \in \mathcal{Y}={-1,1}$,对于多标签分类问题,我们对于分类数为$k$的问题有$y \in \mathcal{Y}={1,2, \ldots, k}$。
对于这些问题,我们对于某些向量$\theta$基于$\theta^Tx$做了预测,我们构建了一个损失函数$\mathrm{L} : \mathbb{R} \times \mathcal{Y} \rightarrow \mathbb{R}$,其中$\mathrm{L}\left(\theta^{T} x, y\right)$用于测量我们预测$\theta^Tx$时的损失,对于logistic回归,我们使用logistic损失函数:
$$
\mathrm{L}(z, y)=\log \left(1+e^{-y z}\right) \text { or } \mathrm{L}\left(\theta^{T} x, y\right)=\log \left(1+e^{-y \theta^{T} x}\right)
$$
对于线性回归,我们使用平方误差损失函数:
$$
\mathrm{L}(z, y)=\frac{1}{2}(z-y)^{2} \quad \text { or } \quad \mathrm{L}\left(\theta^{T} x, y\right)=\frac{1}{2}\left(\theta^{T} x-y\right)^{2}
$$
对于多类分类,我们有一个小的变体,其中我们对于$\theta_{i} \in \mathbb{R}^{n}$来说令$\Theta=\left[\theta_{1} \cdots \theta_{k}\right]$,并且使用损失函数$\mathrm{L} : \mathbb{R}^{k} \times{1, \ldots, k} \rightarrow \mathbb{R}$:
$$
\mathrm{L}(z, y)=\log \left(\sum_{i=1}^{k} \exp \left(z_{i}-z_{y}\right)\right) \operatorname{or} \mathrm{L}\left(\Theta^{T} x, y\right)=\log \left(\sum_{i=1}^{k} \exp \left(x^{T}\left(\theta_{i}-\theta_{y}\right)\right)\right)
$$
这个想法是我们想要对于所有$i \neq k$得到$\theta_{y}^{T} x>\theta_{i}^{T}$。给定训练集合对$\left{x^{(i)}, y^{(i)}\right}$,通过最小化下面式子的经验风险来选择$\theta$:
$$
J(\theta)=\frac{1}{m} \sum_{i=1}^{m} L\left(\theta^{T} x^{(i)}, y^{(i)}\right)\qquad\qquad(1)
$$
2 表示定理
让我们考虑一个稍微不同方法来选择$\theta$使得等式$(1)$中的风险最小化。在许多情况下——出于我们将在以后的课程中学习更多的原因——将正则化添加到风险$J$中是很有用的。我们添加正则化的原因很多:通常它使问题$(1)$容易计算出数值解,它还可以让我们使得等式$(1)$中的风险最小化而选择的$\theta$够推广到未知数据。通常,正则化被认为是形式$r(\theta)=|\theta|$ 或者 $r(\theta)=|\theta|^{2}$其中$|\cdot|$是$\mathbb{R}^{n}$中的范数。最常用的正则化是$l_2$-正则化,公式如下:
$$
r(\theta)=\frac{\lambda}{2}|\theta|_{2}^{2}
$$
其中$|\theta|_{2}=\sqrt{\theta^{T} \theta}$被称作向量$\theta$的欧几里得范数或长度。基于此可以得到正规化风险:
$$
J_{\lambda}(\theta)=\frac{1}{m} \sum_{i=1}^{m} \mathrm{L}\left(\theta^{T} x^{(i)}, y^{(i)}\right)+\frac{\lambda}{2}|\theta|_{2}^{2}\qquad\qquad(2)
$$
让我们考虑使得等式$(2)$中的风险最小化而选择的$\theta$的结构。正如我们通常做的那样,我们假设对于每一个固定目标值$y \in \mathcal{Y}$,函数$\mathrm{L}(z, y)$是关于$z$的凸函数。(这是线性回归、二元和多级逻辑回归的情况,以及我们将考虑的其他一些损失。)结果表明,在这些假设下,我们总是可以把问题$(2)$的解写成输入变量$x^{(i)}$的线性组合。更准确地说,我们有以下定理,称为表示定理。
定理2.1 假设在正规化风险$(2)$的定义中有$\lambda\ge 0$。然后,可以得到令正则化化风险$(2)$最小化的式子:
$$
\theta=\sum_{i=1}^{m} \alpha_{i} x^{(i)}
$$
其中$\alpha_i$为一些实值权重。
证明 为了直观,我们给出了在把$\mathrm{L}(x,y)$看做关于$z$的可微函数,并且$\lambda>0$的情况下结果的证明。详情见附录A,我们给出了定理的一个更一般的表述以及一个严格的证明。
令$\mathrm{L}^{\prime}(z, y)=\frac{\partial}{\partial z} L(z, y)$代表损失函数关于$z$的导致。则根据链式法则,我们得到了梯度恒等式:
$$
\nabla_{\theta} \mathrm{L}\left(\theta^{T} x, y\right)=\mathrm{L}^{\prime}\left(\theta^{T} x, y\right) x \text { and } \nabla_{\theta} \frac{1}{2}|\theta|_{2}^{2}=\theta
$$
其中$\nabla_{\theta}$代表关于$\theta$的梯度。由于风险在所有固定点(包括最小值点)的梯度必须为$0$,我们可以这样写:
$$
\nabla J_{\lambda}(\theta)=\frac{1}{m} \sum_{i=1}^{m} \mathrm{L}^{\prime}\left(\theta^{T} x^{(i)}, y^{(i)}\right) x^{(i)}+\lambda \theta=\overrightarrow{0}
$$
特别的,令$w_{i}=\mathrm{L}^{\prime}\left(\theta^{T} x^{(i)}, y^{(i)}\right)$,因为$\mathrm{L}^{\prime}\left(\theta^{T} x^{(i)}, y^{(i)}\right)$是一个标量(依赖于$\theta$,但是无论$\theta$是多少,$w_i$始终是一个实数),所以我们有:
$$
\theta=-\frac{1}{\lambda} \sum_{i=1}^{n} w_{i} x^{(i)}
$$
设$\alpha_{i}=-\frac{w_{i}}{\lambda}$以得到结果。
3 非线性特征与核
基于表示定理$2.1$我们看到,我们可以写出向量$\theta$的作为数据$\left{x^{(i)}\right}_{i=1}^{m}$的线性组合。重要的是,这意味着我们总能做出预测:
$$
\theta^{T} x=x^{T} \theta=\sum_{i=1}^{m} \alpha_{i} x^{T} x^{(i)}
$$
也就是说,在任何学习算法中,我们都可以将$\theta^{T} x$替换成$\sum_{i=1}^{m} \alpha_{i} x^{(i)^{T}}x$,然后直接通过$\alpha \in \mathbb{R}^{m}$使其最小化。
让我们从更普遍的角度来考虑这个问题。在我们讨论线性回归时,我们遇到一个问题,输入$x$是房子的居住面积,我们考虑使用特征$x$,$x^2$和$x^3$(比方说)来进行回归,得到一个三次函数。为了区分这两组变量,我们将“原始”输入值称为问题的输入属性(在本例中,$x$是居住面积)。当它被映射到一些新的量集,然后传递给学习算法时,我们将这些新的量称为输入特征。(不幸的是,不同的作者使用不同的术语来描述这两件事,但是我们将在本节的笔记中始终如一地使用这个术语。)我们还将让$\phi$表示特征映射,映射属性的功能。例如,在我们的例子中,我们有:
$$
\phi(x)=\left[ \begin{array}{c}{x} \ {x^{2}} \ {x^{3}}\end{array}\right]
$$
与其使用原始输入属性$x$应用学习算法,不如使用一些特征$\phi(x)$来学习。要做到这一点,我们只需要回顾一下之前的算法,并将其中的$x$替换为$\phi(x)$。
因为算法可以完全用内积$\langle x, z\rangle$来表示,这意味着我们可以将这些内积替换为$\langle\phi(x), \phi(z)\rangle$。特别是给定一个特征映射$\phi$,我们可以将相应核定义为:
$$
K(x, z)=\phi(x)^{T} \phi(z)
$$
然后,在我们之前的算法中,只要有$\langle x, z\rangle$,我们就可以用$K(x, z)$替换它,并且现在我们的算法可以使用特征$\phi$来学习。让我们更仔细地写出来。我们通过表示定理(定理2.1)看到我们可以对于一些权重$\alpha_i$写出$\theta=\sum_{i=1}^{m} \alpha_{i} \phi\left(x^{(i)}\right)$。然后我们可以写出(正则化)风险:
$$
\begin{aligned}
J_{\lambda}(\theta)
&=J_{\lambda}(\alpha) \
&=\frac{1}{m} \sum_{i=1}^{m} L\left(\phi\left(x^{(i)}\right)^{T} \sum_{j=1}^{m} \alpha_{j} \phi\left(x^{(j)}\right), y^{(i)}\right)+\frac{\lambda}{2}\left|\sum_{i=1}^{m} \alpha_{i} \phi\left(x^{(i)}\right)\right|{2}^{2} \
&=\frac{1}{m} \sum{i=1}^{m} L\left(\sum_{j=1}^{m} \alpha_{j} \phi\left(x^{(i)}\right)^{T} \phi\left(x^{(j)}\right), y^{(i)}\right)+\frac{\lambda}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} \phi\left(x^{(i)}\right)^{T} \phi\left(x^{(j)}\right) \
&=\frac{1}{m} \sum_{i=1}^{m} \mathrm{L}\left(\sum_{j=1}^{m} \alpha_{j} K\left(x^{(i)}, x^{(j)}\right)+\frac{\lambda}{2} \sum_{i, j} \alpha_{i} \alpha_{i} K\left(x^{(i)}, x^{(j)}\right)\right.
\end{aligned}
$$
也就是说,我们可以把整个损失函数写成核矩阵的最小值:
$$
K=\left[K\left(x^{(i)}, x^{(j)}\right)\right]_{i, j=1}^{m} \in \mathbb{R}^{m \times m}
$$
现在,给定$\phi$,我们可以很容易地通过$\phi(x)$和$\phi(z)$和内积计算$K(x,z)$。但更有趣的是,通常$K(x,z)$可能非常廉价的计算,即使$\phi(x)$本身可能是非常难计算的(可能因为这是一个极高维的向量)。在这样的设置中,通过在我们的算法中一个有效的方法来计算$K(x,z)$,我们可以学习的高维特征空间空间由$\phi$给出,但没有明确的找到或表达向量$\phi(x)$。例如,一些核(对应于无限维的向量$\phi$)包括:
$$
K(x, z)=\exp \left(-\frac{1}{2 \tau^{2}}|x-z|_{2}^{2}\right)
$$
称为高斯或径向基函数(RBF)核,适用于任何维数的数据,或最小核(适用于$x\in R$)由下式得:
$$
K(x, z)=\min {x, z}
$$
有关这些内核机器的更多信息,请参见支持向量机(SVMs)的课堂笔记。
4 核机器学习的随机梯度下降算法
如果我们定义$K \in \mathbb{R}^{m \times m}$为核矩阵,简而言之,定义向量:
$$
K^{(i)}=\left[ \begin{array}{c}{K\left(x^{(i)}, x^{(1)}\right)} \ {K\left(x^{(i)}, x^{(2)}\right)} \ {\vdots} \ {K\left(x^{(i)}, x^{(m)}\right)}\end{array}\right]
$$
其中$K=\left[K^{(1)} K^{(2)} \cdots K^{(m)}\right]$,然后,我们可以将正则化风险写成如下简单的形式:
$$
J_{\lambda}(\alpha)=\frac{1}{m} \sum_{i=1}^{m} \mathrm{L}\left(K^{(i)^{T}} \alpha, y^{(i)}\right)+\frac{\lambda}{2} \alpha^{T} K \alpha
$$
现在,让我们考虑对上述风险$J_{\lambda}$取一个随机梯度。也就是说,我们希望构造一个(易于计算的)期望为$\nabla J_{\lambda}(\alpha)$的随机向量,其没有太多的方差。为此,我们首先计算$J(\alpha)$的梯度。我们通过下式来计算单个损失项的梯度:
$$
\nabla_{\alpha} \mathrm{L}\left(K^{(i)^{T}} \alpha, y^{(i)}\right)=\mathrm{L}^{\prime}\left(K^{(i)^{T}} \alpha, y^{(i)}\right) K^{(i)}
$$
而:
$$
\nabla_{\alpha}\left[\frac{\lambda}{2} \alpha^{T} K \alpha\right]=\lambda K \alpha=\lambda \sum_{i=1}^{m} K^{(i)} \alpha_{i}
$$
因此我们可得:
$$
\nabla_{\alpha} J_{\lambda}(\alpha)=\frac{1}{m} \sum_{i=1}^{m} \mathrm{L}^{\prime}\left(K^{(i)^{T}} \alpha, y^{(i)}\right) K^{(i)}+\lambda \sum_{i=1}^{m} K^{(i)} \alpha_{i}
$$
因此,如果我们选择一个随机索引 ,我们有下式:
$$
\mathrm{L}^{\prime}\left(K^{(i)^{T}} \alpha, y^{(i)}\right) K^{(i)}+m \lambda K^{(i)} \alpha_{i}
$$
上式是关于$J_{\lambda}(\alpha)$的随机梯度。这给我们一个核监督学习问题的随机梯度算法,如图$1$所示。关于算法$1$,有一点需要注意:因为我们为了保持梯度的无偏性而在$\lambda K^{(i)} \alpha_{i}$项上乘了$m$,所以参数$\lambda>0$不能太大,否则算法就会有点不稳定。此外,通常选择的步长是$\eta_{t}=1 / \sqrt{t}$,或者是它的常数倍。

5 支持向量机
现在我们讨论支持向量机(SVM)的一种方法,它适用于标签为$y \in{-1,1}$的二分类问题。并给出了损失函数$\mathrm{L}$的一种特殊选择,特别是在支持向量机中,我们使用了基于边缘的损失函数:
$$
\mathrm{L}(z, y)=[1-y z]_{+}=\max {0,1-y z}\qquad\qquad(3)
$$
因此,在某种意义上,支持向量机只是我们前面描述的一般理论结果的一个特例。特别的,我们有经验正则化风险:
$$
J_{\lambda}(\alpha)=\frac{1}{m} \sum_{i=1}^{m}\left[1-y^{(i)} K^{(i)^{T}} \alpha\right]_{+}+\frac{\lambda}{2} \alpha^{T} K \alpha
$$
其中矩阵$K=\left[K^{(1)} \cdots K^{(m)}\right]$通过$K_{i j}=K\left(x^{(i)}, x^{(j)}\right)$来定义。
在课堂笔记中,你们可以看到另一种推导支持向量机的方法以及我们为什么称呼其为支持向量机的描述。
6 一个例子
在本节中,我们考虑一个特殊的例子——核,称为高斯或径向基函数(RBF)核。这个核由下式给出:
$$
K(x, z)=\exp \left(-\frac{1}{2 \tau^{2}}|x-z|_{2}^{2}\right)\qquad\qquad(4)
$$
其中$\tau>0$是一个控制内核带宽的参数。直观地,当$\tau$非常小时,除非$x \approx z$我们将得到$K(x, z) \approx 0$。即$x$和$z$非常接近,在这种情况下我们有$K(x, z) \approx 1$。然而,当$\tau$非常大时,则我们有一个更平滑的核函数$K$。这个核的功能函数$\phi$是在无限维$^1$的空间中。即便如此,通过考虑一个新的例子$x$所做的分类,我们可以对内核有一些直观的认识:我们预测:
上一小段上标1的说明(详情请点击本行)
如果你看过特征函数或者傅里叶变换,那么你可能会认出RBF核是均值为零,方差为$\tau^{2}$的高斯分布的傅里叶变换。也就是在$\mathbb{R}^{n}$中令$W\sim \mathrm{N}\left(0, \tau^{2} I_{n \times n}\right)$,使得$W$的概率密函数为$p(w)=\frac{1}{\left(2 \pi \tau^{2}\right)^{n / 2}} \exp \left(-\frac{|w|_{2}^{2}}{2 \tau^{2}}\right)$。令$i=\sqrt{-1}$为虚数单位,则对于任意向量$v$我们可得:
$$
\begin{aligned}
\mathbb{E}\left[\exp \left(i v^{T} W\right)\right]
=\int \exp \left(i v^{T} w\right) p(w) d w
&=\int \frac{1}{\left(2 \pi \tau^{2}\right)^{n / 2}} \exp \left(i v^{T} w-\frac{1}{2 \tau^{2}}|w|{2}^{2}\right) d w \
&=\exp \left(-\frac{1}{2 \tau^{2}}|v|{2}^{2}\right)
\end{aligned}
$$因此,如果我们定义“向量”(实际上是函数)$\phi(x, w)=e^{i x^{T} w}$并令$a^*$是$a \in \mathbb{C}$的共轭复数,则我们可得:
$$
\mathbb{E}\left[\phi(x, W) \phi(z, W)^{*}\right]=\mathbb{E}\left[e^{i x^{T} W} e^{-i x^{T} W}\right]=\mathbb{E}\left[\exp \left(i W^{T}(x-z)\right)\right]=\exp \left(-\frac{1}{2 \tau^{2}}|x-z|_{2}^{2}\right)
$$特别地,我们看到$K(x, z)$是一个函数空间的内积这个函数空间可以对$p(w)$积分。
$$
\sum_{i=1}^{m} K\left(x^{(i)}, x\right) \alpha_{i}=\sum_{i=1}^{m} \exp \left(-\frac{1}{2 \tau^{2}}\left|x^{(i)}-x\right|{2}^{2}\right) \alpha{i}
$$
所以这就变成了一个权重,取决于$x$离每个$x^{(i)}$有多近,权重的贡献$\alpha_i$乘以$x$到$x^{(i)}$的相似度,由核函数决定。
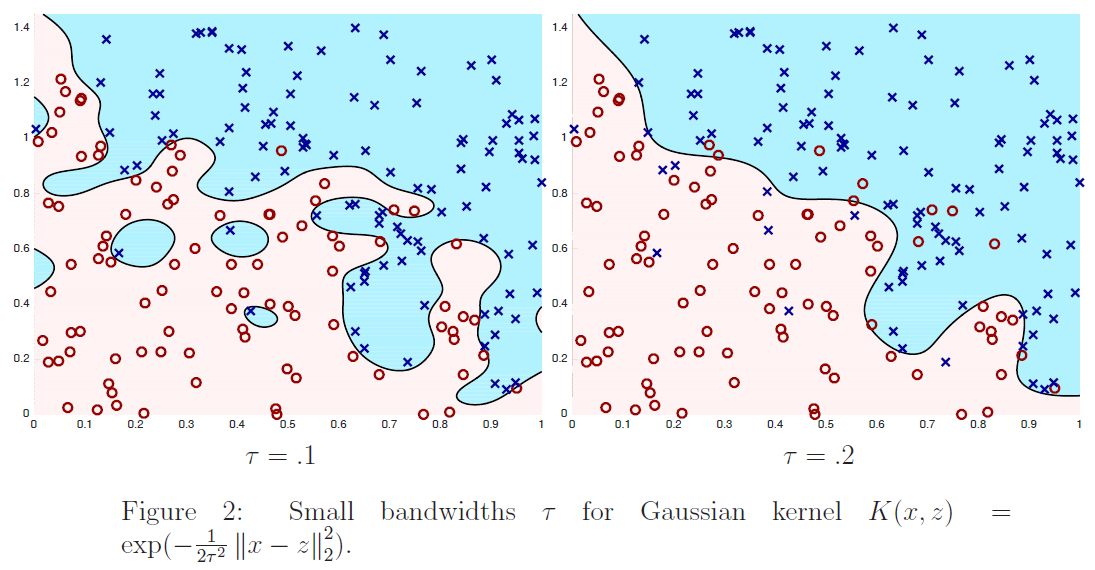
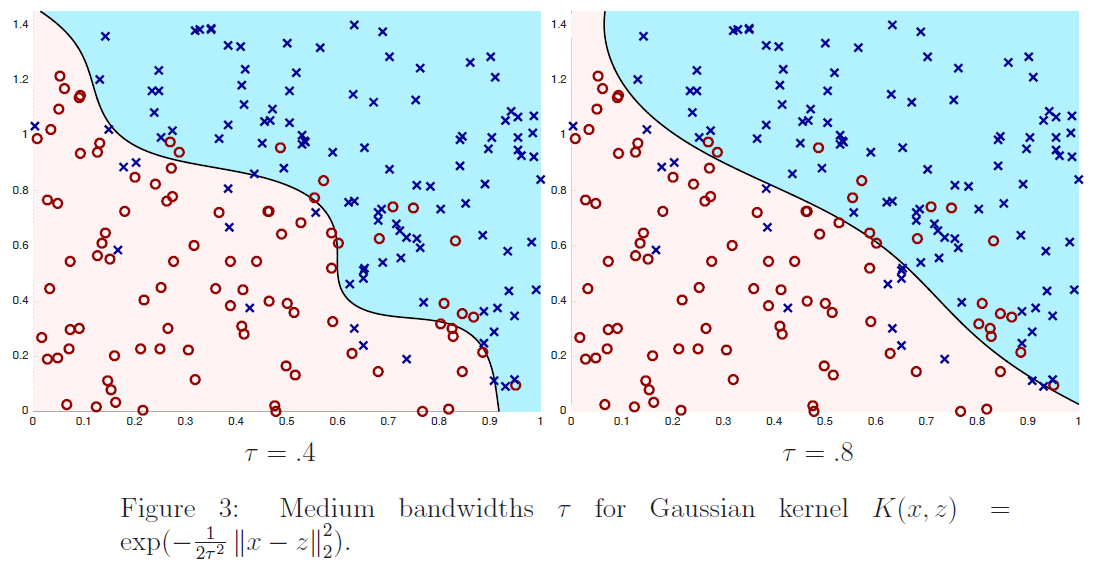
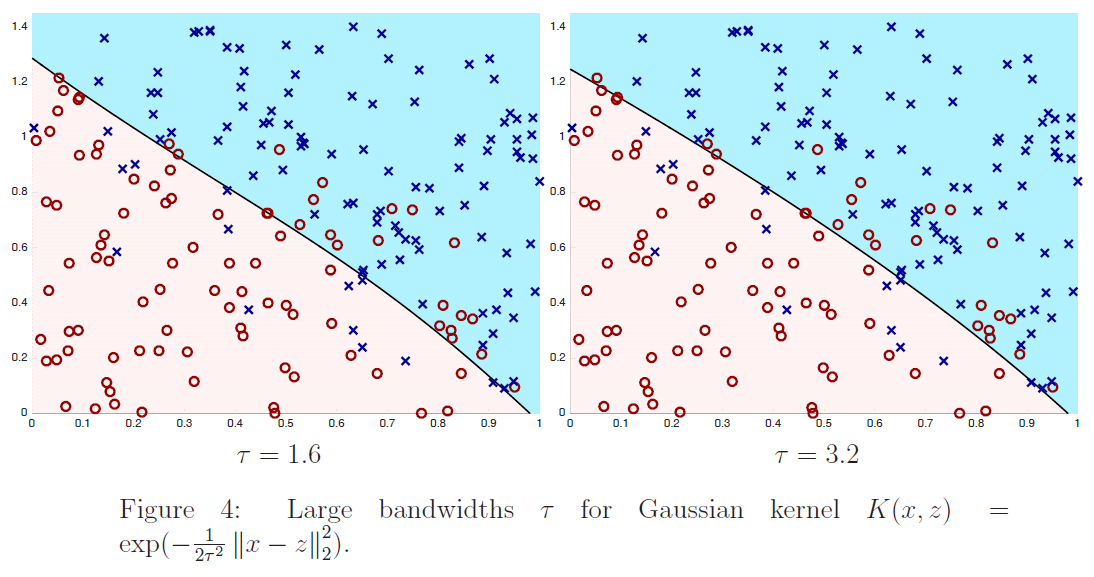
在图$2$、$3$和$4$中,我们通过最小化下式显示了训练$6$个不同内核分类器的结果:
$$
J_{\lambda}(\alpha)=\sum_{i=1}^{m}\left[1-y^{(i)} K^{(i)^{T}} \alpha\right]_{+}+\frac{\lambda}{2} \alpha^{T} K \alpha
$$
其中$m=200,\lambda=1/m$,核公式$(4)$中的$\tau$取不同的值。我们绘制了训练数据(正例为蓝色的x,负例为红色的o)以及最终分类器的决策面。也就是说,我们画的线由下式:
$$
\left{x \in \mathbb{R}^{2} : \sum_{i=1}^{m} K\left(x, x^{(i)}\right) \alpha_{i}=0\right}
$$
定义给出了学习分类器进行预测$\sum_{i=1}^{m} K\left(x, x^{(i)}\right) \alpha_{i}>0$和$\sum_{i=1}^{m} K\left(x, x^{(i)}\right) \alpha_{i}<0$的区域。从图中我们看到,对于数值较大的$\tau$的一个非常简单的分类器:它几乎是线性的,而对于$τ=.1$,分类器有实质性的变化,是高度非线性的。为了便于参考,在图$5$中,我们根据训练数据绘制了最优分类器;在训练数据无限大的情况下,最优分类器能最大限度地减小误分类误差。
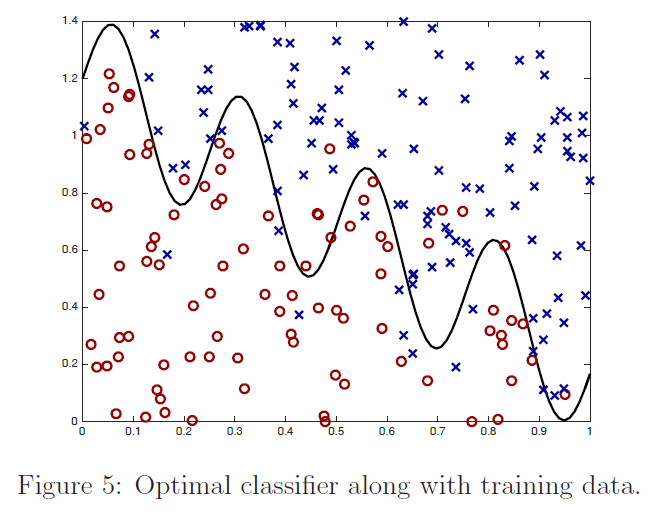
A 一个更一般的表示定理
在这一节中,我们给出了一个更一般版本的表示定理以及一个严格的证明。令$r : \mathbb{R} \rightarrow \mathbb{R}$为任何非降函数的自变量,并考虑正则化风险:
$$
J_{r}(\theta)=\frac{1}{m} \sum_{i=1}^{m} \mathrm{L}\left(x^{(i)^{T}} \theta, y^{(i)}\right)+r\left(|\theta|_{2}\right)\qquad\qquad(5)
$$
通常,我们取$r(t)=\frac{\lambda}{2} t^{2}$,与通常的选择$l_2$-正则化相对应。但是下一个定理表明这对于表示定理来说是不必要的。事实上,我们可以对所有的$t$取$r(t) = 0$,这个定理仍然成立。
定理 A.1 (向量空间$R^n$中的表示定理)。令$\theta \in \mathbb{R}^{n}$为任意向量。则存在$\alpha \in \mathbb{R}^{m}$和$\theta^{(\alpha)}=\sum_{i=1}^{m} \alpha_{i} x^{(i)}$使得:
$$
J_{r}\left(\theta^{(\alpha)}\right) \leq J_{r}(\theta)
$$
特别的,没有普遍的损失函数总是假设我们可以最小化$J(\theta)$来写出优化问题,其中最小化$J(\theta)$时仅仅考虑$\theta$在数据的张成的空间中的情况。
证明 我们的证明依赖于线性代数中的一些性质,它允许我们证明简洁,但是如果你觉得太过简洁,请随意提问。
向量$\left{x^{(i)}\right}_{i=1}^{m}$在向量空间$\mathbb{R}^{n}$中。因此有$\mathbb{R}^{n}$中的子空间$V$使得:
$$
V=\left{\sum_{i=1}^{m} \beta_{i} x^{(i)} : \beta_{i} \in \mathbb{R}\right}
$$
那么$V$对于向量$v_{i} \in \mathbb{R}^{n}$有一个标准正交基$\left{v_{1}, \dots, v_{n_{0}}\right}$,其中标准正交基的长度(维度)是$n_{0} \leq n$。因此我们可以写出$V=\left{\sum_{i=1}^{n_{0}} b_{i} v_{i}:b_{i} \in \mathbb{R} \right}$,回忆一下正交性是是指向量$v_i$满足$\left|v_{i}\right|{2}=1$和对于任意$i\neq j$有$v{i}^{T} v_{j}=0$。还有一个正交子空间$V^{\perp}=\left{u \in \mathbb{R}^{n} : u^{T} v=0\quad for\quad all\quad v \in V\right}$,其有一个维度是$n_{\perp}=n-n_{0} \geq 0$的正交基,我们可以写作$\left{u_{1}, \ldots, u_{n_{\perp}}\right} \subset \mathbb{R}^{n}$,其对于所有$i,j$都满足$u_{i}^{T} v_{j}=0$。
因为$\theta \in \mathbb{R}^{n}$,我们可以把它唯一地写成:
$$
\theta=\sum_{i=1}^{n_{0}} \nu_{i} v_{i}+\sum_{i=1}^{n_{\perp}} \mu_{i} u_{i}, \quad \text { where } \nu_{i} \in \mathbb{R} \text { and } \mu_{i} \in \mathbb{R}
$$
其中$\mu, \nu$的值是唯一的。现在通过$\left{x^{(i)}\right}_{i=1}^{m}$张成的空间$V$的定义可知,存在$\alpha \in \mathbb{R}^{m}$使得:
$$
\sum_{i=1}^{n_{0}} \nu_{i} v_{i}=\sum_{i=1}^{m} \alpha_{i} x^{(i)}
$$
因此我们有:
$$
\theta=\sum_{i=1}^{m} \alpha_{i} x^{(i)}+\sum_{i=1}^{n_{\perp}} \mu_{i} u_{i}
$$
定义$\theta^{(\alpha)}=\sum_{i=1}^{m} \alpha_{i} x^{(i)}$。现在对于任意数据点$x^{(j)}$,我们有:
$$
u_{i}^{T} x^{(j)}=0 \text { for all } i=1, \ldots, n_{\perp}
$$
使得$u_{i}^{T} \theta^{(\alpha)}=0$。因此我们可得:
$$
|\theta|{2}^{2}=\left|\theta^{(\alpha)}+\sum{i=1}^{n_{\perp}} \mu_{i} u_{i}\right|{2}^{2}=\left|\theta^{(\alpha)}\right|{2}^{2}+\underbrace{2 \sum_{i=1}^{n_{\perp}} \mu_{i} u_{i}^{T} \theta^{(\alpha)}}{=0}+\left|\sum{i=1}^{n_{\perp}} \mu_{i} u_{i}\right|{2}^{2} \geq\left|\theta^{(\alpha)}\right|{2}^{2}\quad(6a)
$$
同时我们可得:
$$
\theta^{(\alpha)^{T}} x^{(i)}=\theta^{T} x^{(i)}\qquad\qquad(6b)
$$
对于所有点$x^{(i)}$都成立。
即,通过使用$|\theta|{2} \geq\left|\theta^{(\alpha)}\right|{2}$以及等式$(6b)$,我们可得:
$$
\begin{aligned}
J_{r}(\theta)=\frac{1}{m} \sum_{i=1}^{m} \mathrm{L}\left(\theta^{T} x^{(i)}, y^{(i)}\right)+r\left(|\theta|{2}\right) &\stackrel{(6 \mathrm{b})}{=} \frac{1}{m} \sum{i=1}^{m} \mathrm{L}\left(\theta^{(\alpha)^{T}} x^{(i)}, y^{(i)}\right)+r\left(|\theta|{2}\right)\
&\stackrel{(6 \mathrm{a})}{ \geq} \frac{1}{m} \sum{i=1}^{m} \mathrm{L}\left(\theta^{(\alpha)^{T}} x^{(i)}, y^{(i)}\right)+r\left(\left|\theta^{(\alpha)}\right|{2}\right)\
&=J{r}\left(\theta^{(\alpha)}\right)
\end{aligned}
$$
这是期望的结果。